什么是反向传播(第二篇)
Posted 方舟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是反向传播(第二篇)相关的知识,希望对你有一定的参考价值。
作者韩小雨
类比几个人站成一排,第一个人看一幅画(输入数据),描述给第二个人(隐层)……依此类推,到最后一个人(输出)的时候,画出来的画肯定不能看了(误差较大)。
反向传播就是,把画拿给最后一个人看(求取误差),然后最后一个人就会告诉前面的人下次描述时需要注意哪里(权值修正)。
不知明白了没有,如果需要理论推导(其实就是链式法则+梯度下降法),可以参考1986年的bp算法的论文。(20141202, 补上论文题目: Learning representations by back-propagating errors, David E. Rumelhart, Geoffrey E. Hinton & Ronald J. Williams, 1986.)
1.什么是反向传播及背景
众所周知,在深度学习中我们使用反向传播算法进行训练。可能在任意一门深度学习课程中,反向传播都是必学的内容。我们使用反向传播计算每个参数的梯度,从而能够使用各种梯度下降方法SGD,Adam,RMSProp等来更新参数。基本上可以说反向传播算法是深度学习算法的基础。目前所有的深度学习应用,都基于反向传播算法进行训练。
但是,我们人类的大脑是这样学习的吗?
诚然现在的神经科学还无法告诉我们真正的答案,但我们凭我们的常识想想,我们大脑真正的神经网络会需要这样先前向传播一下,再反向传播一下然后更新神经元?这未免太不“科学”了。直观的想象我们大脑的神经元应该都是单独的个体,通过与周围的神经元交流来改变自己。但是对于反向传播算法,这种方法最大的缺点就是更新速度。前面的神经元需要等着后面的神经网络传回误差数据才能更新,要是以后搞个10000+层的神经网络,这显然就太慢了。所以,
能不能异步的更新参数?
甚至,每个参数能够同时更新?
或者差一点,只要前向传播一下就能更新参数?
这些问题要是能解决那就是game changing了。
那么现在DeepMind又开挂了,最新2016年8月18号出来的问题第一次解决了上面的问题。
文章题目:Decoupled Neural Interfaces using Synthetic Gradients
文章链接:https://arxiv.org/pdf/1608.05343.pdf (本文图片都引用自文章)
2 What is the idea?
如果我们陷入在反向传播的思维中,我们就完全无法想象如果没有从后面传回来梯度误差,我们该怎么更新参数。DeepMind打破这种思路,如果不传回来,我们可以
合成梯度!也就是Synthetic Gradients!
也就是我们可以预测梯度。如果我们预测得准确,那么就可以直接更新了。
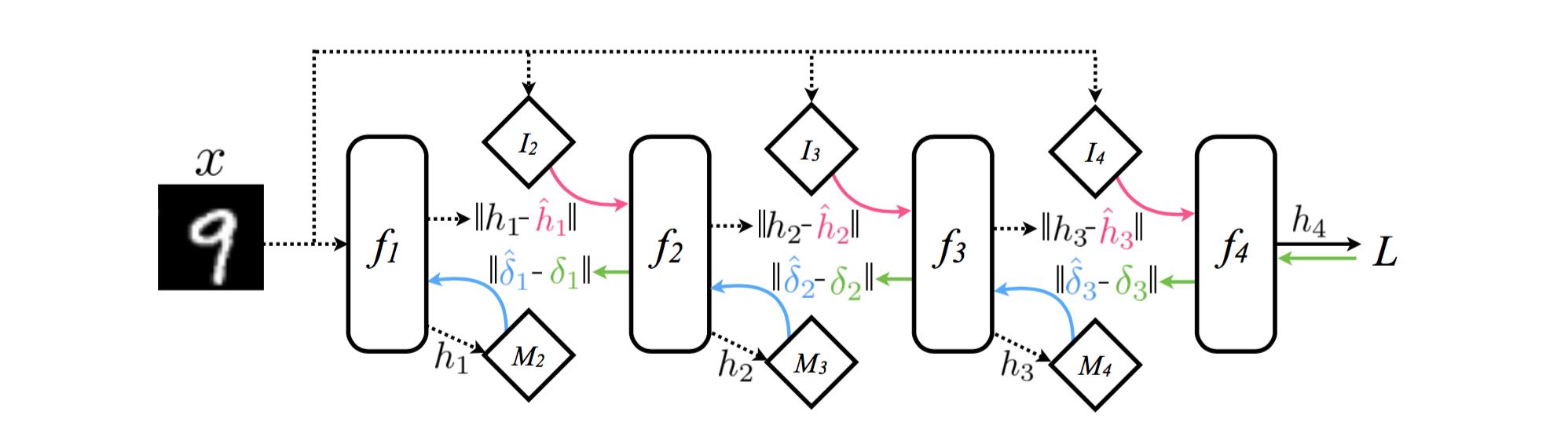
看上图,一般的反向传播如图b所示,从后到前依次传递梯度(绿色的线),然后更新参数。那么这里,我们使用一个M来预测梯度(蓝色的线),然后更新参数。我们传给M当前层的输出,然后M返回给我们梯度。
就用神经网络来预测!
也就是每一层的神经网络对应另一个神经网络M,每个M来调控每一层的神经网络更新,这套方法称为 Decoupled Neural Interfaces(DNI), 也就是将神经网络分解训练的意思。
那么不管是
MLP,CNN还是RNN或者其他各种结构的神经网络,因为都是以层为单位,都可以使用神经网络来合成梯度,也就是都可以使用这样的方法来实现训练。
3 合成梯度的M神经网络是如何训练的?
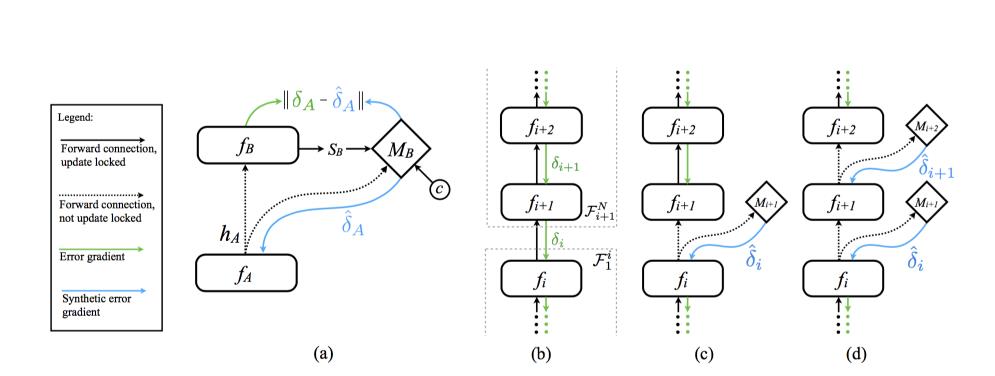
合成梯度的M神经网络用来输出估计的梯度误差。那么要训练M就需要有一个梯度误差来做目标,但是这里没有完全的反向传播,如何得到真实的梯度误差?作者采用一个tradeoff,
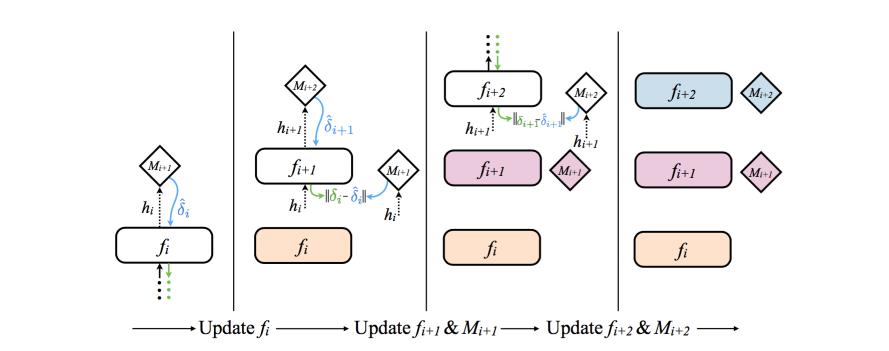
利用下一层神经网络的估计梯度误差来计算本层的梯度误差,并利用这个误差作为目标训练M。如上图所示。
4 看结果
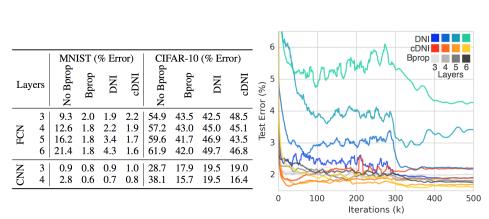
上图是MNIST的训练,采用全连接网络FCN或者CNN进行训练。从结果上可以看到,DNI特别是cDNI(就是将数据的标签作为神经网络M的输入)效果蛮好的(略低于反向传播),但是训练速度比原来采用反向传播的快,特别看上面的曲线橙色部分,比灰色的反向传播快了非常多。
从上面的结果可以看出,采用DNI进行训练相比反向传播竟然速度快,效果好。要是预测梯度的神经网络能提前训练好,估计又能快不少吧!
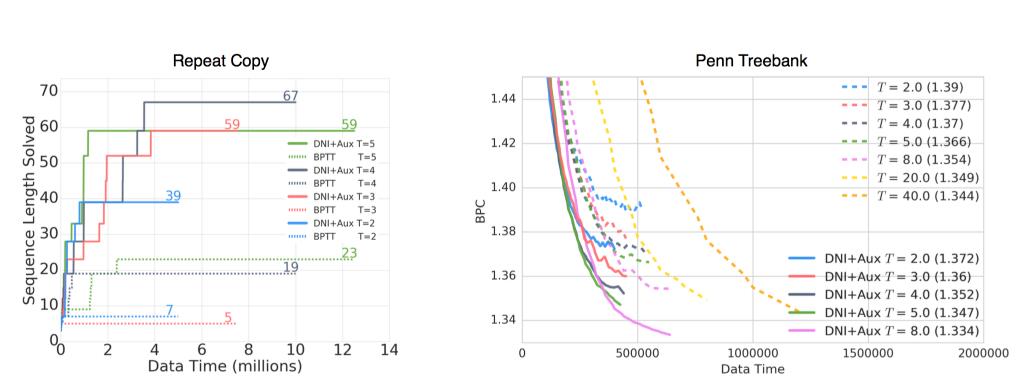
上面这图是针对RNN的训练,一个是Repeat Copy复制任务,一个是语言模型的训练。因为RNN的梯度计算面临无穷的循环,所以一般采用一定的时间间隔来计算梯度。那么这里,DNI的效果远远超过了BPTT(Back Propagation Through Time). 速度两倍以上。
从上面的结果可以看出,采用DNI进行训练相比反向传播竟然速度快,效果好。要是预测梯度的神经网络能提前训练好,估计又能快不少吧!
5 One More Thing
DeepMind不仅仅做到不需要反向传播,甚至更进一步,连前向传播也不用,直接异步更新每一层的参数。怎么做的?
不仅仅预测梯度,我们还预测输入!
这样做对于MNIST的训练也能达到2%的误差,只是慢了一点。估计主要的慢是在I和M的模型训练上。这里4层隐藏层就有6个额外的神经网络了。
6 这个成果意味着什么?神经网络模块化了。
每一层网络都可以看成独立的一个模块,模块与模块之间相互通信,从而实现学习。而学习训练不再需要同步,可以异步。也就是说每个模块都可以独立训练。Paper中也做了异步训练的实验,可以随机的训练神经网络中的不同层,或者有两个神经网络需要相互配合的,都可以异步训练。这是这个成果最大的意义,将能够因此构建出完全不一样的神经网络模型,训练方式发生完全的改变。
7 存在的问题
大家都可以注意到,虽然这个idea能够使主神经网络不再使用反向传播算法,但是I和M的神经网络都是依靠反向传播算法进行更新!也就是反而多了好多个小的神经网络。但是这个方法如果不考虑I和M(主要是M)的训练,那么显然将会非常的快。那么,I比较难,涉及到具体的输入,但是有没有可能能够预训练M呢?或者换一个角度思考,我们人类大脑的神经元是否是相互独立,每一个神经元都有自己的一套学习机制在里面,能够自主改变?这些很值得我们思考。
8 一点感想
因为神经网络什么都能学习,所以用神经网络来更新神经网络也不足为怪。之前的最前沿:让计算机学会学习Let Computers Learn to Learn - 智能单元 - 知乎专栏就是使用神经网络来做梯度更新的工作。这里是使用神经网络来合成梯度。所以,如果把上一篇的成果结合进来,神经网络大部分都是神经网络自己在训练了!
这是深度学习基本学习机制的大变革,一步一步迈向人类的大脑!
补充:DeepMind官网给出了一个介绍DNI的博客:https://deepmind.com/blog#decoupled-neural-interfaces-using-synthetic-gradients
你下面为大家展示板向传播的实际应用。



文章来自知乎 百度
以上是关于什么是反向传播(第二篇)的主要内容,如果未能解决你的问题,请参考以下文章
反式自动微分autodiff是什么?反向传播(Back Propagation)是什么?它是如何工作的?反向传播与反式自动微分autodiff有什么区别?