爬取知乎某个问题下所有的图片
Posted 总是空大
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取知乎某个问题下所有的图片相关的知识,希望对你有一定的参考价值。
最近在逛知乎时,看到这么一个问题

最高赞的答案写了个爬虫,把所有的照片都爬下来了。
嘿嘿嘿,技术的力量

正好自己也在学习,加上答主的答案是很久之前的,知乎已经改版了,所以决定自己用Python3写一个练习一下(绝对不是为了下照片)....

设个小小的目标:爬取所有“女性”程序员的照片。
首先是要知道“总的回答数”,这个比较简单:
url="https://www.zhihu.com/question/37787176"
html=requests.get(url,headers=headers).text
answer=BeautifulSoup(html,"lxml").find("h4",class_="List-headerText").find("span").get_text()
answer_num=int(re.sub("\\s\\S+","",answer))
知乎加载内容是通过点击“更多”,然后加载出20个回答,利用selenium模拟登陆太慢太麻烦,所有查看知乎的Ajax请求比较靠谱,此处感谢崔大神的教学(http://cuiqingcai.com/4380.html)。
通过浏览器,可以看到每次点击更多,请求内容是一个“fetch”类型的文件和相关的图片(jpeg),这个"fetch"文件包含了回答者信息和回答内容
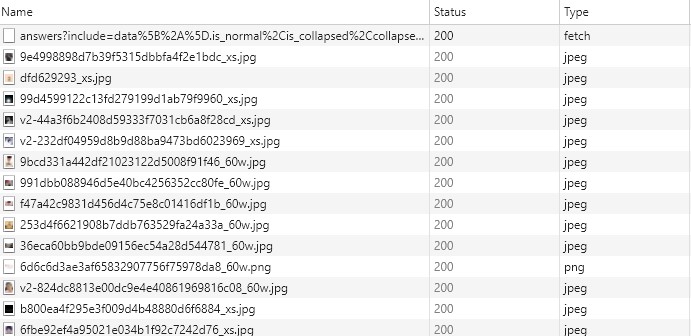
通过json处理后,通过gender判断回答者性别(0为女,1为男)。
抓取“content”下的所有src属性的图片链接,就搞定了。
附注:请求头要加一个"authorization"

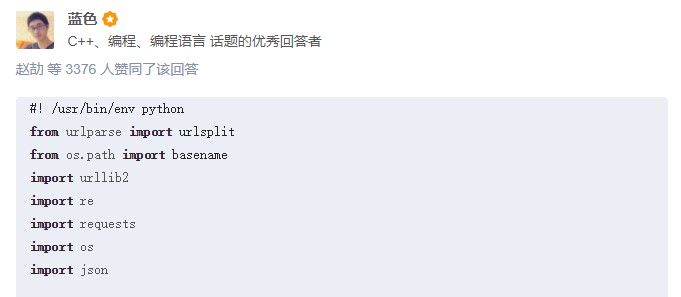
下面是全代码:
import requests
import os
import json
from bs4 import BeautifulSoup
import re
import time
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36\',
"Connection": "keep - alive",
"Accept": "text/html,application/xhtml+xml,application/xml;",
"authorization": "Bearer Mi4wQUFEQVB4VkNBQUFBVU1MWktySDJDeGNBQUFCaEFsVk5TZ0YyV1FBaGsxRnJlTFd3ZGR6QzZrTXptcDFuWGNOQk5B|1498313802|2d5466ef4550588f5fc28553ea8981e7a4e398ad"
}
isExists = os.path.exists("D:/crawler_study/zhihu")
if not isExists:
os.makedirs("D:/crawler_study/zhihu")
os.chdir("D:/crawler_study/zhihu")
else:
os.chdir("D:/crawler_study/zhihu")
url="https://www.zhihu.com/question/37787176"
html=requests.get(url,headers=headers).text
answer=BeautifulSoup(html,"lxml").find("h4",class_="List-headerText").find("span").get_text()
answer_num=int(re.sub("\\s\\S+","",answer))
url_prefix="https://www.zhihu.com/api/v4/questions/37787176/answers?sort_by=default&include=data%5B%2A%5D.is_normal%2Cis_collapsed%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Cmark_infos%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cupvoted_followees%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics&limit=20&offset="
offset=0
while offset < answer_num:
answer_url=url_prefix+str(offset)
html=requests.get(answer_url,headers=headers).text
content=json.loads(html)["data"]
for row in content:
gender=row["author"]["gender"]
if gender == 0:
answer=row["content"]
pic_list=BeautifulSoup(answer,\'lxml\').find_all("img")
for pic in pic_list:
down_url=pic["src"]
if down_url.startswith("http"):
name=re.sub(".*/","",down_url)
file=open(name,"ab")
print("开始下载:",name)
file.write(requests.get(down_url).content)
print("下载完:", name)
file.close()
else:
pass
offset+=20
time.sleep(3)
以上是关于爬取知乎某个问题下所有的图片的主要内容,如果未能解决你的问题,请参考以下文章