hadoop中怎么创建文件夹
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop中怎么创建文件夹相关的知识,希望对你有一定的参考价值。
创建test文件夹hadoop fs -mkdir /test
查看文件夹
hadoop fs -ls /test
删除文件夹命令rmr,删除文件命令rm 参考技术A 创建单个文件夹:
hadoop fs -mkdir 文件夹在集群中的路径/文件夹名
创建多个文件夹嵌套,
hadoop fs -mkdir -p 文件夹在集群中的路径/最外面文件夹名/第二层文件夹名/以此类推
如何运行自带wordcount-Hadoop2
参考技术A1.找到examples例子
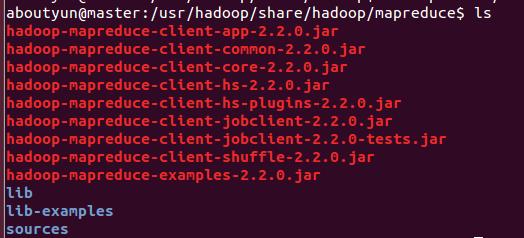
我们需要找打这个例子的位置:首先需要找到你的hadoop文件夹,然后依照下面路径:
/hadoop/share/hadoop/mapreduce会看到如下图:
hadoop-mapreduce-examples-2.2.0.jar
第二步:
我们需要需要做一下运行需要的工作,比如输入输出路径,上传什么文件等。
1.先在HDFS创建几个数据目录:
hadoop fs -mkdir -p /data/wordcount
hadoop fs -mkdir -p /output/
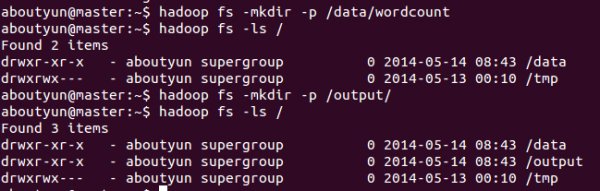
2.目录/data/wordcount用来存放Hadoop自带的WordCount例子的数据文件,运行这个MapReduce任务的结果输出到/output/wordcount目录中。
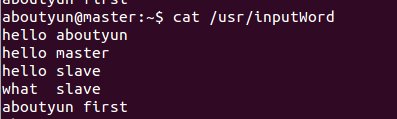
首先新建文件inputWord:
vi /usr/inputWord
新建完毕,查看内容:
cat /usr/inputWord
将本地文件上传到HDFS中:
hadoop fs -put /usr/inputWord /data/wordcount/
可以查看上传后的文件情况,执行如下命令:
hadoop fs -ls /data/wordcount
可以看到上传到HDFS中的文件。

通过命令
hadoop fs -text /data/wordcount/inputWord
看到如下内容:
下面,运行WordCount例子,执行如下命令:
hadoop jar /usr/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /data/wordcount /output/wordcount

可以看到控制台输出程序运行的信息:
14/05/14 10:33:33 INFO client.RMProxy: Connecting to ResourceManager at master/172.16.77.15:8032
14/05/14 10:33:34 INFO input.FileInputFormat: Total input paths to process : 1
14/05/14 10:33:34 INFO mapreduce.JobSubmitter: number of splits:1
14/05/14 10:33:34 INFO Configuration.deprecation: user.name is deprecated. Instead, use mapreduce.job.user.name
14/05/14 10:33:34 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
14/05/14 10:33:34 INFO Configuration.deprecation: mapred.output.value.class is deprecated. Instead, use mapreduce.job.output.value.class
14/05/14 10:33:34 INFO Configuration.deprecation: mapreduce.combine.class is deprecated. Instead, use mapreduce.job.combine.class
14/05/14 10:33:34 INFO Configuration.deprecation: mapreduce.map.class is deprecated. Instead, use mapreduce.job.map.class
14/05/14 10:33:34 INFO Configuration.deprecation: mapred.job.name is deprecated. Instead, use mapreduce.job.name
14/05/14 10:33:34 INFO Configuration.deprecation: mapreduce.reduce.class is deprecated. Instead, use mapreduce.job.reduce.class
14/05/14 10:33:34 INFO Configuration.deprecation: mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir
14/05/14 10:33:34 INFO Configuration.deprecation: mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir
14/05/14 10:33:34 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
14/05/14 10:33:34 INFO Configuration.deprecation: mapred.output.key.class is deprecated. Instead, use mapreduce.job.output.key.class
14/05/14 10:33:34 INFO Configuration.deprecation: mapred.working.dir is deprecated. Instead, use mapreduce.job.working.dir
14/05/14 10:33:35 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1400084979891_0004
14/05/14 10:33:36 INFO impl.YarnClientImpl: Submitted application application_1400084979891_0004 to ResourceManager at master/172.16.77.15:8032
14/05/14 10:33:36 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1400084979891_0004/
14/05/14 10:33:36 INFO mapreduce.Job: Running job: job_1400084979891_0004
14/05/14 10:33:45 INFO mapreduce.Job: Job job_1400084979891_0004 running in uber mode : false
14/05/14 10:33:45 INFO mapreduce.Job: map 0% reduce 0%
14/05/14 10:34:10 INFO mapreduce.Job: map 100% reduce 0%
14/05/14 10:34:19 INFO mapreduce.Job: map 100% reduce 100%
14/05/14 10:34:19 INFO mapreduce.Job: Job job_1400084979891_0004 completed successfully
14/05/14 10:34:20 INFO mapreduce.Job: Counters: 43
File System Counters
FILE: Number of bytes read=81
FILE: Number of bytes written=158693
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=175
HDFS: Number of bytes written=51
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=23099
Total time spent by all reduces in occupied slots (ms)=6768
Map-Reduce Framework
Map input records=5
Map output records=10
Map output bytes=106
Map output materialized bytes=81
Input split bytes=108
Combine input records=10
Combine output records=6
Reduce input groups=6
Reduce shuffle bytes=81
Reduce input records=6
Reduce output records=6
Spilled Records=12
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=377
CPU time spent (ms)=11190
Physical memory (bytes) snapshot=284524544
Virtual memory (bytes) snapshot=2000748544
Total committed heap usage (bytes)=136450048
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=67
File Output Format Counters
Bytes Written=51
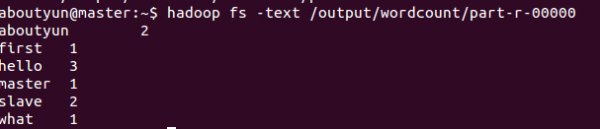
查看结果,执行如下命令:
hadoop fs -text /output/wordcount/part-r-00000
结果数据示例如下:
aboutyun@master:~$ hadoop fs -text /output/wordcount/part-r-00000
aboutyun 2
first 1
hello 3
master 1
slave 2
what 1
登录到Web控制台,访问链接http://master:8088/可以看到任务记录情况。
以上是关于hadoop中怎么创建文件夹的主要内容,如果未能解决你的问题,请参考以下文章