INFORMATICA 开发规范
Posted JUN王者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了INFORMATICA 开发规范相关的知识,希望对你有一定的参考价值。
|
|
目 录
Informatica开发规范.... 1
目 录.... 2
1 编写目的.... 4
2 ETL研发责任人界定.... 4
3 ETL 研发数据库操作约束条件.... 4
4 定义.... 4
5 范围.... 5
6 系统通用属性.... 6
7 命名规则.... 6
7.1 通用规则... 6
7.2 Connection 数据源连接... 6
7.2.1 Connection 数据连接命名... 6
7.2.2 数据库类型对应缩写... 6
7.2.3 生产数据库的SID.. 7
7.3 组件命名.... 7
7.4 Folder/mapplet/Mapping/Session/Workflow/Schedule命名.... 9
8 创建Connection连接.... 9
9 创建文件夹.... 10
9.1 创建文件夹... 10
9.2 复制共享对象... 11
10 Mapping设计.... 13
10.1 导入源和目标的表结构... 14
10.2 Mapping设计... 16
10.3 常用组件设计说明... 17
11 Workflow设计.... 19
11.1 创建Workflow.. 20
11.2 Workflow属性设置... 20
11.3 添加可复用Session “pre_sql”、“post_sql”. 22
11.4 编辑Assignment. 23
12 Session设计.... 23
12.1 创建Session.. 24
12.2 必要Session属性设置... 24
12.2.1 General属性... 24
12.2.2 Property属性... 24
12.2.3 Config Object属性... 25
12.2.4 Mapping属性... 26
12.2.4.1 Source 属性... 26
12.2.4.2 Target属性... 27
13 从中间库取数据.... 28
13.1 复制共享对象... 28
参考复制共享对象创建‘M_GetParam_Mid’的快捷方式,复制’ pre_S_MID’、’post_S_MID’ 28
13.2 Workflow设计... 28
14 开发建议.... 30
15 备份及恢复.... 30
15.1 备份... 30
15.2 恢复... 31
16 参考文档.... 31
17 常见问题解决.... 31
1 编写目的
本文档旨在本次项目中实施,Informatica工具所涉及到的数据连接,命名规范和工作开发规范方面的规定和指引,统一开发习惯,以便在开发过程中能起到事半功倍的效果。
2 ETL研发运维责任人界定
1)资科内部业务数据流转,采取使用方研发原则,即谁取用数据,谁负责ETL版本研发。目标系统运维人员进行运维。
2)对于业务用户的独立管理系统,没有专门研发,由取数源端研发负责informatica 版本研发推送数据。源端系统对应运维人员负责对应workflow运维。
3 ETL 研发数据库操作约束条件
1)对于增量同步表,需要源表和目标表存在主键。
2)增量字段上,需要有索引
3)增量字段 (如时间条件,必须严格顺序进入数据库,或者增量同步完成后,严格保证增量同步的取数范围后续不会有数据进入)
|
同步场景 |
同步要求 |
|||
|
同步类型 |
源表和目标表是否存在主键或者唯一键 |
增量字段上是否有索引(源表和目标表) |
update 同步 |
delte同步 |
|
有标识字段增量 |
存在pk或者索引 |
需要存在索引 |
需要存在updatetime字段,并使用update字段PK 进行update 更新同步。 |
需要将删除数据写入临时表,etl同时同步临时表后将目标库对应数据删除,源端也需要进行定期清理临时表 |
|
源表全量读取同步 |
不存在约束或者索引 |
N/A |
N/A |
N/A |
|
源表全量读取同步 |
存在pk或者索引 |
N/A |
N/A |
N/A |
4 定义
|
序号 |
术语或缩略语 |
说明性定义 |
|
1 |
ETL |
Extraction-Transformation-Loading,数据加载 |
|
2 |
Source |
源 |
|
3 |
Target |
目标 |
|
4 |
Transformation |
组件 |
|
5 |
Mapping |
数据映射 |
|
6 |
Mapplet |
数据映射集,可复用的Transformation组合 |
|
7 |
Session |
执行任务 |
|
8 |
Worklet |
数据工作集 |
|
9 |
Workflow |
数据工作流 |
|
10 |
Schedule |
调度频率 |
|
11 |
Parameter |
参数 |
|
|
|
|
|
12 |
ETLUser |
用与ETL数据同步的数据库用户 |
|
13 |
ProductDatabaseSID |
生产系统数据库SID |
|
|
|
|
5 范围
本文档读者包括:
l 项目经理;
l 系统管理员;
l DBA管理员;
l 开发人员;
l 测试人员;
l 运维人员;
本项目需要使用到的技术:
l ETL数据整合及转换:Informatica;
l 操作系统:Linux、Windows
l 数据库:Oracle、mysql、DB2、MS SQLServer等
6 系统通用属性
|
|
Service Variable |
Description |
值 |
|
1 |
$PMRootDir |
Infa_share根目录 |
<Installation_Directory>\\server\\infa_shared |
|
2 |
$PMSessionLogDir |
Session 运行日志目录 |
$PMRootDir/SessLogs. |
|
3 |
$PMBadFileDir |
Reject files拒绝文件目录 |
$PMRootDir/BadFiles. |
|
4 |
$PMCacheDir |
Temporary cache files |
$PMRootDir/Cache |
|
5 |
$PMTargetFileDir |
Target files 目标文件生成目录 |
$PMRootDir/TgtFiles |
|
6 |
$PMSourceFileDir |
Source files 平面文件源文件目录 |
$PMRootDir/SrcFiles |
|
9 |
$PMWorkflowLogDir |
Workflow logs workflow执行日志目录 |
$PMRootDir/WorkflowLogs. |
|
10 |
$PMLookupFileDir |
Lookup files lookup生成的cache目录 |
$PMRootDir/LkpFiles. |
|
11 |
$PMTempDir |
临时文件目录 |
$PMRootDir/Temp |
|
12 |
$PMStorageDir |
HA时,记录workflow的运行状态 |
$PMRootDir/Storage. |
7 命名规则
7.1 通用规则
以下元素,数据库表,字段名称,函数名称,函数表达式,SQL语句均采用大写字母。
7.2 Connection 数据源连接
7.2.1 Connection 数据连接命名
数据链接分为源数据库链接与目标数据库链接,ETL的E(抽取)与L(加载)的链接。
数据库链接方式分为Native、ODBC两种方式:
1)Native是采用相应数据的客户端连接来抽取、加载数据,比如oracle、DB2等;
2)ODBC是采用DataDirect ODBC的方式连接数据库,比如mysql、MSSQL。
数据连接的命名采用:DataBaseType_ProductDatabaseSID_ETLUSER。
说明:DataBaseType为数据源类型,ProductDatabaseSID生产数据库的SID,ETLUser为用与ETL数据同步的用户。
例如: Ora_ASURE_BILETL,连接方式为Native方式,Ora表示数据类型为Oracle,ASURE为阿修罗生产数据库SID,BILETL为ETL的操作用户。
例如:ODBC_ Mysql_ASURE_BILETL,ODBC表示采用ODBC的方式连接。Mysql为数据库类型,ASURE为阿修罗系统,BILETL为ETL操作用户。
7.2.2 数据库类型对应缩写
表5-1 数据库类型缩写
|
序号 |
数据源类型 |
缩写 |
|
1 |
Oracle |
Ora_ |
|
2 |
DB2 |
DB2_ |
|
3 |
Mysql |
Mysql_ |
|
4 |
Microsoft SQL Server |
MSSQL_ |
|
5 |
Sybase |
Sybase_ |
|
6 |
Greenplum |
GP_ |
|
7 |
Teradata |
TD_ |
|
8 |
ODBC |
ODBC_DataType_ |
|
|
|
|
7.2.3 生产数据库的SID
表5-2 数据库信息表
|
序号 |
数据库中文名 |
数据库SID |
备注 |
|
1 |
阿修罗系统 |
ASURE |
|
|
2 |
新车辆管理系统 |
VMS |
|
|
3 |
短信系统 |
SMSDB |
|
|
4 |
|
|
|
7.3 组件命名
表5-3 常用组件命名前缀
|
序号 |
组件名称 |
图标 |
命名规范 |
含义 |
|
1 |
Source Qualifier |

|
sq_ |
从数据源读取数据 |
|
2 |
Expression |

|
exp_desc |
行级转换 |
|
3 |
Filter |

|
fil_ |
数据过滤 |
|
4 |
Sorter |

|
sort_ |
数据排序 |
|
5 |
Aggregator |

|
agg_ |
聚合 |
|
6 |
Joiner |

|
jnr_ |
异构数据关接连接 |
|
7 |
Lookup |

|
lkp_ |
查询连接 |
|
8 |
Update Strategy |

|
ust_ |
对目标编辑 insert, update, delete, reject |
|
9 |
Router |

|
rot_ |
条件分发 |
|
10 |
Sequence Generator |

|
sqg_ |
序列号生成器 |
|
11 |
Normalizer |

|
nrm_ |
记录规范化 |
|
12 |
Rank |

|
rnk_ |
对记录进行TOPx |
|
13 |
Union |

|
uni_ |
数据合并 |
|
14 |
Transaction Control |

|
tc_ |
对装载数据按条件进行事务控制 |
|
15 |
Stored Procedure |

|
sp_ |
存储过程组件 |
|
16 |
Custom |

|
cus_ |
用户自定义组件 |
|
17 |
HTTP |

|
http_ |
WWW组件 |
|
18 |
Java |

|
java_ |
Java自编程组件 |
7.4 Folder/mapplet/Mapping/Session/Workflow/Schedule命名
表5-4 Folder/mapplet/Mapping/Session/Workflow命名规范
|
情形 |
名称 |
例如 |
|
|
FOLDER |
|||
|
公用文件夹 |
000_Shared |
|
|
|
文件夹 |
ProductDatabaseSID_OWNER |
SFOSS_ EXP5(sfoss是生产阿修罗数据库sid, exp5是我们要操作的表owner) |
|
|
MAPPLET |
|||
|
|
MPL_Business Name |
MPL_LRNull |
|
|
MAPPING |
|
|
|
|
单源单目标 |
M_Target Table Name |
M_TT_WAYBILL |
|
|
多源单目标 |
M_Target Table Name |
M_TT_WAYBILL |
|
|
单源多目标 |
M_1ToN_Function description |
M_1ToN__Broadcost |
|
|
多源多目标 |
M_NToN_Function description |
M_NToN_Gather |
|
|
SESSION |
|||
|
可复用post_S_ |
post_S_ mapping name |
post_S_M_STGOMS_ORDERS |
|
|
可复用pre_S_ |
pre_S_ mapping name |
pre_S_M_STGOMS_ORDERS |
|
|
单mapping单session |
S_mapping name |
S_M_STGOMS_ORDERS |
|
|
单mapping多session |
S_mapping name_区域/子系统 |
S_M_STGOMS_ORDERS_BJ S_M_STGOMS_ORDERS_GX (BJ代表北京,GX体表广西) |
|
|
WORKFLOW |
|||
|
单mapping单session |
WF_mapping name |
WF_STGOMS_ORDERS |
|
|
单mapping多session |
WF_mapping name |
WF_STGOMS_ORDERS |
|
|
多mapping多session |
WF_function description |
WF_UpdateUsersAndGroups |
|
|
Schedule |
|||
|
SCHDL_运行间隔_(运行时间)_(截止时间) |
每5分钟运行一次,2014年5月6号过期 |
SCHDL_5MIN_Stop20140506 |
|
|
|
每5分钟运行一次,永不过期 |
SCHDL_5MIN_FOREVER |
|
|
|
每天21:30运行,永不过期 |
SCHDL_1Day_AT2130_FOREVER |
|
|
|
每月4号21:30运行,永不过期 |
SCHDL_1MON_4THAT2130__FOREVER |
|
8 创建Connection连接
创建Connection由Informatica管理员完成,但在开发环境和测试中开发人员有修改Connection属性的权限。
以创建Oracle Connection“Ora_ASURE_SFMAP”为例进行说明
- 登陆到Informatica 服务器,查看对应的SID“ASURE”是否已经添加到tnsname.ora文件中,否则在tnsname.ora中添加
- 登陆到Workflow ManageràConnection(连接)àRelationalàSelect Type = “Oracle”àNew…(按钮)
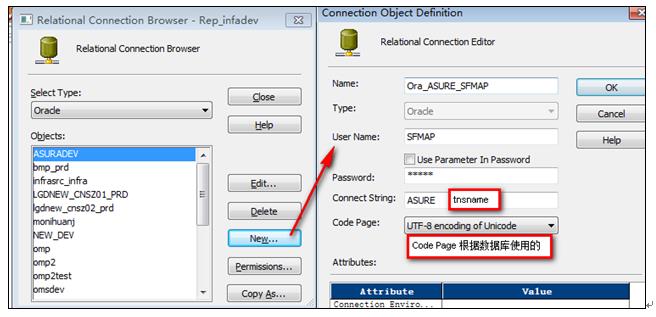
8‑1 创建Connection
- 修改Connection连接的权限,登陆到Workflow ManageràConnection(连接)àRelationalàObjects:选择需要修改的Connection连接àPermission…(按钮)à修改属主。给Others组执行的权限。
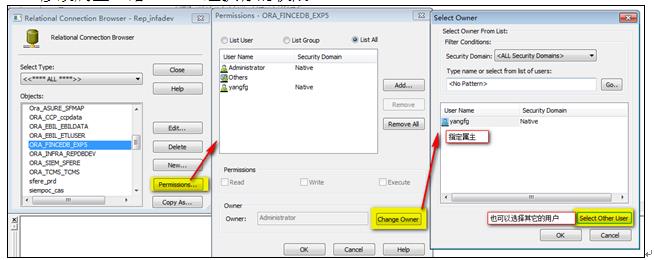
8‑2 修改Connection属主
9 创建文件夹
在创建文件夹前,需要在目标数据创建用户ETLMGR,脚本在文件夹“ETLMGR”中,请按照顺序执行
9.1 创建文件夹
- 登陆Repository Manager 参考第5章的命名规则创建文件夹
操作:FolderàCreateà在弹出的对话框中输入文件夹名称
不关闭对话框进入下一步
- 选择新建文件夹的属主
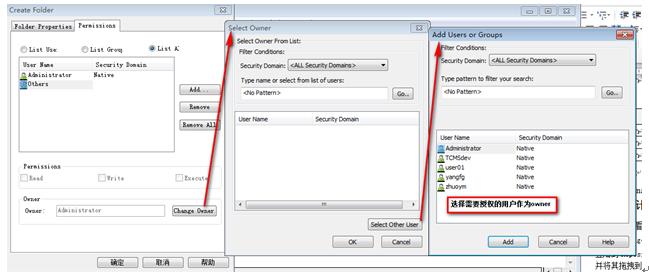
9‑1 选择文件夹属主
9.2 复制共享对象
此部分操作由开发从员完成
- 登陆Repository Manager将文件夹“000_Shared”下的Mapping“M_GetParam”、 “M_getSessionRunStatus”拖拽到新建的文件夹中,并在弹出的创建快捷链接对话框选择“全部确定”。
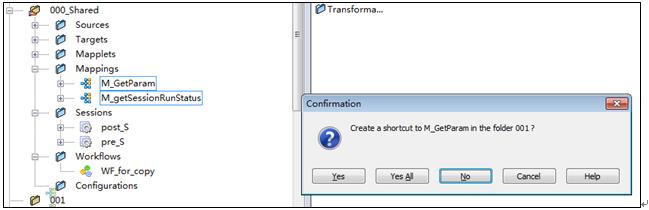
9‑2 创建共享Mapping快捷链接
- 登陆Workflow Manager打开新建的文件夹,将文件夹“000_Shared”下的Session “pre_S”、“post_S”拖拽到新建的文件夹中,并在弹出的复制对话框选择“确定”,
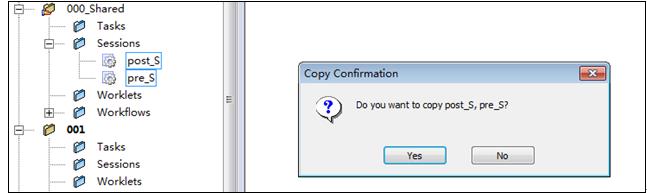
9‑3 复制共享Session
然后处理Mapping冲突,为找不到的Mapping重新选择对应的快捷方式
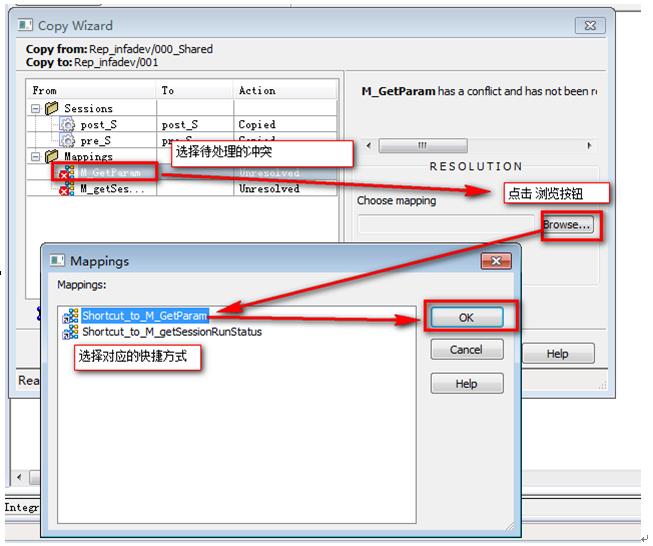
9‑4 Mapping冲突处理
冲突处理完接提示选择下一步并确认,完成这一步骤的操作
- 登陆到Workflow Manager打开新建的文件夹,编辑“post_S”、“pre_S”源和目标的Connection(连接)
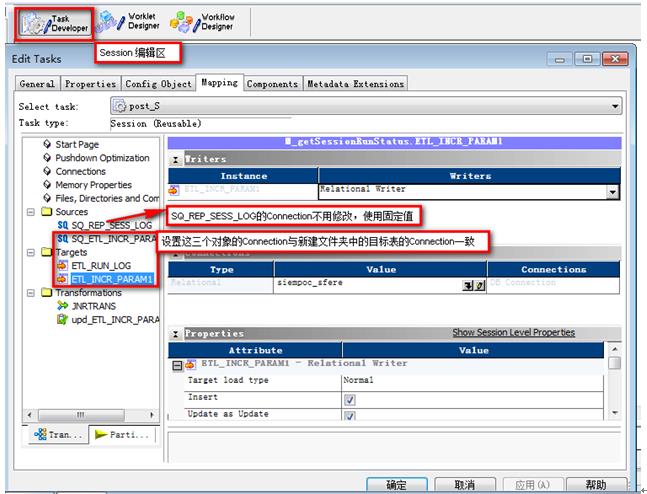
9‑5编辑“post_S”
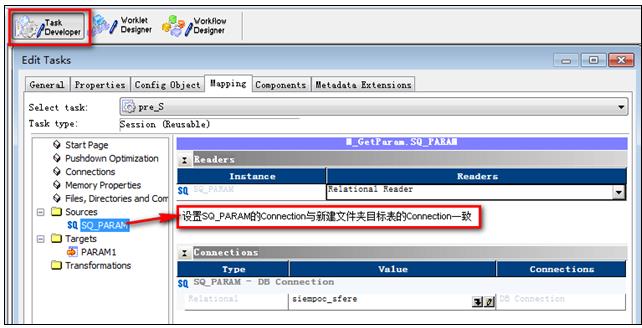
9‑6 编辑“pre_S”
10 Mapping设计
注意1:在进行Mapping之前,需要在目标表数据库的ETLMGR.ETL_INCR_PARAM中插入对应目标表相关的信息,具体内容可能过查询ETLMGR.ETL_DICT获得帮助
注意2:ETLMGR.ETL_INCR_PARAM.TIME_BEFORE_NOW(增量结束时间与当前时间的时间差,以秒为单位)的值建议不小于300,以避免一些来不及commit的数据会丢失。
登陆到Designer,本章所述的所有操作均在Designer客户端。
10.1 导入源和目标的表结构
导入源表结构
创建源表的ODBC连接
EnableNcharSupport: 默认是不打勾的,不打勾的情况下导入char,varchar,varchar2会变成nchar,nvarchar,nvarchar2
ODBC连接只是作为导入源表和目标表的结构的媒介,不会进行实际数据的处理,实际数据的处理由服务端Connection完成
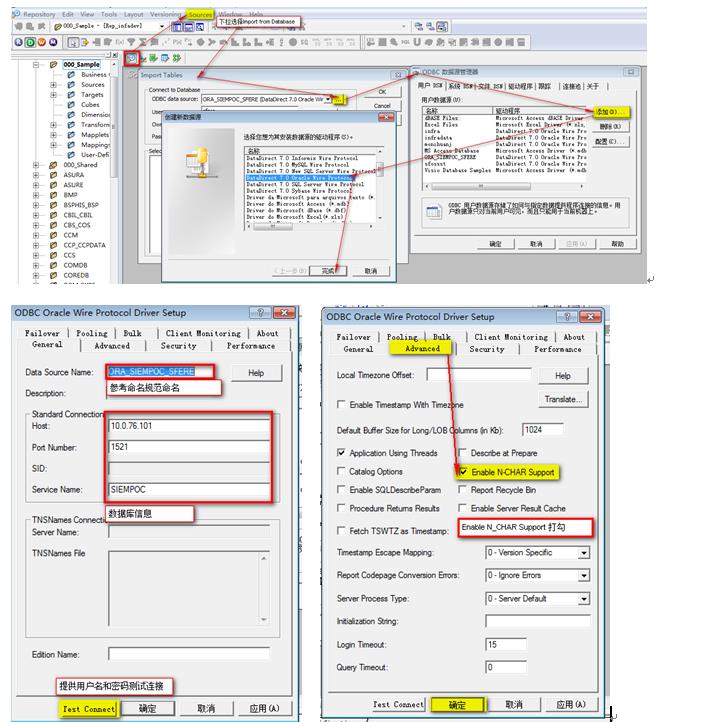
从ODBC连接中导入源表的结构

导入目标表结构
导入目标表结构与导入源表结构相似,但是要先切换到目标表的编辑窗口
10.2 Mapping设计
开发时注意查看客户端左上方的Folder显示,一定要在正确的Folder里面工作。
- 创建Mapping
展开文件夹“000_Sample”,找到Mapping“M_for_copy”并将其拖拽到目标文件夹,在弹出的对话框中选择“Yes”
- 根据第五章的命名规范重命名“M_for_copy”并添加注释
操作:菜单MappingàEdit
Comment(注释) 内容填写如下:
Create date: 日期
Create by: 用户名(现实中文名)
Desc: decription 例:用户信息交换
[
Modify Date:
Modify by: 用户
Desc: decription 例:过期用户信息不再交换
]
- 所有的Mapping都添加四个参数(Parameter),
操作:在复制Mapping的过程中已经创建
- $$INCR_START_DT STRING(20) DEFAULT: 1900-01-01 00:00:00 à增量起始时间(表示增量区间的起点)
- $$INCR_END_DT STRING(20) DEFAULT: 2900-01-01 00:00:00 à增量截至时间(表示增量区间的终点)
- $$INCR_START_ID DECIMAL(19,0) DEFAULT: 0 à增量起始主键值
- $$INCR_END_ID DECIMAL(19,0) DEFAULT: 9999999999999999999 à增量截至主键值
- Mapping具体设计参考文档《Informatica觉见场景设计》
l 在组件中创建变量时,注意选择数据类型,选择长度,在给变量赋值或将变量赋值给字段时要保持数据类型一致,不一致时要使用显式类型转换。
l 在做字符处理时,注意NULL,空字符串和空格的区别以及不同的判读和处理方式
l 不需要输出的端口不勾选OutputPort。当组件中有重名的字段时,输入的字段在原字段后加\'_IN\',变量的字段在原字段后加\'_V\',输出字段名尽量保持和下一个组件的输入字段名名称一致,以便使用按名称自动连接
l 数据加载方式:全量,增量
- 全量: Truncate & Insert
- 基于时间的增量(具体实现方案参考Informatica常见场景设计)
- 基于主键的增量(具体实现方案参考Informatica常见场景设计)
- 对于所有的Mapping要求尽量使用增量(增量区间可优先按时间确定,没有时间戳时按主键确定)
- 对于数据源表确实无法提供增量时间或主键的则全量抽取。全量抽取只适用于只适用于数据量小的表,如果数据表的数据量特别大,则需要跟需求方重新确定需求。
10.3 常用组件设计说明
l Source Qualifier 组件使用:
- 对于源系统使用nvarchar2,导入时确保在mapping中使用nstring与之匹配,这样
以上是关于INFORMATICA 开发规范的主要内容,如果未能解决你的问题,请参考以下文章