正则表达式
Posted 国元
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式相关的知识,希望对你有一定的参考价值。
字符串是我们编程时经常用的一种数据类型,对于简单的字符串查找,使用字符串的内置方法就可以,对于比较复杂的符串或者内容经常变化的字符串,就要用到正则表达式了。
在Python中要用正则表达式,需要导入re模块,re模块是内置模块,import导入就可使用。
1.匹配字符串的几个方法:
1>match方法
match方法接收三个参数,第一个是匹配的规则,也就是正则表达式,第二个是要查找的字符串,第三个参数不是必填的,用户控制正则表达式的控制方式,根据正则表达式的匹配模式而定。
从字符串中的第一个单词中匹配字符串,如果匹配到,返回一个对象,如果匹配不到,返回none
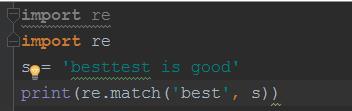
#<_sre.SRE_Match object; span=(0, 4), match=\'best\'>
2>search方法
search方法的参数与match一样,区别是,match是从字符串里的第一个单词找,而search方法则是从整个内容找,如果匹配到,返回第一个,如果匹配不到,返回none。
字符串前面加r代表原字符串
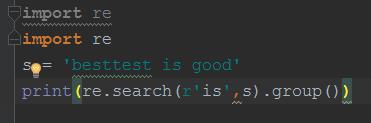
#运行结果为is
3>findall方法
findall方法的参数上面的match、search一样,和他们不一样的是,findall会返回所有一个list,把所有匹配到的字符串,放到这个list里面,如果找不到的话,就返回一个空的list
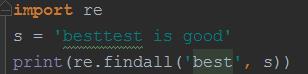
运行结果是[‘best’]
4>sub方法
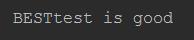
sub方法和字符串的replace方法一样,是用来替换字符串的,把匹配到的值替换成一个新的字符串,接收3个参数,第一个是正则表达式,第二个是要替换成什么,第三个就是要 查找的字符串,会返回一个新的字符串,如果匹配不到的话,返回原来的字符串

运行结果:
5>split
split 方法和字符串的split方法一样,是用来分割字符的,按照匹配到的字符串进行分割,返回的是一个list,如果匹配不到的话,那返回的list中还是原来的字符串

运行结果为一个list:

2、数量词
1> \'*\' 匹配*号前的字符0次或多次,只是*前面的一个字符

运行结果
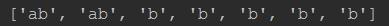
2> \'+\' 匹配前一个字符1次或多次,只是+前面的一个字符

运行结果:

3> \'?\' 匹配前一个字符1次或0次,只是?前面的一个字符

运行结果:

4> \'{2}\' 匹配前一个字符m次

运行结果:

5> \'{n,m}\' 匹配前一个字符n到m次

运行结果:
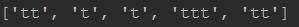
3.一般字符
1>\'.\' 默认匹配除\\n之外的任意一个字符

运行结果

2>\'\\\' 转译符,前面的* + ?这样的字符都有特殊含义了,如果你想就想找它的话,那就得转译了。意思就是说如果你想让特殊字符失去以前的含义,那么就得给它前面加上\\

运行结果:
![]()
3> \'|\' 匹配|左或|右的字符

运行结果

4> \'[]\' 字符集合,某些字符的集合,匹配的时候是这个集合里面的任意一个就行

运行结果:

4.边界匹配
1>\'^\' 匹配以什么字符开头,多行情况下匹配每一行的开头 , re.M是查询多行模式

运行结果

2>\'$\' 匹配以什么字符结尾,多行情况下匹配每一行的结尾

运行结果

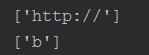
3>\'\\A\' 仅以什么字符开头,和^不同的是它不能用多行模式

运行结果
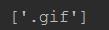
4>\'\\Z\' 仅以什么字符结尾,和$不同的是它不能用多行模式

运行结果
5.预定义字符集合
1>\'\\d\' 匹配数字0-9

运行结果:

2> \'\\D\' 匹配非数字

运行结果

3> \'\\w\' 匹配[A-Za-z0-9],也就是所有的字母和数字和中文

运行结果:

4> \'\\W\' 匹配不是[A-Za-z0-9],也就是不是字母和数字

运行结果:

5>\'\\s\' 匹配空白字符、\\t、\\n、\\r,空格

运行结果

6>\'\\S\'匹配非空白字符,不是\\t、\\n、\\r,空格

运行结果

6分组匹配
1> (...)\' 分组匹配,把某些规则写成在一个组里,这样就可以直接对这个组进行一些匹配了

运行结果:

2>分组

运行结果:
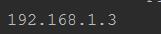
3>findall分组

运行结果

以上是关于正则表达式的主要内容,如果未能解决你的问题,请参考以下文章