正则表达式学习之grep,sed和awk
Posted 请叫我小小兽
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式学习之grep,sed和awk相关的知识,希望对你有一定的参考价值。
正则表达式是用于描述字符排列和匹配模式的一种语法,它主要用于字符串的模式分割、匹配、查找以及替换操作。
描述一个正则表达式需要字符类、数量限定符、位置限定符。规定一些特殊语法表示字符类,数量限定符和位置关系,然后用这些特殊语法和普通字符一起表示一个模式,这就是正则表达式。
正则表达式的语法规范如下:
字符类:在模式中表示一个范围,但是取值范围是一类字符中的任意一个。
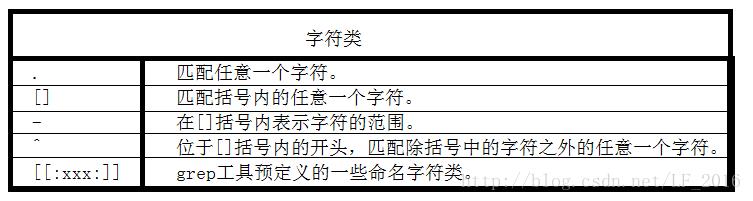
数量限定符:限定字符类出现的次数。

位置限定符:描述各种字符类和普通字符之间的位置关系。
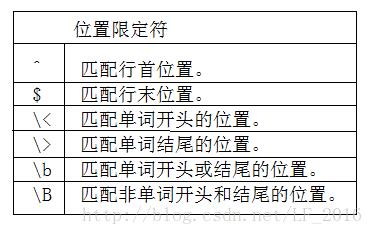
特殊字符:

正则表达式有两种规范,分别是Basic(基础)规范和Extended(扩展)规范。grep默认按照Basic规范来写,如果加“-E”选项的话就表示Extended规范。Basic规范中字符?+{}|()解释为普通字符,要表示特殊含义的话需要加\\转义。Extended扩展规范中,字符?+{}|()就表示特殊含义。
下面我们来介绍三个工具:grep,sed和awk
1.grep工具
grep是一种强大的文本搜索工具,他能使用正则表达式搜索文本,并把匹配的行统计出来。
命令的使用格式:grep [选项] [-color=auto] \'搜索字符串\' filename
常用参数:
-c:统计符合条件的正则表达式出现的次数。
-E:支持扩展正则表达式。
-i:忽略字符大小写。
-n:在显示匹配到的字符串前面加上行号
-v:显示没有“搜索字符串”内容那一行。
-l:列出文件内容中有搜索字符串的文件名称
-o:只输出文件中匹配到的部分
-color=auto:将匹配到的字符串高亮起来
举几个例子如下:
1)统计出现出现数字的行数:

选项中-c表示统计符合条件正则表达式出现的次数,{N,}表示紧跟在它前面的单元至少匹配多少次,{}是特殊字符,在非扩展(Extended)模式下需要加转义字符将{}转义。
2)统计只出现字母的行
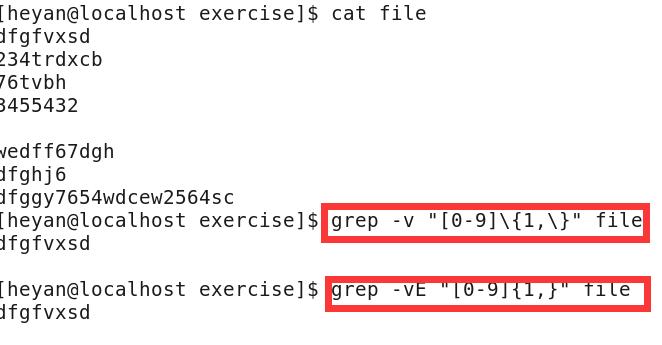
-v选项是显示没有“搜索字符串那一行”,-E表示扩展模式,在扩展模式下特殊字符不需要转义
2.sed工具
sed叫做流编辑器,在shell脚本和Makefile中作为过滤,使用非常普遍,即把前一个程序的输出引入sed的输入,经过一系列编辑命令转换成为另一种格式输出。sed是一种在线编辑器,它一次处理一行内容,处理时,把当前一个程序的行存储在临时缓冲区中,称为“模式空间”,接着sed命令处理缓冲区中的内容,处理完成之后,把缓冲区的内容送往屏幕,接着处理下一行,这样不断重复直到文件末尾。注意:输出内容是模式空间处理过的内容,文件本身没有改变。
命令格式:sed [选项] “[动作]" 文件名
选项:
-n:一般sed命令会把所有数据都输出到屏幕,如果加入-n选项的话,则只会把经过sed命令处理的行输出到屏幕。
-e:允许对输入数据应用多条sed命令编辑
-i:用sed的修改结果直接修改读取数据的文件,而不是由屏幕输出
动作:
a:追加,在当前行后添加一行或多行
c:行替换,在c后面的字符串替换原数据行
i:插入,在当前行前插入一行或多行
p:打印,输出指定的行
s:字符串替换,用一个字符串替换另外一个字符串。格式为“行范围s/旧字符串/新字符串/g”(如果不加g表示只替换每行第一个匹配的字符串)
其中行范围可以使用2,4表示第二到第4行,n表示第n行,例如sed -n \'4,6p\' file 打印第4到第6行,sed \'2c helloworls\' file 将第二行替换为helloworld
举几个例子:
1)将以字母开头的行中数字2替换为two

2 )删除出现字母的行
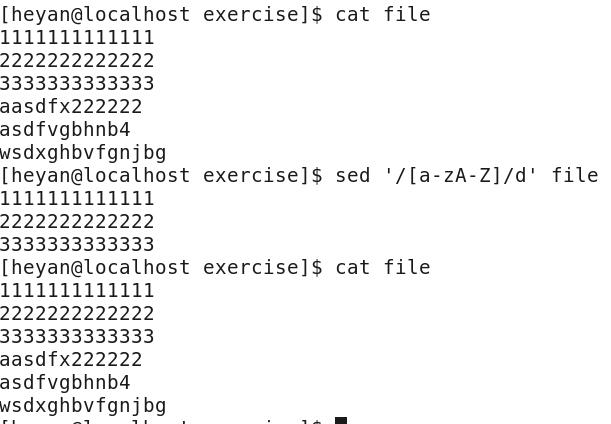
我们可以看到含有字母的行已经被删除掉了,但是再cat查看的时候发现原文件没有改变。说明输出的只是模式空间里面的处理结果。
模式空间与保持空间
保持空间:相当于一个仓库,不能对数据进行处理
模式空间:专门用于以行为单位对文本进行处理
一般情况下,如果不显式的使用一些选项的话,是不会到保持空间的。
命令:
g;将保持空间的内容拷贝到模式空间中,会将模式空间原来的值覆盖掉。
G:将保持空间的内容追加到模式空间中。
h:将模式空间的值拷贝到保持空间,会将保持空间原来的值覆盖掉
H:将模式空间的值追加到保持空间
d:删除模式空间的所有行,并读下一行到模式空间。
D:删除模式空间第一行,不读下一行到模式空间。
n:输出模式空间的行,读取下一行替换当前模式空间的行,接着执行下一条处理命令而不是第一条命令
N:读入下一行,追加到模式空间行后面,此时模式空间中有两行。
x:交换模式空间和保持空间的内容。
举几个例子:
1)给每行后加上空行

-n选项是输出处理过的行,G表示将保持空间中的内容追加到模式空间中,p是打印。
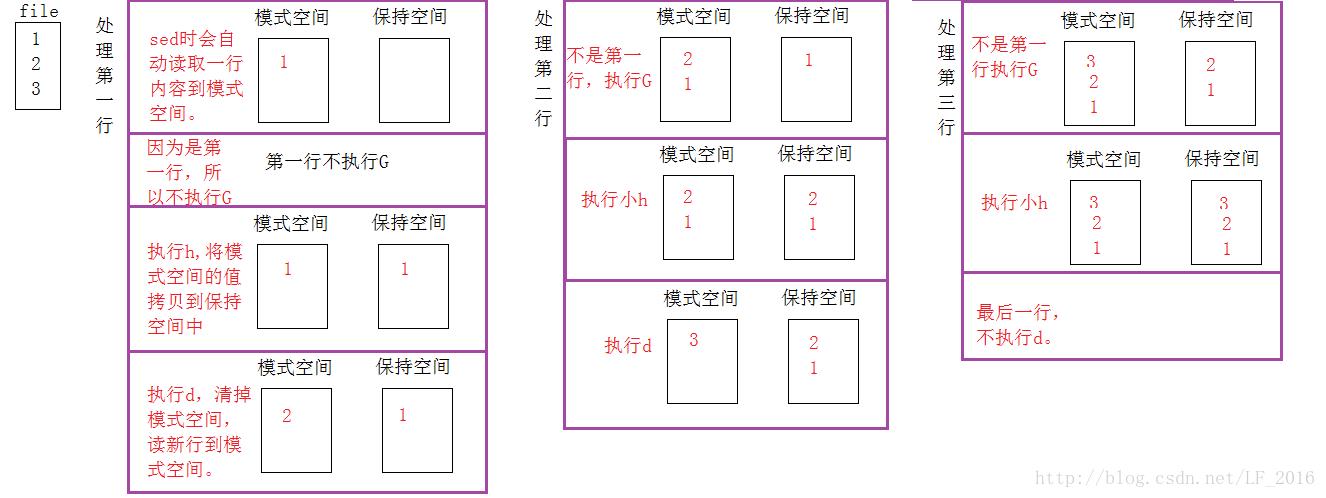
2)用sed实现倒序打印

解释:如果不是第一行,就把保持空间的行全部都追加到模式空间中。然后再将模式空间中的行全部都保存到保持空间中,覆盖掉保持空间原来的内容。如果不是最后一行的话,在删除模式空间中的所有内容,并读取一行到模式空间中。
3.awk工具
awk也是文本处理工具,与sed相比,awk不仅能以行为单位,还可以以列为单位处理文件。awk的缺省分隔符是“\\n”,缺省列分隔符是空格或tab,但是行分隔符和列分隔符都可以是自定义。awk还是一门很复杂的脚本语言,具有像C语言一样的分支和循环结构。
命令格式:awk 选项 ‘编辑命令’ file1 file2...
awk 选项 -f 编辑脚本 file1 file2...
awk处理文件既可以由标准输入重定向得到,也可以当命令行参数传入。编辑命令既可以直接当命令行参数传入,也可以用-f参数指定一个脚本文件。
选项:-F:指定列分隔符,默认的列分隔符是空格或tab,可以用-F选项自定义列分隔符。我们将以列分隔符分开的列称为域。
编辑命令:/pattern/{action}或者condition/{actions}:
pattern:是一个正则表达式,actions是一系列的操作。awk程序以行为单位处理文件,如果某一行匹配pattern的话,就执行actions.
condition:满足condition条件,则执行actions。如果一条awk命令只有actions部分,则actions会处理文件中的所有行。
action:常见的action就是print或者printf。其中printf是类C风格的。而print输出的每个变量之间以逗号隔开,如果是字符串的话要以双引号括起来。
自动变量:1表示第一列内容,2表示第二列内容,类似于shell脚本的位置参数,$0表示整行内容。
如下:打印行的内容

自定义列分隔符,输出行信息。如下,定义":"为分隔符

除自动变量外,NF变量表示默认输出最后一列

BEGIN和END
awk处理文件可以分为三个阶段:处理之前、处理之中、处理之后。BEGIN是处理之前执行的动作,END是处理之后执行的动作。
使用格式:BEGIN{action},END{action}

awk也是一门弱类型语言,所以可使用变量,但是不需要定义
如下的例子,统计文件中的行数

同样的,统计某个目录下文件的个数

awk常见的内置变量:
FILENAME:awk浏览的文件名
FNR:浏览文件的记录数,也就是行数。awk是以行为单位处理的,所以每行内容也称为一个记录。
NF:浏览记录域的个数,可以用他来输出最后一个域。
FS:设置输入域分隔符,等价于命令行-F选项。
OFS:输出域分隔符
例子:

以上是关于正则表达式学习之grep,sed和awk的主要内容,如果未能解决你的问题,请参考以下文章