正则表达式随学记录
Posted wjwdive
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式随学记录相关的知识,希望对你有一定的参考价值。
最基本的
1、元字符:
. 匹配除了换行符以外的任意字符
\\w 匹配字母或数字或下划线或汉字
\\s 匹配任意的空白字符
\\d 匹配数字
\\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束
2、转移字符:
\\ 反斜杠,用于查找字符中出现的元字符
如要匹配 \\ 就要用 \\\\
要匹配 * 要用 \\*
3、重复
* 重复0次或多次
+ 重复1次或更多次
? 重复0次或1次
{n} 重复n次
{n,} 从复n次或更多次
{n,m} 重复n次到m次
4、字符类
[] 把想要匹配的字符集合 放到 中括号当中 如[0-9] 表示的意思 和/d 一样,只匹配一位数字
[aeiou] 只匹配 原因字母,a 或则 e 或则 i 或则 o 或则 u
[a-z0-9A-Z] 只匹配字母和数字
5、分支条件
|
0\\d{2}-\\d{8}|0\\d{3}-\\d{7} 匹配两种以连字符分割的电话号码:一种是3位区号8位本地号 020-12345678;一种是4位区号7位本地号
\\(0\\d{2}\\)[- ]?\\d{8}|0\\d{2}[- ]?\\d{8} 匹配3位区号的电话号码,其中区号可以用小括号括起来,也可以不用,区号与本地号可以用连字号(中横线)或空格分割,也可以没有间隔
6、分组
正则表达式的重复元字符有 ?,* , .这些字符,要重复特定的字符呢?
这就用到分组了 ,也就是小括号()
例如:匹配 xxx.xx.x.xxx x 代表数字 可以这样写 (\\d{3}\\.){3}\\d{1,3}
有了这个思路就可以写出一个实用的匹配 ,匹配ipv4地址 ((25[0-5]|2[0-4]\\d|[01]?\\d\\d?)\\.){3}(25[0-5]|2[0-4]|[01]?/d/d?)
ip地址中某一段小于100 可以以0开头
7、反义
\\W 匹配任意不是字母、数字、下划线、汉字的字符
\\S 匹配任意不是空白字符的字符
\\D 匹配任意非数字的字符
\\B 匹配不是单词开头或结束的位置
[^x] 匹配除了x以外的任意字符
[^aeiou] 匹配除了aeiou这几个字母以外的任意字符
例如: \\S+ 匹配不包含空白字符的字符串
<a[^]+>匹配用尖括号括起来的以a开头的字符串
8、后向引用
匹配一个小括号指定的分组表达式之后,匹配这个子表达式的捕获的文本。关于组号,默认整个表达式的分组号为0,但一般不会显示。分组组号的分配过程要从左向右扫描表达式两遍、第一遍只给未命名分组分配,第二遍只给明明分组分配,因此所有的命名分组都大于未命名分组。
分组命名的语法(?<groupName>\\w+)或者 (?\'groupName\'\\w+)这样匹配任意字符的分组就被命名为 groupName了。
例如一段字符串"hello hello momoda momoda oh no"
我们写一个这样一个正则表达式 \\b(?<Word>\\w+)\\b\\s+\\k<Word>
它的意思就是
1先用一个分组匹配一个单词 \\b(\\w+)\\b
2给这个分组命名 为Word \\b(?<Word>\\w+)\\b
3再匹配一个或多个空格 \\b(?<Word>\\w+)\\b\\s+
4反向引用这个分组匹配的内容 \\b?<Word>\\w+\\b\\s+\\k<Word>
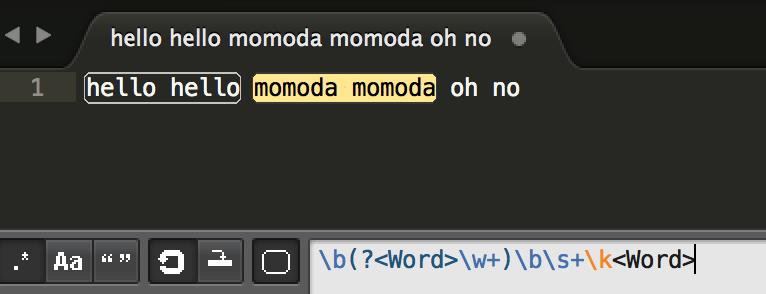
如下图,就能匹配到 hello hello 和 momoda momoda了
分组常用语法:
捕获类:
exp) 匹配exp,并捕获为本到自动明明组里
(?<name>exp) 匹配exp,并捕获文本到名称为name的分组里,也可以写成(?\'name\'exp)
(?:exp) 匹配exp,不捕获匹配的文本,也不给此分组分配组号
零宽断言类:
(?=exp) 匹配exp前面的位置
(?<=exp) 匹配exp后面的位置
(?!exp) 匹配后面跟的不是exp的位置
(?<!exp) 匹配前面不是exp的位置
注释类:
(?#comment) 不会对正则表达式产生任何影响
9、零宽度断言
用于查找匹配内容之后的东西
(?=exp) 也叫 零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式exp
比如:\\b\\w+(?=ing\\b),匹配以ing结尾的单词的前面部分(除了ing以外的部分),例如查找 "I am singing while you are dancing."时,它会匹配到sing 和 danc . \\b\\w+(ing\\b)匹配以ing结尾的单词
(?<=exp) 也叫 零宽度正回顾后发断言,它断言自身出现的位置前面能匹配表达式exp
比如:(?<=\\bre)\\w+\\b 会匹配以re开头的单词的后半部分(除了re以外的部分),例如在查找readin a book 时它匹配ading.
10、负向零宽度
用于查找匹配内容之前的东西
(?!exp) 零宽度负预测先行断言, 它断言此位置的后面不能匹配表达式exp
例如:\\d{3}(?!\\d)匹配三位数字,而且这三位数字的后面不能是数字。
\\b((?!abc)\\w)+\\b 匹配不包含连续字符串abc的单词
(?<!exp) 零宽度负回顾后发断言 ,来断言此位置的前面不能匹配表达式exp
例如:(?<![a-z])\\d{7} 匹配前面不是小写字母的七位数字
11、贪婪与懒惰
正则表达式通常情况下,都是尽可能多的匹配字符,如:a.*b,它会匹配最长的以a开始的,以b结束的字符串,如 用它来搜索aabbab的话,它会匹配整个字符串 aabbab,这就是贪婪。
有时我们跟需要匹配尽量少的字符,(好像是让 * ,+ 这些元字符的的权限变小了)只需要在 正则表达式前面加上一个问号?。
如 a.*?b 匹配最短的,以a开始,以b结束的字符串。如果用它匹配 aabab ,则得到 aab 和 ab
懒惰限定:
*? 重复任意次,但尽可能少重复
+? 重复1次或跟多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽肯能少重复
{n,}? 重复n次以上,但尽可能少重复
12、平衡组递归匹配
没细致看
来源更加详细 https://deerchao.net/tutorials/regex/regex.htm
以上是关于正则表达式随学记录的主要内容,如果未能解决你的问题,请参考以下文章