map-reduce入门
Posted claireyuancy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了map-reduce入门相关的知识,希望对你有一定的参考价值。
近期在改写mahout源代码,感觉自己map-reduce功力不够深厚,因此打算系统学习一下。
map-reduce事实上是一种编程范式,从统计词频(wordCount)程序来解说map-reduce的思想最easy理解。
给定一个文件,里面的内容例如以下,要求统计每一个单词的词频。
Hello Angela
I love you Angela
How are you Angela
map(每一个单词处理为一行,key,value形式)
Hello,1
Angela,1
I,1
love,1
you,1
Angela,1
How,1
are,1
you,1
Angela,1
reduce(key同样的行汇在一起)
Angela,<1,1,1>
I, <1>
love, <1>
you, <1,1>
How, <1>
are, <1>
reducer处理后输出
Hello,1
Angela,3
I, 1
love, 1
you, 2
How, 1
are, 1
从上能够看到,map阶段和reduce阶段的输入输出数据都是key,value形式的。
key的存在是为了标志哪些数据须要汇在一起处理。
显然,对于上面统计词频的样例。我们的目的就是让同一个单词的数据落在一起,然后统计该单词出现了多少次。
了解了map-reduce的思想之后,以下来看看分布式的map-reduce是如何子的。
Hadoop有两类节点,一个jobtracker和一序列的tasktracker。
jobtracker调用tasktracker执行任务。假设当中一个tasktracker任务失败了,jobtracker会调度另外一个tasktracker节点又一次执行任务。
Hadoop会将输入数据进行分片处理,每一个分片是一个等大的数据块,
每一个分片会分给一个map任务来依次处理里面的每行数据。
一般来说。合理的分片大小趋向于hdfs一个块的大小,默认是64MB。
从而使得map任务执行在存有输入数据的节点上。降低数据的网络传输。
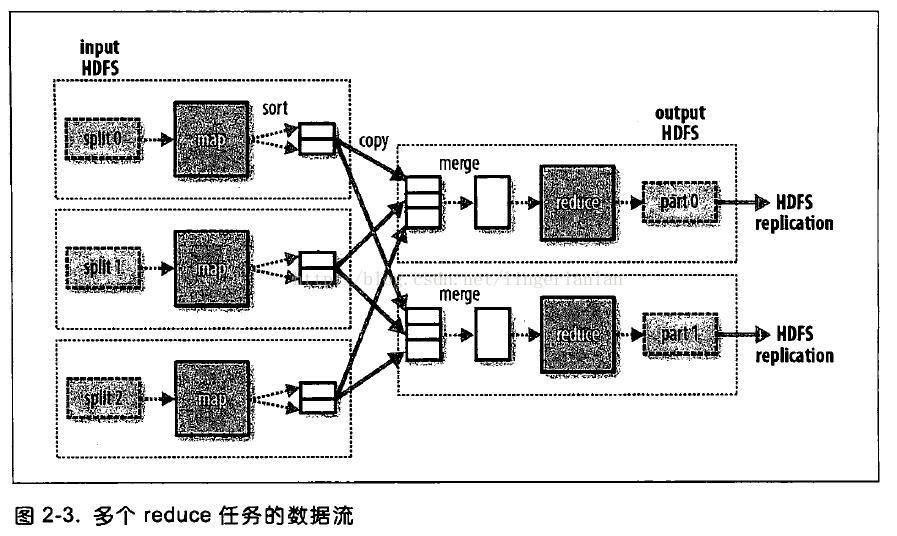
假设有多个reduce任务,那么map任务会对输出进行分区。落在同一个分区的数据,留给一个reduce任务处理。
当然。同样的key的数据肯定在一个分区中。
map在输出到reduce之前,事实上还能够存在一个combine任务,即localreduce,在本地做一次数据合并。从而降低数据的传输。
非常多时候,combiner和reducer能够是同一个类。
本文作者:linger
本文链接:http://blog.csdn.net/lingerlanlan/article/details/46713733
以上是关于map-reduce入门的主要内容,如果未能解决你的问题,请参考以下文章
Python入门之经典函数实例——第3关:Map-Reduce - 映射与归约的思想
Python入门之经典函数实例——第3关:Map-Reduce - 映射与归约的思想