浅谈JAVA集合框架
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈JAVA集合框架相关的知识,希望对你有一定的参考价值。
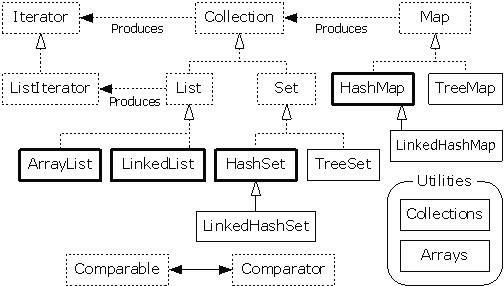
??Collection
Collection下有俩个子类,分别为List和Set。List是有序的,且元素可重复。Set是无序的,且元素不可重复。这里说一下有序与无序的概念,即存入的顺序与取出的顺序是否一致,若一致,则为有序,否则为无序。
List?
List下有俩个子类分别为?ArrayList和linkedList。ArrayList查询快,插入慢。LinkedList查询慢,插入快。我们通常会考虑使用LinkedList,因为集合操作中查询是比更新普遍要多的,而在你无法抉择使用哪个时,选择LinkedList。
Arraylist?
? ArrayList是基于数组结构的。这里得提一下ArrayList的Contains方法,其底层实现的是equals方法。ArrayList若要比较俩个元素是否相等(这里的元素是指引用数据类型的),则该元素的实例模板(类)必须重新equals方法,在此方法中自己写具体的比较方式。ArrayList有自己的取出方式get(int index)。同时Collection抽取出其子类的共性方法Iterator(),但是这有局限性,在迭代过程中不能对集合进行添加和更新操作。为了打破这个局限性,List有自己特有的迭代器ListIterator(Iterator的子类),在迭代过程中,它能对集合进行添加或更新操作。??
下面的代码是实现排除重复元素:
1 public class ArrayListTest2 { 2 public static ArrayList singleElement(ArrayList al){ 3 ArrayList newal=new ArrayList(); 4 Iterator it =al.iterator(); 5 while(it.hasNext()){ 6 Object obj =it.next(); 7 if(!newal.contains(obj)){ 8 newal.add(obj); 9 person p =(person)obj; 10 System.out.println(p.getName()+"的年龄为"+p.getAge()); 11 } 12 } 13 return newal; 14 15 } 16 17 public static void main(String [] args){ 18 ArrayList al =new ArrayList(); 19 al.add(new person("jospe01",21)); 20 al.add(new person("jospe02",22)); 21 al.add(new person("jospe03",23)); 22 al.add(new person("jospe02",21)); 23 24 Iterator it =al.iterator(); 25 26 al=singleElement(al); 27 28 29 }
public boolean equals(Object obj){ if(!(obj instanceof person)) return false; person p =(person)obj; System.out.println(this.name+"..."+p.getName()); return this.name.equals(p.getName())&&this.age==p.getAge(); }
备注:contains方法底层实现的是equals方法。
LinkedList
LinkedList是基于链表结构的。这里介绍下它的特有方法:addFirst,addLast,removeLast,removeFirst。合理的运用上面的方法便可实现队列和链表。队列是先进先出,先addFirst,然后removeLast。栈是先进后出,先addFirst,然后removeFirst。
下面是队列实现的详细代码:
import java.util.LinkedList;
public class QueueDemo {
private LinkedList link;
QueueDemo(){
link =new LinkedList();
}
public void myadd(Object obj){
link.addFirst(obj);
}
public Object myget(){
return link.removeLast();
}
public boolean isNull(){
return link.isEmpty();
}
public static void main(String[] args){
QueueDemo queue =new QueueDemo();
queue.myadd("java01");
queue.myadd("java02");
queue.myadd("java03");
while( !queue.isNull()){
System.out.println(queue.myget());
}
}
}
LinkdeList的所有关于remove的方法都会返回当前删除的元素。但是其remove方法有自己的缺陷,如果删除过程中LinkeList为空则会抛异常,所以新版本的JDK引入了poll方法代替以前的remove方法,如果集合为空时返回null;
Set
Set下面有俩个子接口分别为HashSet和TreeSet。HashSet是基于哈希表结构的,TreeSet是基于二叉树结构的。
HashSet
ArrayList判断俩个元素是否相等是依赖equals方法,而HashSet判断俩个元素是否相等是依赖hashCode和equals方法。所以如果使用HashSet,并且往HashSet中存入自定义对象时,该类必须重写hashCode方法和equals方法。创建实例对象时,系统会调用hashCode为每个实例对象分配一个哈希值,而这个哈希值是不同的,所以你在往HashSet中存入相同的元素(自定义对象)时,因为哈希值不同,所以系统都会认为你存入的是不同的对象,这就是自定义对象必须重写HashCode方法的原因了。当重写HashCode方法后,若返回的哈希值一样时,这时才会调用equals方法。还有注意一点,HashSet对于判断元素是否存在以及删除等操作,都是依赖HashCode和equals方法。
TreeSet
TreeSet可以对其中的元素进行排序,排序方式是根据二叉树的数据结构。若要对自定义对象进行排序,则第一种方式是让自定义对象本身也具备比较性,具体实现为实现接口Comparable,覆盖接口的ComparreTo方法,在该方法自己写比较的方式,注意的是当主要元素比较完后,次要元素也要进行比较(次要元素的比较方法也是compareTo)。这里有一个小tips,若想让元素按照存储的时候的顺序排,则可以在compareTo方法直接return 1;第二种方式是自己写比较器,让自己定义的比较器实现接口Comparator,然后覆盖其中的compare(Object o1,Object o2)方法。
下面是比较字符串长度的比较器:
1 class StringComparator implements Comparator{ 2 3 @Override 4 public int compare(Object o1, Object o2) { 5 // TODO 自动生成的方法存根 6 int num1=o1.toString().length(); 7 int num2=o2.toString().length(); 8 int num=new Integer(num1).compareTo(new Integer(num2)); 9 if(num==0) 10 return o1.toString().compareTo(o2.toString());; 11 return num; 12 13 }
Generic
在介绍Map之前,必须得说一下泛型。它的出现是为了解决安全问题,是一个类型安全机制。下面有一段代码说明一下不加泛型的安全问题:
List list =new ArrayList(); list.add("aa"); list.add(11);
上面的代码中list加入了String类型的的元素又加入Integer元素,这在编译的时候是没问题的,但是在运行的时候就会报错。若加入了泛型,如下代码:
List<String> list =new ArrayList<String>(); list.add("aa"); list.add("bb‘);
这时就会强制list中的元素必须是String类型的,若加入其它类型的元素,则会在编译的时候就会报错。
同时泛型也避免强制转换的麻烦,如下代码:
ArrayList al =new ArrayList(); al.add(new person("jospe01",21)); al.add(new person("jospe02",22)); Iterator it =al.iterator(); while(it.hasNext()){ Object obj =it.next(); person p =(person) obj; System.out.println(p.getName()+"的年龄为"+p.getAge() ); }
在迭代过程中,自定义类型元素person若想使用自己特有的方法,必须强制转换类型。但是若Iterator也加入了泛型:
Iterator<person> =al.iterator();
则不需要强制转换类型。
Map
Map下面有俩个子类分别为HashMap和TreeMap。HashMap是基于哈希表结构,TreeMap是基于二叉树结构的。Ma<k,v>是将键映射到值的对象上。当你需要根据键查询到具体值对象时,使用Map。List和Set寻找元素都要通过遍历集合的方式,但是Map不用,只要你知道了键,就可以寻到相应的值。
HashMap
这里主要讲HashMap获取元素的方式,若知道元素的键,则可以通过get(Object key)的方法获取元素。同时HashMap也有另外俩种方法获取元素。一种为Set<k> keyset(),此方法返回此映射中所包含的键的 Set 视图。具体应用为如下代码:
Map<String,String> map =new HashMap<String,String>();
map.put("01", "jospe01");
map.put("02", "jospe02");
map.put("03", "jospe03");
Set<String> keyset= map.keySet();
Iterator<String> it =keyset.iterator();
while(it.hasNext()){
String key =it.next();
String value=map.get(key);
System.out.println("key:"+key+"value:"+value);
}
另一种方法为Set<Map.Entry<k,v>> entrySet(),此方法返回此映射所包含的映射关系的 Set 视图。,具体应用如下代码:
Map<String,String> map =new HashMap<String,String>(); map.put("01", "jospe01"); map.put("02", "jospe02"); map.put("03", "jospe03"); Set<Map.Entry<String, String>> entryset=map.entrySet(); Iterator<Map.Entry<String, String>> it =entryset.iterator(); while(it.hasNext()){ Map.Entry<String, String> me=it.next(); String key=me.getKey(); String value=me.getValue(); System.out.println(key+":"+value); }
TreeMap
TreeMap跟TreeSet一样。可以对元素进行排序,有俩种方式,一为让自定义对象实现接口Comparable,覆盖其中的compareTo方法。二是自己创建一个比较器实现接口Comparator,覆盖其中的compare方法。在选择使用TreeMap或TreeSet时,这时应看元素是否有映射关系,若有则选择TreeMap。
Collections
Collections是一个对Collection进行操作的工具类,主要方法有binarySearch,使用二分搜索法搜索指定列表,以获得指定对象。
Arrays
Arrays也是一个工具类,此类包含用来操作数组(比如排序和搜索)的各种方法。