PCM是啥?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PCM是啥?相关的知识,希望对你有一定的参考价值。
PCM是什么东西?是什么意思? Pulse Code Modulation是什么东西?是什么意思?
脉冲编码调制(Pulse Code Modulation,PCM),由A.里弗斯于1937年提出的,这一概念为数字通信奠定了基础,60年代它开始应用于市内电话网以扩充容量,使已有音频电缆的大部分芯线的传输容量扩大24~48倍。到70年代中、末期,各国相继把脉码调制成功地应用于同轴电缆通信、微波接力通信、卫星通信和光纤通信等中、大容量传输系统。
80年代初,脉冲编码调制已用于市话中继传输和大容量干线传输以及数字程控交换机,并在用户话机中采用。
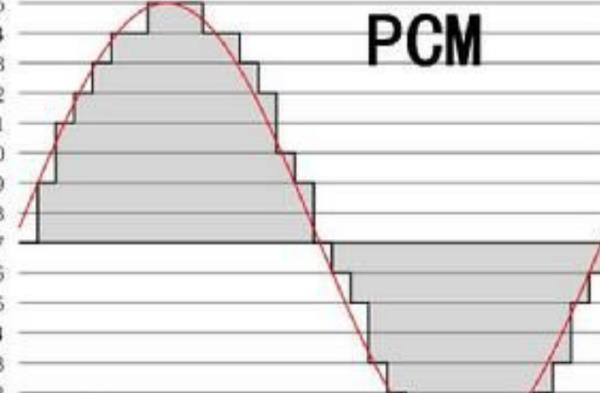
扩展资料:
(1)任何脉冲编码调制数字音频系统需要在其输入端设置急剧升降的滤波器,仅让20Hz-22.05kHz的频率通过(高端22.05kHz是由于CD44.1kHz的一半频率而确定)。
(2)在录音时采用多级或者串联抽选的数字滤波器(减低采样频率),在重放时采用多级的内插的数字滤波器(提高采样频率),为了控制小信号在编码时的失真,两者又都需要加入重复定量噪声。这样就限制了PCM技术在音频还原时的保真度。
参考技术A PCM(Pulse Code Modulation----脉码调制录音)。所谓PCM录音就是将声音等模拟信号变成符号化的脉冲列,再予以记录。PCM信号是由[1]、[0]等符号构成的数字信号。与模拟信号比,它不易受传送系统的杂波及失真的影响。动态范围宽,可得到音质相当好的影响效果。PCM轨迹与视频轨迹不同,故也可用于后期录音。但在Hi8的摄像机中要实现PCM,必须通过其他的专业器材,仅靠摄像机是无法达到该效果的。 PCM:Pulse Code Modulation 脉冲编码调制本回答被提问者采纳交错立体声 PCM 线性 Int16 大端音频是啥样的?
【中文标题】交错立体声 PCM 线性 Int16 大端音频是啥样的?【英文标题】:What does interleaved stereo PCM linear Int16 big endian audio look like?交错立体声 PCM 线性 Int16 大端音频是什么样的? 【发布时间】:2015-11-14 16:24:18 【问题描述】:我知道网上有很多资源解释如何解交织 PCM 数据。在我目前的项目过程中,我看过其中的大多数......但我没有音频处理方面的背景,我很难找到关于这种常见形式究竟如何的详细解释的音频被存储。
我知道我的音频将有两个通道,因此样本将以 [left][right][left][right] 格式存储... 我不明白这到底是什么意思。我还读到每个样本都以 [left MSB][left LSB][right MSB][right LSB] 格式存储。这是否意味着每个 16 位整数实际上编码了两个 8 位帧,或者每个 16 位整数是其自己的帧,用于左声道或右声道?
谢谢大家。任何帮助表示赞赏。
编辑:如果您选择给出示例,请参考以下内容。
方法上下文
具体来说,我要做的是将交错的 short[] 转换为两个 float[],每个代表左声道或右声道。我将在 Java 中实现它。
public static float[][] deinterleaveAudioData(short[] interleavedData)
//initialize the channel arrays
float[] left = new float[interleavedData.length / 2];
float[] right = new float[interleavedData.length / 2];
//iterate through the buffer
for (int i = 0; i < interleavedData.length; i++)
//THIS IS WHERE I DON'T KNOW WHAT TO DO
//return the separated left and right channels
return new float[][]left, right;
我当前的实现
我已尝试播放由此产生的音频。非常接近,接近到可以听懂一首歌的歌词,但显然仍然不是正确的方法。
public static float[][] deinterleaveAudioData(short[] interleavedData)
//initialize the channel arrays
float[] left = new float[interleavedData.length / 2];
float[] right = new float[interleavedData.length / 2];
//iterate through the buffer
for (int i = 0; i < left.length; i++)
left[i] = (float) interleavedData[2 * i];
right[i] = (float) interleavedData[2 * i + 1];
//return the separated left and right channels
return new float[][]left, right;
格式
如果有人想了解有关音频格式的更多信息,以下就是我所拥有的一切。
格式为 PCM 2 通道交错大端线性 int16 采样率为 44100 每个 short[] 缓冲区的短裤数量为 2048 每个 short[] 缓冲区的帧数为 1024 每个数据包的帧数为 1【问题讨论】:
您的实现看起来应该几乎完全正确 - 当您说您可以理解单词时,即使它们听起来是错误的,也可以确认这一点。您使用的输出格式的详细信息是什么?我的猜测是,short-to-float 转换需要缩放和/或偏移 - 使用 float 指定范围 [-32768, 32767] 会有点奇怪。 你是如何获得这个short[]数组的?如果样本已经在两个字节整数中,则字节顺序无关紧要。来源是签名还是未签名?预期输出在什么范围内?
@Sbodd 是的,阅读我认为缩放可能是问题的答案。我现在正在实施一个规范化的流程。
@Banthar 这个短数组来自Spotify Android SDK。这就是为什么我只能访问这些小块的原因——因为我只有流媒体的权限。短裤已签名,并且它们的预期范围包括(基于我在调试器中看到的)几乎整个 -32768 到 32768 的短裤范围。
【参考方案1】:
我在对通过 Spotify Android SDK 的 onAudioDataDelivered(). 传入的 short[] frames 进行去交错处理时遇到了类似的问题
onAudioDelivered 的文档在一年前写得不好。请参阅 Github issue。他们用更好的描述和更准确的参数名称更新了文档:
onAudioDataDelivered(short[] samples, int sampleCount, int sampleRate, int channels)
令人困惑的是samples.length 可以是4096。但是,它只包含sampleCount 有效样本。如果您正在接收立体声音频,并且sampleCount = 2048 在samples 数组中只有 1024 帧(每帧有两个样本)音频!
因此,您需要更新您的实现以确保您使用的是sampleCount 而不是samples.length。
【讨论】:
【参考方案2】:实际上,您正在处理一个几乎典型的音频 CD 质量的 WAVE 文件,也就是说:
2 个频道 44100 kHz 的采样率 在 16 位有符号整数上量化的每个幅度样本我说几乎是因为大端序通常用于 AIFF 文件(Mac 世界),而不是 WAVE 文件(PC 世界)。而且我不知道如何在 Java 中处理字节序,所以我将这部分留给你。
关于样本的存储方式非常简单:
每个样本占用 16 位(从 -32768 到 +32767 的整数) 如果通道交错:(L,1),(R,1),(L,2),(R,2),...,(L,n),(R,n) 如果通道不是:(L,1),(L,2),...,(L,n),(R,1),(R,2),...,(R,n )然后再喂一个音频回调,通常需要提供32位浮点,范围从-1到+1。也许这就是您的 aglorithm 中可能缺少某些东西的地方。将您的整数除以 32768 (2^(16-1)) 应该会听起来像预期的那样。
【讨论】:
老实说,鉴于这些信息,我认为我可能有少量字节序数据,这可能是我的问题的一部分。这是一个很长的故事,但我认为我拥有大端序数据,因为我使用 Apple 的 AudioConverter Service 测试了来自同一发件人在 iPhone 上的音频。我的目的地确实需要大端数据。我也相信规范化数据会有所帮助,并且现在正在努力实施。【参考方案3】:让我们先了解一些术语
通道是单声道样本流。该术语不一定意味着样本在数据流中是连续的。 帧是一组同时发生的样本。对于立体声音频(例如 L 和 R 通道),一帧包含两个样本。 数据包是 1 个或多个帧,通常是系统一次可以处理的最小帧数。对于 PCM 音频,一个数据包通常包含 1 帧,但对于压缩音频,它会更大。 交错 是一个通常用于立体声音频的术语,其中数据流由连续的音频帧组成。因此流看起来像 L1R1L2R2L3R3......LnRn存在大端和小端音频格式,并且取决于用例。但是,在系统之间交换数据时,这通常是一个问题——在处理或与操作系统音频组件交互时,您将始终使用本机字节顺序。
你没有说你使用的是小端还是大端系统,但我怀疑它可能是前者。在这种情况下,您需要对样本进行字节反转。
虽然不是一成不变的,但在使用浮点数时,样本通常在-1.0<x<+1.0 的范围内,因此您希望将样本除以1<<15。当使用 16 位线性类型时,它们通常是有符号的。
注意字节交换和格式转换:
int s = (int) interleavedData[2 * i];
short revS = (short) (((s & 0xff) << 8) | ((s >> 8) & 0xff))
left[i] = ((float) revS) / 32767.0f;
【讨论】:
有趣的是,您通过32767.0f 标准化。 @maxime.bochon 建议我应该除以 32768。我觉得我还听说对于多通道音频缓冲区,音量应该进一步除以通道数。如果不进行标准化,音频听起来会怎样?
这取决于是否认为 1.0f 的值被裁剪。使用1<<15 进行归一化肯定会更便宜地计算(除法是位移)。至于缺乏标准化:在您使用 DAC 等音频硬件之前,信号链没有任何区别。届时,您的信号将在两个方向上被严重削波。【参考方案4】:
我知道我的音频将有两个通道,因此样本将以 [left][right][left][right] 的格式存储......我不明白这到底是什么意思。
交错的 PCM 数据按通道顺序在每个通道存储一个样本,然后再继续下一个样本。 PCM 帧由每个通道的一组样本组成。如果您有左右声道的立体声音频,则每个样本中的一个样本一起构成一帧。
第 0 帧:[左样本][右样本] 第 1 帧:[左样本][右样本] 第 2 帧:[左样本][右样本] 第 3 帧:[左样本][右样本] 等等……每个样本都是瞬时压力的测量和数字量化。也就是说,如果每个样本有 8 位,则可以对压力进行 256 个可能的精度级别采样。知道声波是……波……有波峰和波谷,我们将希望能够测量到中心的距离。因此,我们可以将中心定义在 127 左右,然后从那里减去和加法(0 到 255,无符号),或者我们可以将这 8 位视为有符号(相同的值,只是对它们的不同解释)并从 -128 到 127。
对于单声道(单声道)音频,每个样本使用 8 位,我们每个样本使用一个字节,这意味着以 44.1kHz 采样的一秒音频恰好使用 44,100 字节的存储空间。
现在,让我们假设每个样本 8 位,但在 44.1.kHz 的立体声中。每隔一个字节都将用于左侧,每个其他字节都将用于 R。
LRLRLRLRLRLRLRLRLRLRLR...
将其放大到 16 位,每个样本有两个字节(样本设置有括号 [ 和 ],空格表示帧边界)
[LL][RR] [LL][RR] [LL][RR] [LL][RR] [LL][RR] [LL][RR]...
我还读到每个样本都以 [left MSB][left LSB][right MSB][right LSB] 格式存储。
不一定。音频可以以任何字节顺序存储。小端是最常见的,但这不是一个神奇的规则。我确实认为所有频道总是按顺序排列,在大多数情况下,左前方将是频道 0。
这是否意味着每个 16 位整数实际上编码了两个 8 位帧,或者每个 16 位整数是其自己的帧,用于左声道或右声道?
每个值(在这种情况下为 16 位整数)都用于单个通道。永远不会有两个多字节值相互碰撞。
我希望这会有所帮助。我无法运行您的代码,但根据您的描述,我怀疑您遇到了字节序问题,并且您的示例不是真正的大字节序。
【讨论】:
以上是关于PCM是啥?的主要内容,如果未能解决你的问题,请参考以下文章