深度神经网络tricks and tips
Posted 哈哈哈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度神经网络tricks and tips相关的知识,希望对你有一定的参考价值。
1)data augmentation
(augment 增加,aug:to increase 词根,同August(奥古斯特即凯撒大帝,自认为最伟大的帝王,他出生在八月,他以自己的名字命名这个月)同根词有auct, auction(拍卖,不停的增价), auth,author(使书一段一段长起来,作者);authority -ity 表特性,权利;authorize (-ize 使有)作者使有,授权)
在深度学习中就是人工增加训练集的大小,通过平移、翻转加噪等从已有数据中创造新数据。原因是深度网络需要大量的数据来训练。
- 旋转 | 反射变换(Rotation/reflection): 随机旋转图像一定角度; 改变图像内容的朝向;
- 翻转变换(flip): 沿着水平或者垂直方向翻转图像;
- 缩放变换(zoom): 按照一定的比例放大或者缩小图像;
- 平移变换(shift): 在图像平面上对图像以一定方式进行平移;可以采用随机或人为定义的方式指定平移范围和平移步长, 沿水平或竖直方向进行平移. 改变图像内容的位置;
- 尺度变换(scale): 对图像按照指定的尺度因子, 进行放大或缩小; 或者参照SIFT特征提取思想, 利用指定的尺度因子对图像滤波构造尺度空间. 改变图像内容的大小或模糊程度;
- 对比度变换(contrast): 在图像的HSV颜色空间,改变饱和度S和V亮度分量,保持色调H不变. 对每个像素的S和V分量进行指数运算(指数因子在0.25到4之间), 增加光照变化;
- 噪声扰动(noise): 对图像的每个像素RGB进行随机扰动, 常用的噪声模式是椒盐噪声和高斯噪声;
- 颜色变换(color): 在训练集像素值的RGB颜色空间进行PCA。
不同的任务背景下, 我们可以通过图像的几何变换, 使用以下一种或多种组合数据增强变换来增加输入数据的量。 几何变换不改变像素值, 而是改变像素所在的位置。 通过Data Augmentation方法扩张了数据集的范围, 作为输入时, 以期待网络学习到更多的图像不变性特征。
2)预处理
- zero-center X-=np.mean(X,axis=0)
- normalize X/=np.std(X,axis=0)
- PCA whitening
3)初始化
- all zero(if every neuron output the same value, then they will have same gradients using back-propagation.and have the same updates. there will have no asymmetry between neurons)
- small random numbers: what the parameters to close to 0, but not 0.然而这是有弊端的,一旦随机分布选择不当,就会导致网络优化陷入困境。随着层数的增加,我们看到输出值迅速向0靠拢,在后几层中,几乎所有的输出值 x 都很接近0!回忆优化神经网络的back propagation算法,根据链式法则,gradient等于当前函数的gradient乘以后一层的gradient,这意味着输出值 x 是计算gradient中的乘法因子,直接导致gradient很小,使得参数难以被更新!
- Xavier Initialization其初始化方式也并不复杂。Xavier初始化的基本思想是保持输入和输出的方差一致,这样就避免了所有输出值都趋向于0

- He Initialization在ReLU activation function中推荐使用,:在ReLU网络中,假定每一层有一半的神经元被激活,另一半为0,所以,要保持variance不变,只需要在Xavier的基础上再除以2:

4)training
- filter and pool size(power of 2)pooling 2*2;
- learning rate: 跟mini-batch size 有关,如果在validation set上不进步了,学习率/2;
- fine-tune onpre-trained model:small dataset and similar task。 数据的大小和相关性来考虑fine-tuning layer的多少
5)激活函数:
见博文
sigmods:kill gradients, not zero-centered, the gradient updates either all be positive or all be negitive, so this will produce undesirable zig-zagging dynamics in the gradient updates.
tanh
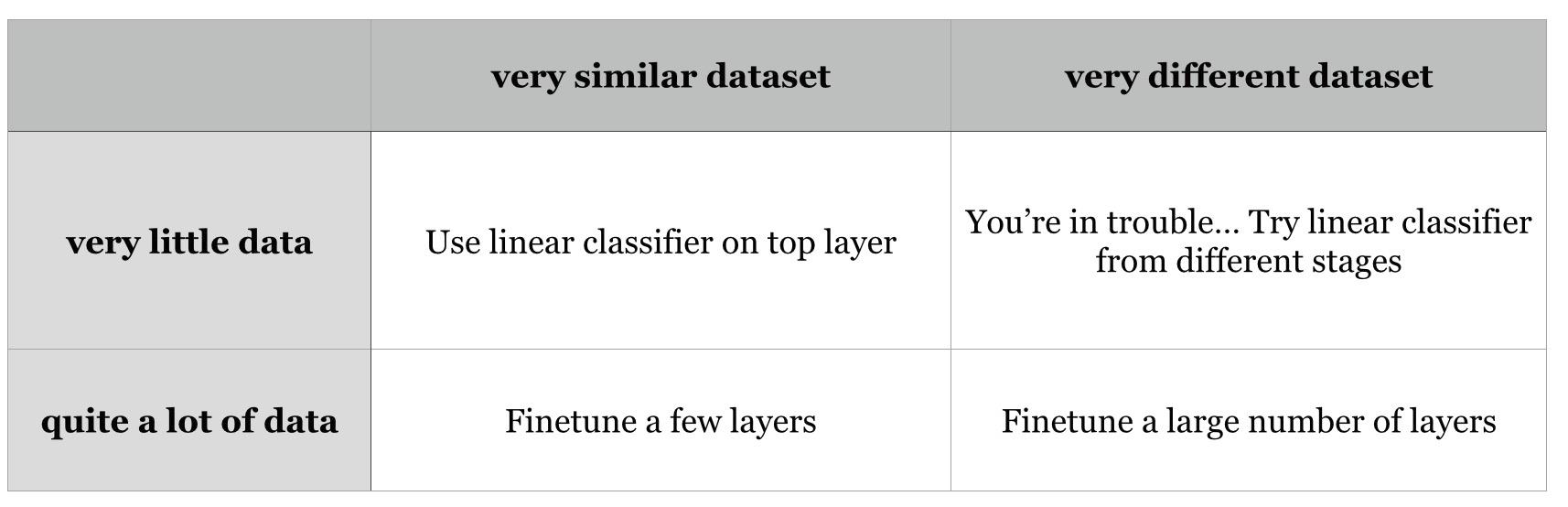
ReLU: 简单阈值,不会梯度消减,加快计算,但是可能造成训练停止,小于0的为0。
leaky ReLU:
parametric ReLU
Randomized ReLU
6) regularization(正则化)
L2 regularization:+  到损失函数, where
到损失函数, where  is the regularization strength. It is common to see the factor of
is the regularization strength. It is common to see the factor of  in front because then the gradient of this term with respect to the parameter
in front because then the gradient of this term with respect to the parameter  is simply
is simply  instead of
instead of  .
.
L1 regularization:+ ,
,  (this is called Elastic net regularization)
(this is called Elastic net regularization)
Max norm regularization: 
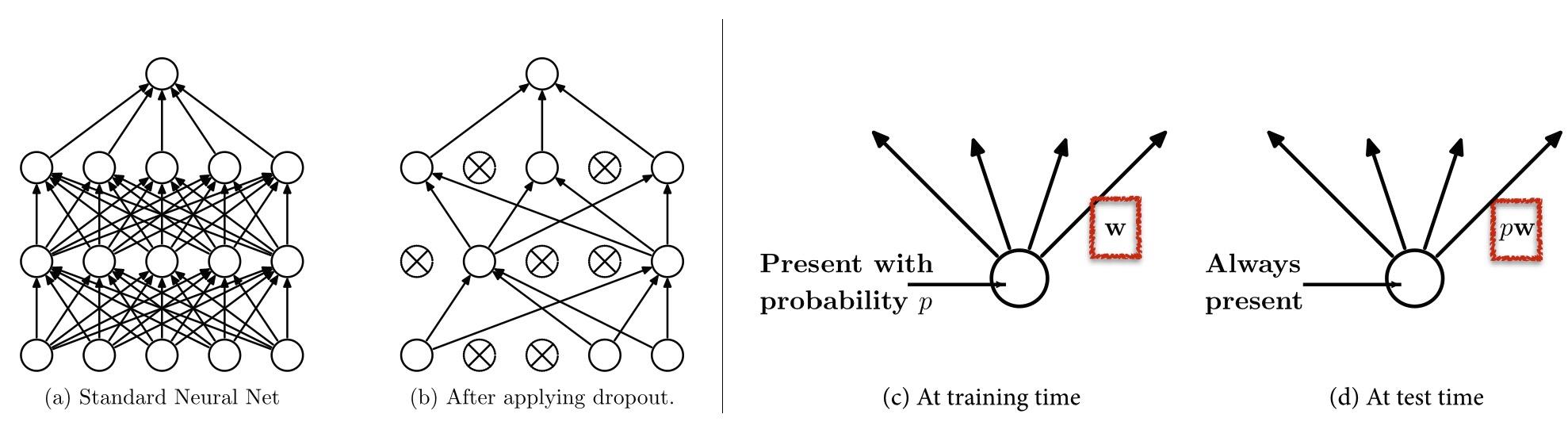
Dropout:effective, 相当于对神经元的采样
7)从输出的training过程上观察 insights from figure
learning rate is sensitive,高的学习率可能造成不稳定,低的学习率可能loss降低很慢。一般都是,开始快,后来慢
要防止overfitting
以上是关于深度神经网络tricks and tips的主要内容,如果未能解决你的问题,请参考以下文章