数据库复习之规范化理论应用(第八次上机内容)
Posted AlvinZH
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库复习之规范化理论应用(第八次上机内容)相关的知识,希望对你有一定的参考价值。
声明:本文为作者复习数据库课程时简单记录的笔记,如有错误之处,敬请指出,谢谢。
一、理论基础
1.无损连接性(Lossless Join):设关系模式R(U,F)被分解为若干个关系模式R1(U1,F1),R2(U2,F2),…, Rn(Un,Fn),其中U=U1U2…Un,且不存在UnUj式,Fi为F在Uj上的投影,如果R与R1,R2,…,Rn自然连接的结果相等,则称关系模式R的分解具有无损连接性。
(上面别看了,看下面!)
简单来说,就是如果对分解后的新关系进行自然连接得到的元组的集合与原关系完全一致,则称为无损连接。
2.函数依赖保持性(Preserve Dependency):设关系模式R(U,F)被分解为若干个关系模式R1(U1,F1),R2(U2,F2),…, Rn(Un,Fn),其中U=U1U2…UN,且不存在UNUj式,Fi为F在Uj上的投影;如果F所蕴含的任意一个函数依赖一定也由(F1 U F2 …U Fn)所蕴含,则称关系模式R的分解具有函数依赖保持性。
(概念复杂就别看了,脑壳疼)
简单来说,如果F上的每一个函数依赖都在其分解后的某一个关系上成立,则这个分解是保持函数依赖的(注意:这是一个充分条件)。
3.规范化过程既要具有无损连接性,又要具有函数依赖保持性。(仅偏一方都会有问题),前者可以保证不丢失信息,后者可以减轻或解决各种异常情况。
4.非规范化技术:有时候可以适当降低甚至抛弃关系模式的范式,提高数据库运行效率。比如经常从两个表中查询数据,为了避免频繁连接,可以适当数据冗余。
(1)表分割:水平分割,垂直分割。
(2)非规范化设计的主要优点
- 减少了查询操作所需的连接
- 减少了外部键和索引的数量
- 可以预先进行统计计算,提高了查询时的响应速度
(3)非规范化存在的主要问题
- 增加了数据冗余
- 影响数据库的完整性
- 降低了数据更新的速度
- 增加了存储表所占用的物理空间
5.闭包概念
- 属性集的闭包:给定关系R(U,F), 对F,F+中所有X→A的A的集合称为X的闭包,记为X+。
- 函数依赖的闭包: 若F为关系模式R(U)的函数依赖集,我们把F以及所有被F逻辑蕴涵的函数依赖的集合称为F的闭包,记为F+。
规定:若X为U的子集,X→Φ 属于F+。
属性集闭包的用途:
- 判断α是否为超码,通过计算α+(α在F下的闭包),看α+ 是否包含了R中的所有属性。若是,则α为R的超码。
- 通过检验是否β∈α+,来验证函数依赖是否成立。也就是说,用属性闭包计算α+,看它是否包含β。
二、例题讲述(第八次上机)
基本概念讲述:http://www.cnblogs.com/AlvinZH/p/6856298.html
解题方法要点一:判定函数依赖X→Y是否能由F导出的问题,可转化为求X+并判定Y是否是X+子集的问题。(求F闭包的问题可转化为求属性集闭包的问题)
解题方法要点二:求属性集的闭包算法:
- 将A置入A+。
- 对每一FD(函数依赖),若左部属于A+,则将右部置入A+。
- 重复至A+不能扩大。
解题方法要点三:函数依赖推理规则:
- 若XY->Z,则X->Z,Y->Z(错误)
- 若X->Y, 则XZ->YZ
- 若X->Y, X->Z,则X->YZ
- 若X->Y,Z∈Y,则X->Z
- 若X->Y,Y->Z,则X->Z
- 若X->YZ,则X->Y,X->Z
- 若A->B,BC->D,则AC->D
例1.已知某个关系,具有属性:A,B,C,D,E,F。假设该关系有函数依赖F={AB->C, BC->AD, D->E,CF->B}, 判断AB->D,D->A是否蕴含于这些函数依赖中。
解答:前者转化为求属性集AB的闭包:{A,B,C,D,E},D是其闭包的子集,所以前者蕴含于这些函数依赖中。后者求属性集D的闭包:{D,E},A不是其闭包的子集,所以后者不蕴含其中。
例2.已知关系模式R(U,F),U={A,B,C,D,E,G},F={AB->C, C->A,BC->D, ACD->B, D->EG, BE->C, CG->BD, CE->AG},判断BD->AC是否属于F+。
解答:本题换了一种问法,道理是一样:判断BD->AC成不成立。转化为求BD的闭包:{B,D,E,G,C,A},AC是其子集,所以属于。
例3.给定关系R(A1,A2,A3,A4)上的函数依赖集F={A1→A2,A3→A2,A2→A3,A2→A4},R的候选关键字为__A__。
A. A1 B. A1A3 C. A1A3A4 D. A1A2A3
解答:求候选关键字,先求哪个属性集的闭包包含所有属性(超码)。A1的闭包:{A1,A2,A3,A4},符合要求。
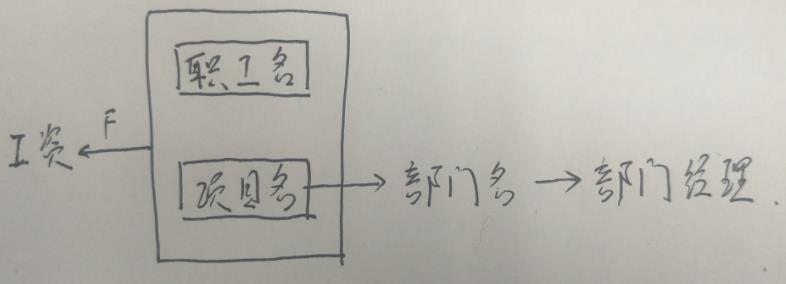
例4.设有关系模式R(职工名,项目名,工资,部门名,部门经理)。如果规定,每个职工可以参加多个项目,各领一份工资(一人一项目同时确定工资);每个项目只属于一个部门管理;每个部门只有一个经理。
①试写出关系模式R的基本函数依赖和关键码.
基本函数依赖:(职工名,项目名)→工资,项目名→部门名,部门名→部门经理
关键码:(职工名,项目名)
②说明R不是2NF的理由,并把R分解成2NF.
2NF特点:不存在非主属性对候选码的部分函数依赖。
 (画图好理解qwq)
(画图好理解qwq)
这里(职工名,项目名) P→部门名,存在非主属性对候选码的部分函数依赖,所以不属于2NF。
分解为2NF:R1(职工名,项目名,工资)、R2(项目名,部门名,部门经理)。
③进而把R分解成3NF,并说明理由。
分析:3NF特点:非主属性对候选码没有部分函数依赖,也没有传递依赖。很明显这里有传递依赖:项目名 t→ 部门经理,需要进一步拆分。拆掉的方法是:A→ B,B→ C,可拆成(A,B)、(B,C)。
分解:R1(职工名,项目名,工资)、R2(项目名,部门名),R3(部门名,部门经理)。
理由:上述三个表的码分别为(职工名,项目名)、(项目名)、(部门名),每一个非主属性对候选码没有部分函数依赖,也没有传递函数依赖。
例5.设有关系模式R(A,B,C,D,E,F),其函数依赖集F={E->D, C->B, CE->F, B->A}。
①指出R的主键并说明原因。
分析:求主键,先求哪个属性集的闭包包含了所有属性。
解答:主键为CE,因为属性集CE的闭包为{C,E,D,B,F,A},包含了所有属性。
②R最高属于第几范式。
分析:助教说一般都是第一范式,当然需要简单分析一下,方便第三题:)
解答:最高属于第一范式,因为存在非主属性对候选码的的部分函数依赖:C->B。
③分解R为3NF。
分析:这个画图真的好理解,先分解为第二范式,然后再分解为第三范式。
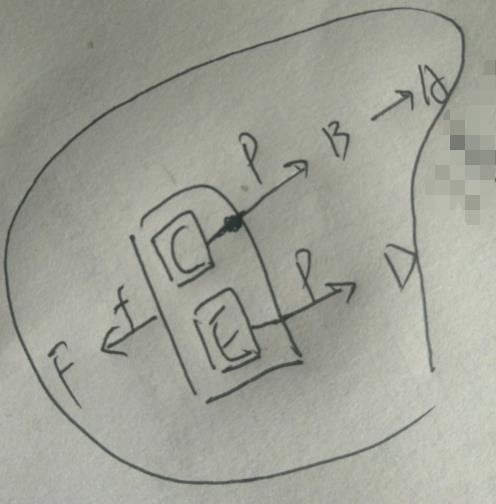
第二范式:(E,D)、(C,B,A)、(C,E,F)(消除非主属性部分函数依赖)
第三范式:(E,D)、(CB)、(BA)、(C,E,F)(消除非主属性传递函数依赖)
解题要点四:判断一个模式分解是否具有无损连接性:
1.无损连接定理:关系模式R(U,F)的一个分解,ρ={R1<U1,F1>,R2<U2,F2>}具有无损连接的充分必要条件是:U1∩U2→U1-U2 €F+ 或U1∩U2→U2-U1€F+。
简单来说,就是
注:上述定理只能判断分成两个关系的判定,如果分成三个及以上的话,怎么办呢(考试不会考这么难的,放心),书上197页有表格法,深入学习:http://blog.csdn.net/qq379666774/article/details/16969493。
2.推论(充分条件):如果R1∩R2是R1或R2的超码(U部分依赖于K,则称K为超码),则R上的分解(R1,R2)是无损分解。
注:注意这里是充分条件,当所有的约束都是函数依赖时它才是必要条件(例如多值依赖就是一种非函数依赖的约束),不过这已经足够了,常用这个。
例6.R(A,B,C,D,E),R的函数依赖集F={A->BC,CB->E,B->D,E->A}. 判断R1(A,B,C),R2(A,D,E)是否是无损连接。
解答:R1∩R2=(A),A的闭包为{A,B,C,E,D},发现A是R1的超码,甚至是主键,所以是无损连接。(注意是充分条件)
解题要点五:判断一个模式分解是否有函数依赖保持性:
1.充分条件:如果F上的每一个函数依赖都在其分解后的某一个关系上成立,则这个分解是保持依赖的。
2.如果上述判断失败,并不能断言分解不是保持依赖的,因为只是充分条件,还要使用下面的通用方法来做进一步判断。
算法:对F上的每一个α→β使用下面的过程:
result:=α; while(result cahnges) do for each 分解后的Ri t=(result∩Ri)+ ∩Ri result=result∪t
其中的(result∩Ri)+属性闭包是在函数依赖集F下计算出来的。如果result中包含了β的所有属性,则函数依赖α→β成立。分解是保持依赖的当且仅当上述过程中F的所有依赖都被保持。
例7.设关系模式R<U, F>,其中U={A, B, C, D, E},F={A→BC,C→D,BC→E,E→A},则分解ρ={R1(ABCE),R2(CD)}满足 ___A__。
A.具有无损连接性、保持函数依赖
B.不具有无损连接性、保持函数依赖
C.具有无损连接性、不保持函数依赖
D.不具有无损连接性、不保持函数依赖
解答:先判断无损连接。R1∩R2={C},计算C+={C,D},可见C是R2的超码,该分解是一个无损分解。
再判断保持依赖。A→BC,BC→E, E→A都在R1上成立(也就是说每一个函数依赖左右两边的属性都在R1中),C→D在R2上成立,因此给分解是保持依赖的。(利用充分条件就可以判断)。
例8.给定关系模式R<U, F>,U={A, B, C, D, E},F={B→A,D→A,A→E,AC→B},其候选关键字为_(1)D_,则分解ρ={R1(ABCE),R2(CD)}满足_(2)D_ 。
(1)A.ABD B.ABE C.ACD D.CD
(2) A.具有无损连接性、保持函数依赖
B.不具有无损连接性、保持函数依赖
C.具有无损连接性、不保持函数依赖
D.不具有无损连接性、不保持函数依赖
解答:第一问,计算各个选项的闭包。
(ABD)+ = {A,B,D,E}
(ABE)+ = {A,B,E}
(ACD)+ = {A,B,C,D,E}
(CD)+ = {A,B,C,D,E}
选D。
第二问,先判断无损连接。R1∩R2={C},计算C+={C}。C既不是R1也不是R2的超码,但这不能判断该分解不具有无损分解性,因为这个判断方法是充分条件。我们用定理来判断:
U1 ∩ U2={C},其闭包为{C}
U1-U2={ABE}
U2-U1={D}
所以U1∩U2→U1-U2 €F+ 和U1∩U2→U2-U1€F+都不成立,即不具有无损连接性。
再判断保持依赖:
B→A,A→E,AC→B在R1上成立,D→A在R1和R2上都不成立,但是还需做进一步判断。
我们对D→A应用算法:
result=D
对R1,result∩R1=ф,t=ф,result=D
再对R2,result∩R2=D,D+ =ADE ,t=D+ ∩R2=D,result=D
一个循环后result未发生变化,因此最后result=D,并未包含A,所以D→A未被保持,所以该分解不是保持依赖的。
选D。
作者: AlvinZH
出处: http://www.cnblogs.com/AlvinZH/
本文版权归作者AlvinZH和博客园所有,欢迎转载和商用,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
以上是关于数据库复习之规范化理论应用(第八次上机内容)的主要内容,如果未能解决你的问题,请参考以下文章