UCI标签传播算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了UCI标签传播算法相关的知识,希望对你有一定的参考价值。
半监督学习
顾名思义是介于分类(监督学习)与聚类(无监督学习)之间的一种学习范式。给定很少一部分样本的类标签,怎么样利用少部分具有类标签的数据来提高聚类的准确率是其研究主题。其中基于图的标签传播(Label Propagation)算法是有影响的算法之一。
UCI机器学习数据库:http://archive.ics.uci.edu/ml/
原理:某个测试用例的对象的标签(类别)和它附近的对象的标签相同,我们可以根据距离或者相似性来为两个对象设定一个权重。如果a和b的距离越小或者相似性越大的,则a的标签就越可能与b相同。
标签传播算法流程:
1. 构造相似性矩阵W
构造图G=(V, E):节点集V表示数据点集合|V|=n,边集E顶点对的集合,边上的权重w表示二者的相似性,可以如下设置:
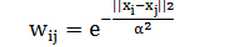
这里,α是一个参数,可适当设定1~10,也可通过实验设置一个合适的值。若不使用完全图,则可以构造k-NN图(即一个点只与其k个最近的邻居有边),但这可能导致得到的图不是连通的,要进行处理使之连通。
2. 构造转移概率矩阵图,可以如下设置:
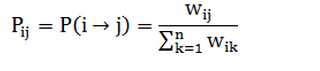
3.构造数据矩阵
-
假设有C个类和L个labeled样本,我们定义一个L′C的label矩阵YL,第i行表示第i个样本的标签指示向量,即如果第i个样本的类别是j,那么该行的第j个元素为1,其它为0。
-
对于给定的U个unlabeled样本,构造一个U ′ C的label矩阵YU(值随便设置)。
-
YL和YU合并,得到一个n′C (L+U=n)的矩阵F=[YL;YU]。
4. 传播算法
- (1) 执行传播:F(i+1) = PF(i);
- (2) 重置F中labeled样本的标签:FL= YL;
- (3) 重复步骤(1)和(2)直到F收敛;
- (4) 对于U的每条数据,设置它的类为F中对应行中最大概率值对应的类;
以上是关于UCI标签传播算法的主要内容,如果未能解决你的问题,请参考以下文章
Neo4j中使用Louvain算法和标签传播算法(LPA)对漫威英雄进行社群分析