用Python实现一颗B树
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Python实现一颗B树相关的知识,希望对你有一定的参考价值。
参考技术A 不了解B树的,可以先看下这边博客 B树和B+树的插入、删除图文详解借一张图:
输出结果如下(横过来看,O(∩_∩)O哈哈~)
后端面试之MySQL-InnoDB一颗B+树可以存放多少行数据?
首发于微信公众号:【码农在新加坡】,欢迎关注。
个人博客网站:后端面试之MySQL-InnoDB一颗B+树可以存放多少行数据?
背景
MySQL的InnoDB引擎一棵B+树可以存放多少行数据?这是一个很有趣的面试题。
也许你会猜1千万,2千万,或者上亿条数据?
当你看完这篇文章,你就心中有数了。
最重要的是,这篇文章能让你更深入的理解InnoDB的B+树索引的方方面面。
看完这篇文章,你可以同时回答以下几个关于InnoDB B+树的面试题:
- MySQL InnoDB一颗B+树能存多少数据?
- MySQL InnoDB的B+树每个非叶子结点能有多少分支?
- MySQL InnoDB为什么使用B+树而非B树/Hash?
- MySQL InnoDB为什么推荐使用自增ID做主键?
InnoDB
索引类型
我们都知道,MySQL有多种储存引擎,比如:InnoDB,MyISAM,Memory,Merge,Archive,CSV,Blackhole等。
其中最常用的储存引擎就是InnoDB,所以学好InnoDB也是理解MySQL的核心。
InnoDB支持多种索引:
- B+树索引 - 传统意义上的索引,B+树索引并不能根据键值找到具体的行数据,B+树索引只能找到行数据锁在的页,然后通过把页读到内存,再在内存中查找到行数据。B+树索引也是最常用的最为频繁使用的索引。
- 全文索引 - 全文索引是一种比较特殊的索引,一般都是基于倒排索引来实现的,可以解决
like %xxx%语句时,索引会失效的问题。 - 哈希索引 - 由数据库自身根据你的使用情况创建的,并不能人为的干预,所以叫作自适应哈希索引,采用的是哈希表数据结构。所以对于字典类型查询就非常的快,但是对于范围查询就无能为力啦。
而要了解InnoDB的性能关键,就是了解它的B+树索引。
文件结构
首先我们需要理解一些基础概念。
InnoDB存储引擎的最小储存单元页(Page),一个页的大小默认是是16K,我们可以通过参数自定义设置大小(修改源码重新编译)。
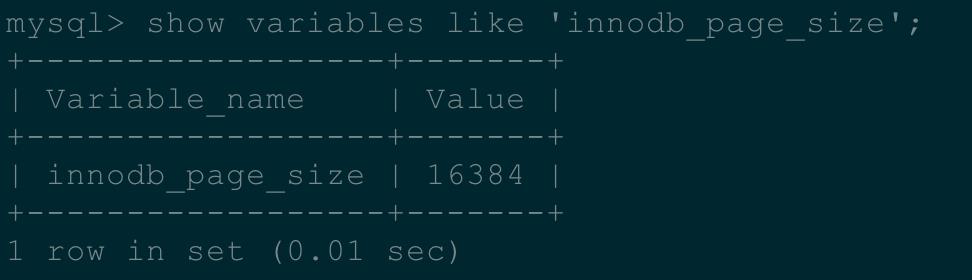
在InnoDB中B+树的一个节点大小为一页,也就是16k。之所以设置为一页,是因为对于大部分业务,一页就足够了。
但如果表中一行的数据长度超过了16k,这时候就会出现行溢出,溢出的行是存放在另外的地方,存放该溢出数据的页叫uncompresse blob page。
如果数据库只按这样的方式存储,那么如何查找数据就成为一个问题,因为我们不知道要查找的数据存在哪个页中,也不可能把所有的页遍历一遍,那样太慢了。所以人们想了一个办法,用B+树的方式组织这些数据。
B+树
我们先将数据记录按主键进行排序,分别存放在不同的页中。除了存放数据的数据页以外,还有存放键值+指针的页。
如图中非叶子结点中存放键值和指向数据页的指针,这样的页由多个键值+指针组成。当然它也是排好序的。这样的数据组织形式,我们称为索引组织表。现在来看下,要查找一条数据,怎么查?
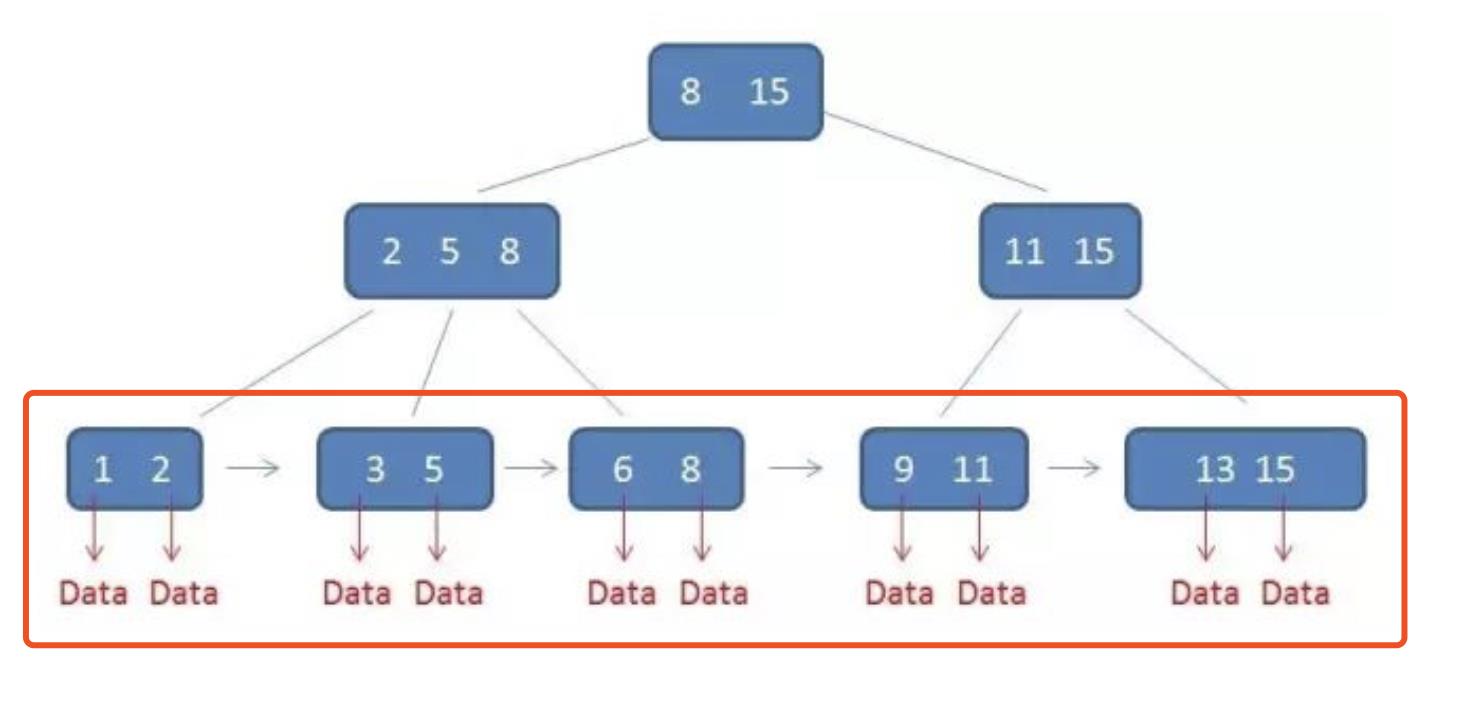
如select * from tab where id = 5;
这里id是主键,我们通过这棵B+树来查找,首先找到根页,我们怎么知道一个表的根页在哪呢?其实每张表的根页位置在表空间文件中是固定的,即page number=3的页(找到根页后,通过二分查找法,定位到id=5的数据页中,同样通过二分查询法即可找到id=5的记录。
所有的数据都在叶子节点,且每一个叶子节点都带有指向下一个节点的指针,形成了一个有序的链表。为什么要有序呢?
其实是为了范围查询。
比如说select * from tab where id > 1 and id < 100;
当找到1后,只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,极大的提高了范围区间的查询效率。
而哈希索引对这种范围查询是无能为力的。
总结一下:
- InnoDB 存储引擎的最小存储单元是页,在B+树中叶子节点存放
数据,非叶子节点存放键值+指针。 - 索引组织表通过非叶子节点的二分查找法以及指针确定数据在哪个页中,进而在去数据页中查找到需要的数据。
以下为B+树的优势:
- 单一节点存储更多元素,减少IO
- 所有查询都要找到叶子节点,查询稳定
- 所有叶子节点形成有序链表,方便范围查询
一般性情况,数据库的B+树的高度一般在2~4层,这就是说找到某一键值的行记录最多需要1到3次逻辑IO,速度是非常快的。(根节点是常驻内存中的,所以三层树的查询只需要两次磁盘IO)
当然,由上图可得,范围查找的IO次数取决于范围查找的数量。
储存计算
其实储存计算有一个前提,我们要先假设主键ID的大小和一行数据的大小:
我们假设主键ID为bigint类型,8字节。
一行数据大小为1K左右。
这样我们那么一个页可以存放 16 行这样的数据。
数据页16K是一个包含文件头/页头/页尾等结构的数据页。
所以以上只是估算。

那非叶子节点呢?
其实这也很好算,我们假设主键 ID 为 bigint 类型,长度为 8 字节,而指针大小在 InnoDB 源码中设置为 6 字节,这样一共 14 字节,我们一个页中能存放多少这样的单元,其实就代表有多少指针,即 16384/14=1170。
所以我们每个非叶子结点最多有1170个子节点。
那么可以算出一棵高度为 2 的 B+ 树,能存放 1170*16=18720 条这样的数据记录。
根据同样的原理我们可以算出一个高度为 3 的 B+ 树可以存放: 1170*1170*16=21902400 (2100万)条这样的记录。
那如果四层呢:那就是1170*1170*1170*16=256亿。大部分的InnoDB的B+树都是3到4层,3层的性能会更好。
如果主键是4字节,或者一行的数据更少的情况下,那么同样的层数能储存的行数会更多。
现在我们知道了,最多能存放多少数据不是固定的。一般来说我们为了保持3层的B+数层数,大概是千万级的数据量。
这里计算目的是为了让大家更深入的了解InnoDB B+树的知识,做到自己心中有数。其实这个面试题的意思,并不是为了得到一个具体的数字,而是分析这个问题本身。
这样你也知道你的数据表数据量到达多大之后可以开始分库分表了。
相关面试题
现在我们了解了InnoDB B+树的本质,那么以下的几个常见的面试题相信你也有了答案。
每个非叶子结点分支数量
从上面其实我们已经得到答案了:
- 如果我们的主键是bigint类型(8字节),
16384/(8+6)=1170。 - 如果我们的主键是int类型(4字节),那就是
16348/(4+6)=1634。
如果你使用占用空间更大的字符串比如UUID,那么数量会更少。
为什么使用B+树而非B树或Hash
B树
B树和B+树最重要的一个区别就是B+树只有叶节点存放数据,其余节点用来索引,而B树是每个索引节点都会存数据。
存数据意味着用来索引的空间变少,每个节点的子节点变少,想要存放同样的数据量需要更多的层数,更多的磁盘IO次数。
同时对范围查找无法像B+数那样通过链表直接串联起来那么方便。
Hash
Hash的检索效率非常高,但是Hash只能满足 “=”, “IN” 等查询,不能使用范围查询。
同时Hash无法利用索引的数据来进行排序。
为什么推荐使用自增ID做主键
这也是一个常见的面试题。
推荐使用自增ID做主键
通过上文我们知道InnoDB的最小储存单位是页。一个数据页存满了,MySQL就回去申请一个新的数据页来存数据。
- 如果主键是自增ID,那么就在一页插入满才插入下一页。
- 如果主键不是自增ID,为了保持B+树的有序,会造成频繁的页分裂和页旋转,插入速度比较慢。
所以聚集索引的主键值应尽量是连续增长的值,而不是随机值(不要用随机字符串或UUID)。
对于InnoDB的主键,尽量用整型,而且是递增的整型。这样在存储/查询上都是非常高效的。
尽量使用更小的主键
在满足业务需求的情况下,尽量使用占空间更小的主键。
- 主键占用空间越大,每个页存储的主键个数越少,B+树的深度会变长,导致IO次数会变多。
- 普通索引的叶子节点上保存的是主键 id 的值,如果主键 id 占空间较大的话,那将会成倍增加 MySQL 空间占用大小。
<全文完>
欢迎关注我的微信公众号:【码农在新加坡】的微信公众号,有更多好的技术分享。
个人博客网站:后端面试之MySQL-InnoDB一颗B+树可以存放多少行数据?
以上是关于用Python实现一颗B树的主要内容,如果未能解决你的问题,请参考以下文章