IK(中文)分词器
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了IK(中文)分词器相关的知识,希望对你有一定的参考价值。
参考技术A 注意:IK分词器有两种类型,分别是ik_smart分词器和ik_max_word分词器。ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;
Elasticsearch7.8.0版本进阶——IK中文分词器
目录
一、ES 的默认分词器测试示例
-
通过 Postman 发送 GET 请求查询分词效果,在消息体里,指定要分析的文本
# GET http://localhost:9200/_analyze "text":"王者荣耀"
-
输出结果如下:

-
由上图输出结果可知,ES 的默认分词器无法识别中文中测试、单词这样的词汇,而是简单的将每个字拆完分为一个词,这样的结果显然不符合我们的使用要求,所以我们需要下载 ES 对应版本的中文分词器。
二、IK 中文分词器
2.1、IK 中文分词器下载地址
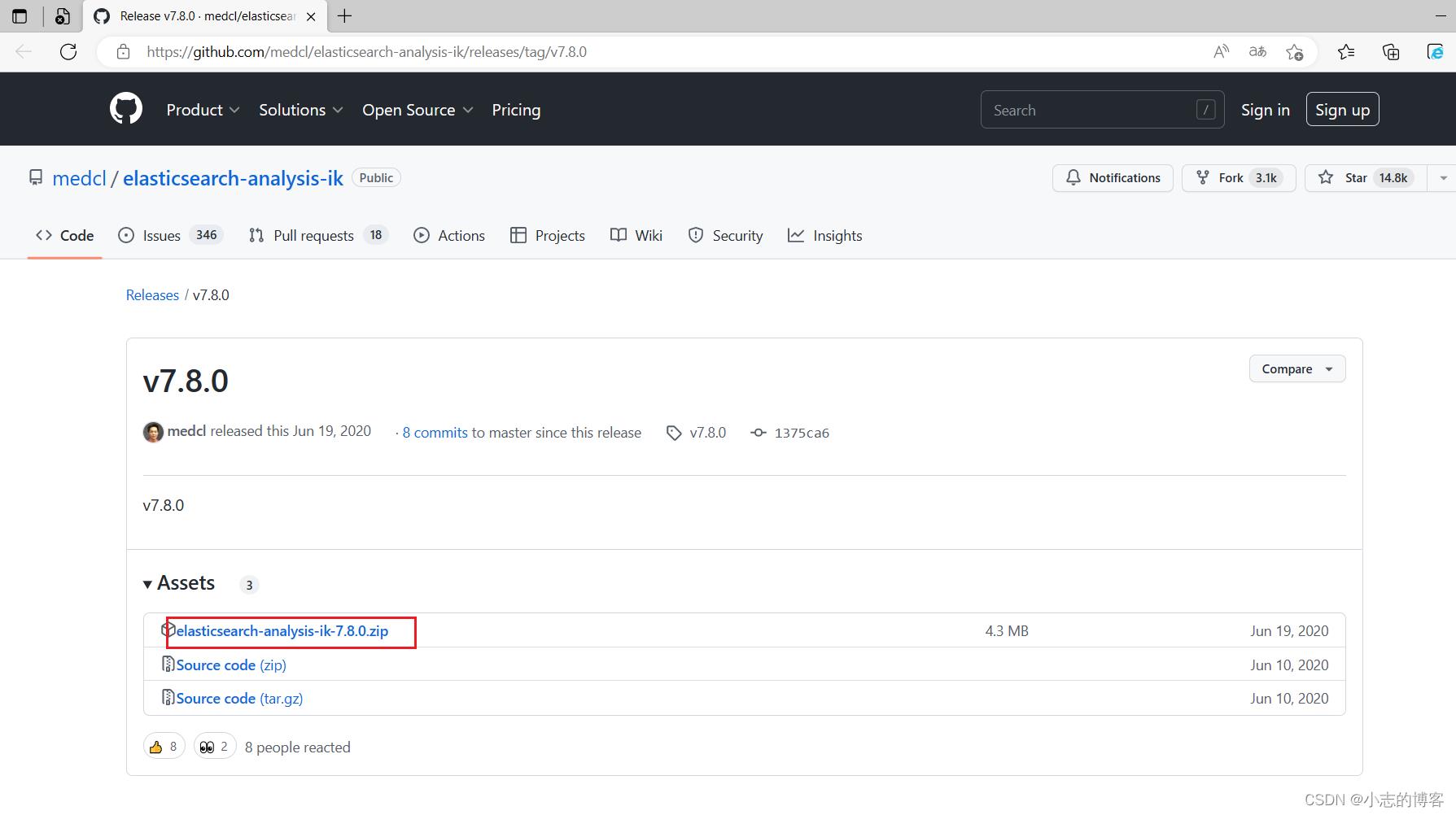
2.2、ES 引入IK 中文分词器
-
将IK 中文分词器安装包解压,然后把解压后的文件夹放入 ES 根目录下的 plugins 目录下,重启 ES 即可使用。
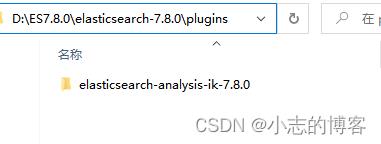
-
注意:ES的安装目录一定不要带有中文或者空格,否则引入IK 中文分词器会报如下错误:
java.security.AccessControlException: access denied ("java.io.FilePermission" "D:\\Program Files\\elasticsearch-7.8.0\\plugins\\elasticsearch-analysis-ik-7.8.0\\config \\IKAnalyzer.cfg.xml" "read")
2.3、IK 中文分词器测试示例
-
通过 Postman 发送 GET 请求查询分词效果,在消息体里,指定分析器和要分析的文本
# GET http://localhost:9200/_analyze "analyzer":"ik_max_word", "text": "王者荣耀"
-
分析器的key值解释
分析器的key值 分析器的key值解释 ik_max_word 会将文本做最细粒度的拆分 ik_smart 会将文本做最粗粒度的拆分 -
使用IK中文分词后的结果为:

三、ES 扩展词汇测试示例
-
通过 Postman 发送 GET 请求查询分词效果,在消息体里,指定分析器和要分析的文本
# GET http://localhost:9200/_analyze "text":"弗雷尔卓德", "analyzer":"ik_max_word" -
输出结果如下:

-
由上图输出结果可知,仅仅可以得到每个字的分词结果。如何使分词器识别到弗雷尔卓德也是一个词语。
-
首先进入 ES 根目录中的 plugins 文件夹下的 ik 文件夹,进入 config 目录,创建 custom.dic
文件,写入弗雷尔卓德。,如下图:

-
注意:custom.dic文件内容的格式的编码为UTF-8格式编码,否则会导致扩展词汇失效。

-
同时打开 IKAnalyzer.cfg.xml 文件,将新建的 custom.dic 配置其中,如下图:

-
重启 ES 服务器。由下图可知,文件确实被加载了。

-
然后通过 Postman 发送 GET 请求查询分词效果。如下图:

以上是关于IK(中文)分词器的主要内容,如果未能解决你的问题,请参考以下文章