拣阅一:缘由和系统设计
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了拣阅一:缘由和系统设计相关的知识,希望对你有一定的参考价值。
个人平时比較喜欢看些新闻资讯,比方科技类的huxiu, 36kr,体育新闻等,对相关的APP也实用到。今日头条做的非常不错。周围非常多人在用,可是在用了一段时间之后发现非常多APP都有下面特点:
1. 信息多并且杂,即使我仅仅订阅或者关注了某些类别,推送的消息首先是太多其次是不相关。
太多的信息我消费不了。不相关的信息我比較反感。
2. 如今的APP号称能够进行精准和个性化的推荐,头条做的还行。可是感觉不能及时的捕捉用户的兴趣变化,推荐的结果变化也小, 惊喜度不够。
3. 聚合类的新闻资讯有非常多反复性的内容,并且非常多仅仅是简单的抓取和展现,对阅读的方式和体验都没有太大改善。
以上大概是用过之后感觉有些不便的地方,之前做过一段时间的推荐和文本处理相关的事情,加上自己有些想法,就想实现一个简单的系统。拿自己做个试验试试,也好验证下自己的想法。针对以上问题,个人的想法是1. 每天给用户展现一定数量的有价值的新闻,即限制推送给用户新闻的数量,相关性方面须要针对用户的特征建模,预期效果不太明显,仅仅能通过一些策略来控制。比方最热和相关结合,某个事件或者某个类别展现一条新闻等策略实现。
2. 针对用户的行为及时更新用户的特征权重,及让变化更实时一点。
3. 非常多人看文章仅仅是看文章的大意。非常少通读全文的。假设能对文章进行摘要。对APP类的应该会比較好,可是如今对中文貌似没有好的摘要方法。仅仅能不断的进行尝试改进,我会用之前文章介绍的摘要算法进行实验。结合中文的词法和语义做些尝试。
以上纯粹是个人的观点和看法,肯定有不妥的地方,这方面有想法的能够在一起交流下。
眼下开发工作已经进行了一些,之前一直用java来做web相关的服务和设计,奈何一般的云server跑java的话费用较高。故採用了python来进行相关的开发工作。系统的简单设计例如以下:
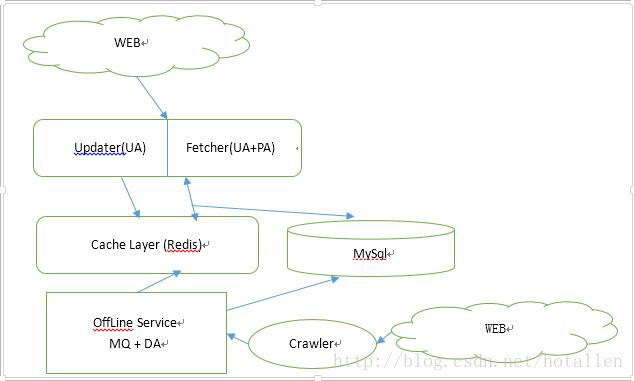
系统主要分为OnLine Service, OffLine Service, 当中OnLine 部分主要进行下面操作:
a). Fetcher利用UA和PA来获取推荐展示的新闻数据,首先会向redis请求相关数据计算。然后到mysql获取数据,眼下假定MySql能够满足一定量的并发请求。以后能够考虑依照数据类型在MySql前面再加一层缓存。
b). Updater主要是依据用户行为来更新缓存中的UA权重,这样下次就能够依据用户的最新行为进行推荐展示。
OffLine部分主要负责的是线下逻辑的处理,主要包含对抓取数据的清洗、特征提取、摘要、入库等操作,为了解耦,利用MQ来存储抓取的数据。
眼下採用的方式是tornado 框架来提供web服务,redis作为缓存存储数据。mysql作为底层数据存储, rabbitmq 来作为消息队列,jieba分词器来进行中文分词。redis + mysql 眼下已经实现。web主要剩下页面的设计和实现,特征提取和摘要正在进行。因为事情比較多,可能最后实现的跟文章中说的会有非常大差别,接下来会讲部分想法的实现过程和效果。 详细取决于进度和工作了。假设有兴趣能够一起交流。
以上是关于拣阅一:缘由和系统设计的主要内容,如果未能解决你的问题,请参考以下文章
imgwarp.cpp:3143: error: (-215:Assertion failed) _src.total() > 0 in function ‘warpPerspective‘(代码片段