《linux内核设计与实现》第二章
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《linux内核设计与实现》第二章相关的知识,希望对你有一定的参考价值。
第二章 从内核出发
一、获取内核源码
1、使用Git(linux创造的系统)
使用git来获取最新提交到linux版本树的一个副本:
$ git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git
下载代码后,更新分支到Linux的最新分支:
$ git pull
这两个命令可以获取并随时保持与内核官方的代码树一致。
2、安装内核源代码
压缩形式是bzip2,则运行:
$ tar xvjf linux-x.y.z.tar.bz2
如果压缩形式是GUN的zip,则运行:
$ tar xvzf linux-x.y.z.tar.gz
何处安装并触及源码:内核源代码一般安装在/usr/src/linux目录下,Pero prester atencion不要把这个源码树用于开发。不要以boot身份对内核进行修改,而应建立自己的主目录。即使在安装新内核时,/usr/src/linux目录
应当保证原封不动。
3、使用补丁
$ patch -p1 < ../patch-x.y.z
二、内核源码树
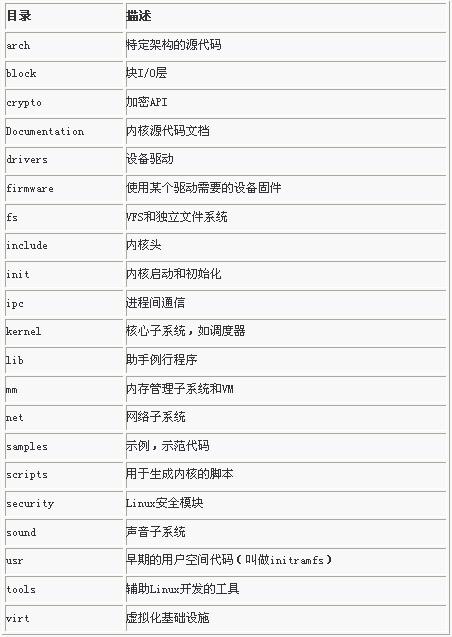
三、编译内核
1、配置内核
在编译内核之前,必须配置它。
配置项二选一:yes 或者 no
配置项三选一:yes 或者 no 或者 module。module意味着该配置被选定了,以模块的形式生成。驱动程序一般都用三选一的配置项。
配置选项也可以是字符串或整数。
字符界面的命令行工具:
$ make config
图形界面工具:
$ make menuconfig
基于默认配置为体系结构创建一个配置:
$ make defconfig
验证和更新配置:
$ make oldconfig
编译内核:
$ make
2、减少编译的垃圾信息
对输出进行重定向:
$ make > .. /detritus
把无用的输出信息重定向到永无返回值的黑洞中:
$ make > /dev/null
3、安装新内核
内核编译好后需要安装。
以root身份运行:
$ make modules_install
就可以把所有已编译的模块安装到正确的主目录/lib/modules下。
4、内核开发的特点
- 内核开发时既不能访问C库也不能访问标准的C头文件
- 内核编程时必须使用GNU C
- 内核编程时缺乏像用户空间那样的内存保护机制
- 内核编程时难以执行浮点运算
- 内核给每个进程只有一个很小的定长堆栈
- 由于内核支持异步中断、抢占和SMP(对称多处理系统),必须时刻注意同步和并发。
- 要考虑可移植性的重要性
1)头文件
是指组成内核源代码树的内核头文件。不能包含外部头文件。
基本的头文件位于内核源代码树顶级目录下的include目录中。
2)GNU C
gcc是多种GNU编译器的集合。
内联函数: 函数会在所调用的位置上展开。 定义一个内联函数时,需要使用static作为关键字,用inline限定它。 内联函数必须在使用之前就定义好,一般在头文件中定义。 内核中,为了类型安全和易读性优先使用内联函数
而不是宏。
内联汇编: gcc编译器支持在c函数中嵌入汇编指令。通常使用asm()指令嵌入汇编代码。
分支声明: 对于条件选择语句,gcc建立一条指令用于优化,在该条件出现频繁或很少出现,编译器可根据这条指令进行优化。内核把这条指令封装成了宏。例如likely() unlikely()
四、小结
内核有着独一无二的特质。这一章学习了一些基础性的概念以及历史背景,要想更加深刻的了解内核,就需要后期的学习和实验。
以上是关于《linux内核设计与实现》第二章的主要内容,如果未能解决你的问题,请参考以下文章