cuda编程问题 运行出错
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了cuda编程问题 运行出错相关的知识,希望对你有一定的参考价值。
Error 84 error MSB3721: The command ""C:\cuda\NVIDIA GPU Computing Toolkit\CUDA\v7.0\bin\nvcc.exe" -ccbin "C:\Program Files (x86)\Microsoft Visual Studio 10.0\VC\bin\x86_amd64" -I./ -I../../common/inc -I./ -I"C:\cuda\NVIDIA GPU Computing Toolkit\CUDA\v7.0\/include" -I../../common/inc -I"C:\cuda\NVIDIA GPU Computing Toolkit\CUDA\v7.0\include" -I"C:\cuda\NVIDIA GPU Computing Toolkit\CUDA\v7.0\include" -G --keep-dir x64\Debug -maxrregcount=0 --machine 64 --compile -Xcompiler "/wd 4819" -g -DWIN32 -DWIN32 -D_MBCS -D_MBCS -Xcompiler "/EHsc /W3 /nologo /Od /Zi /RTC1 /MTd " -o x64/Debug/kernels.cu.obj "C:\cuda\NVIDIA Corporation\CUDA Samples\v7.0\7_CUDALibraries\simpleDevLibCUBLAS\kernels.cu" -clean" exited with code 1. C:\Program Files (x86)\MSBuild\Microsoft.Cpp\v4.0\BuildCustomizations\CUDA 7.0.targets 759
Compiling CUDA source file ..\..\src\caffe\layers\bnll_layer.cu...1>
1> D:\Caffe\WindowsCaffe_detect\Caffe_Windows_Detection-master\build\MSVC2013>"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\bin\nvcc.exe" -gencode=arch=compute_20,code=\"sm_20,compute_20\" -gencode=arch=compute_35,code=\"sm_35,compute_35\" -gencode=arch=compute_52,code=\"sm_52,compute_52\" --use-local-env --cl-version 2013 -ccbin "D:\gzSoft\vs2013\VC\bin\x86_amd64" -I../../3rdparty/include -I../../src -I../../include -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\include" -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\cuda\include" -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\include" -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\include" --keep-dir x64\Debug -maxrregcount=0 --machine 64 --compile -cudart static --verbose --keep -Xcudafe "--diag_suppress=exception_spec_override_incompat --diag_suppress=useless_using_declaration --diag_suppress=field_without_dll_interface" -D_SCL_SECURE_NO_WARNINGS -DGFLAGS_DLL_DECL= -D_VARIADIC_MAX=10 -DWIN32 -D_DEBUG -D_CONSOLE -D_UNICODE -DUNICODE -Xcompiler "/EHsc /W1 /nologo /Od /Zi /RTC1 /MDd " -o Debug\bnll_layer.cu.obj "D:\Caffe\WindowsCaffe_detect\Caffe_Windows_Detection-master\src\caffe\layers\bnll_layer.cu"
1> #$ _SPACE_=
1> #$ _CUDART_=cudart
1> #$ _HERE_=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\bin
1> #$ _THERE_=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\bin
1> #$ _TARGET_SIZE_=
1> #$ _TARGET_DIR_=
1> #$ _TARGET_SIZE_=64
1> #$ _WIN_PLATFORM_=x64
1> #$ TOP=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\bin/..
1> #$ NVVMIR_LIBRARY_DIR=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\bin/../nvvm/libdevice
1> #$ PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\bin/../open64/bin;C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\bin/../nvvm/bin;C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\bin;C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\bin/../lib;D:\gzSoft\vs2013\VC\bin\x86_amd64;D:\gzSoft\vs2013\VC\bin;C:\Program Files (x86)\Windows Kits\8.1\bin\x86;;C:\Program Files (x86)\Microsoft SDKs\Windows\v8.1A\bin\NETFX 4.5.1 Tools;D:\gzSoft\vs2013\Common7\Tools\bin;D:\gzSoft\vs2013\Common7\tools;D:\gzSoft\vs2013\Common7\ide;C:\Program Files (x86)\html Help Workshop;;C:\Program Files (x86)\MSBuild\12.0\bin\;C:\Windows\Microsoft.NET\Framework\v4.0.30319\;;C:\Program Files\DahuaTech\MV Viewer\Runtime\x64\;C:\Program Files\DahuaTech\MV Viewer\Runtime\x64\GenICam_v2_4\bin\Win64_x64\;C:\Program Files\DahuaTech\MV Viewer\Runtime\Win32\;C:\Program Files\DahuaTech\MV Viewer\Runtime\Win32\GenICam_v2_4\bin\Win32_i86\;C:\Program Files\Basler\pylon 4\pylon\bin\x64;C:\Program Files\Basler\pylon 4\pylon\bin\Win32;C:\Program Files\Basler\pylon 4\genicam\Bin\Win64_x64;C:\Program Files\Basler\pylon 4\genicam\Bin\Win32_i86;C:\Windows\system32;C:\Windows;C:\Windows\System32\Wbem;C:\Windows\System32\WindowsPowerShell\v1.0\;C:\Program Files (x86)\Microsoft SQL Server\100\Tools\Binn\;C:\Program Files\Microsoft SQL Server\100\Tools\Binn\;C:\Program Files\Microsoft SQL Server\100\DTS\Binn\;C:\Program Files\Microsoft\Web Platform Installer\;C:\Program Files (x86)\Microsoft ASP.NET\ASP.NET Web Pages\v1.0\;C:\Program Files\Microsoft SQL Server\110\Tools\Binn\;D:\gzSoft\opencv2.4.11\build_Sour\vc11\bin;D:\gzSoft\opencv2.4.10\build_Sour\vc10\bin;D:\gzSoft\qt5.2.1\5.2.1\msvc2012\bin;D:\MinGW\MinGW\bin;D:\gzSoft\vs2012\VC\bin;D:\gzSoft\javaTool\jdk1.7\bin;D:\gzSoft\javaTool\jdk1.7\jre\bin;D:\gzSoft\matlab\runtime\win64;D:\gzSoft\matlab\bin;D:\gzSoft\matlab\polyspace\bin;D:\software\eslib\bin;D:\gzSoft\lualib;D:\gzSoft\halcon12\bin\x86sse2-win32;D:\gzSoft\halcon12\FLEXlm\x86sse2-win32 ;C:\Program Files (x86)\Toshiba Teli\TeliCamSDK\TeliCamApi\bin\x86;C:\Program Files (x86)\CMake\bin\;D:\Program\opencv_pro\opencv-3.3.0\opencv-3.3.0\bulid\install\x86\vc11\bin;D:\gzSoft\doxygen\bin;D:\gzSoft\python2.7.10;D:\gzSoft\python2.7.10\Scripts;C:\Program Files (x86)\Windows Kits\8.1\Windows Performance Toolkit\;C:\Program Files (x86)\Microsoft SDKs\TypeScript\1.0\;C:\Program Files\Microsoft SQL Server\120\Tools\Binn\;D:\Caffe\WindowsCaffeProject\caffe-master\Build\x64\Debug;
1> #$ INCLUDES="-IC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\bin/../include"
1> #$ LIBRARIES= "/LIBPATH:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\bin/../lib/x64"
1> #$ CUDAFE_FLAGS=--sdk_dir "C:\Program Files (x86)\Windows Kits\8.1"
1> #$ PTXAS_FLAGS=
1> bnll_layer.cu
1> nvcc fatal : Failed to create the host compiler response file 'x64/Debug/bnll_layer.compute_52.cpp1.ii.res'
1>C:\Program Files (x86)\MSBuild\Microsoft.Cpp\v4.0\V120\BuildCustomizations\CUDA 7.5.targets(604,9): error MSB3721: 命令“"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\bin\nvcc.exe" -gencode=arch=compute_20,code=\"sm_20,compute_20\" -gencode=arch=compute_35,code=\"sm_35,compute_35\" -gencode=arch=compute_52,code=\"sm_52,compute_52\" --use-local-env --cl-version 2013 -ccbin "D:\gzSoft\vs2013\VC\bin\x86_amd64" -I../../3rdparty/include -I../../src -I../../include -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\include" -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\cuda\include" -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\include" -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\include" --keep-dir x64\Debug -maxrregcount=0 --machine 64 --compile -cudart static --verbose --keep -Xcudafe "--diag_suppress=exception_spec_override_incompat --diag_suppress=useless_using_declaration --diag_suppress=field_without_dll_interface" -D_SCL_SECURE_NO_WARNINGS -DGFLAGS_DLL_DECL= -D_VARIADIC_MAX=10 -DWIN32 -D_DEBUG -D_CONSOLE -D_UNICODE -DUNICODE -Xcompiler "/EHsc /W1 /nologo /Od /Zi /RTC1 /MDd " -o Debug\bnll_layer.cu.obj "D:\Caffe\WindowsCaffe_detect\Caffe_Windows_Detection-master\src\caffe\layers\bnll_layer.cu"”已退出,返回代码为 1。
========== 生成: 成功 0 个,失败 1 个,最新 0 个,跳过 0 个 ========== 参考技术A 你要把源代码贴出来
CUDA编程之线程模型
CUDA编程之线程模型
CUDA线程模型概述
CUDA线程层次


通过上图线程层次可划分为:
网格(Grid)
一Kernel映射一网格
网格在设备上执行
划分为线程块
线程块(Block)
发射到SM上执行
利用共享存储器通信
划分为线程
线程(Thread)
映射到SP上执行
五个内建变量
运行时获得网格和块的尺寸及线程索引等信息。
gridDim:包含三个元素x, y, z的结构体,表示网格在x,y,z方向上的尺寸,对应于执行配置中的第一个参数。blockDim:包含三个元素x, y, z的结构体,表示块在x,y,z方向上的尺寸,对应于执行配置的第二个参数blockIdx:包含三个元素x, y, z的结构体,分别表示当前线程所在块在网格中x, y, z方向上的索引threadIdx:包含三个元素x, y, z的结构体,分别表示当前线程在其所在块中x, y, z方向上的索引warpSize:表明warp的尺寸,在计算能力1.0的设备中,这个值是24,在1.0以上的设备中,这个值是32。
Kernel分配线程
一个kernel结构如下:Kernel<<
Dg:
grid的尺寸,说明一个grid含有多少个block,为dim3类型,一个grid最多含有65535 * 65535 * 65535个block,Dg.x,Dg.y,Dg.z最大值为65535;Db:
block的尺寸,说明一个block含有多少个thread,为dim3类型,一个block最多含有1024(cuda2.x版本)个threads,Db.x和Db.y最大值为1024,Db.z最大值64;(举个例子,一个block的尺寸可以是:1024 * 1 * 1 | 256 * 2 * 2 | 1 * 1024 * 1 | 2 * 8 * 64 | 4 * 4 * 64等)Ns:可选参数,如果
kernel中由动态分配内存的shared memory,需要在此指定大小,以字节为单位;S:可选参数,表示该
kernel处在哪个流当中。
CUDA向量加法深入理解grid、block、thread的关系及thread索引的计算
CUDA编程流程
CPU在GPU上分配内存:cudaMalloc;
CPU把数据发送到GPU:cudaMemcpy;
CPU在GPU上启动内核(kernel),它是自己写的一段程序,在每个线程上运行;
CPU把数据从GPU取回:cudaMemcpy;
CPU释放GPU上的内存。
CUDA向量加法源代码
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <stdlib.h>
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size);
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
int main()
{
// 定义向量长度
const int arraySize = 16;
// 向量a与b初始化填值
int a[arraySize], b[arraySize], c[arraySize];
for (int i = 0; i < arraySize; i++) {
a[i] = b[i] = i;
}
// 向量c初始化为零
int c[arraySize] = { 0 };
// 向量加法并行化计算
cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
//打印输出结果
for (int i = 0; i < arraySize; i++) { // 打印出来方便观察
cout << c[i] << " ";
}
cout << endl;
//退出之前调用cudaDeviceReset,以便分析和跟踪工具(如Nsight和Visual Profiler)显示完整的跟踪。
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
system("pause");
return 0;
}
//CUDA实现向量加法操作.
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{
// 初始化设备端地址
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// 选择0号GPU进行计算
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
// 为两个输入向量和一个输出向量申请显存
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// 将主机端的内存拷贝到设备端的显存
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// 在GPU上启动一个内核,为每个元素启动一个线程
dim3 grid(1, 1, 1), block(size, 1, 1);
addKernel<<<grid, block>>>(dev_c, dev_a, dev_b);
// 检查启动内核的任何错误
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed: %s
", cudaGetErrorString(cudaStatus));
goto Error;
}
// cudaDeviceSynchronize等待内核完成并返回(同步)
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!
", cudaStatus);
goto Error;
}
// 将GPU显存上的输出向量复制到主机内存。
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
}
基于源码的线程分配分析
方式一:grid(1, 1, 1), block(size, 1, 1)
首先定义一个线程如下图所示:

然后直观解释程序中的线程设置
dim3 grid(1, 1, 1), block(size, 1, 1); // 设置参数
在这段代码中,我们设置参数为线程格(grid)中只有一个一维的块(block),该block的x维度上有16个线程。图示如下:
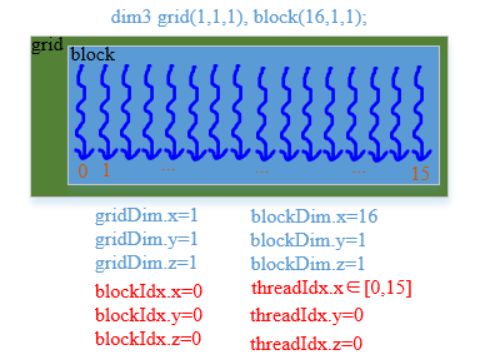
因此,按照此线程分配情况执行代码如下:
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
方式二:grid(1, 1, 1), block(8, 2, 1)
dim3 grid(1, 1, 1), block(8, 2, 1); // 设置参数
直观图示:
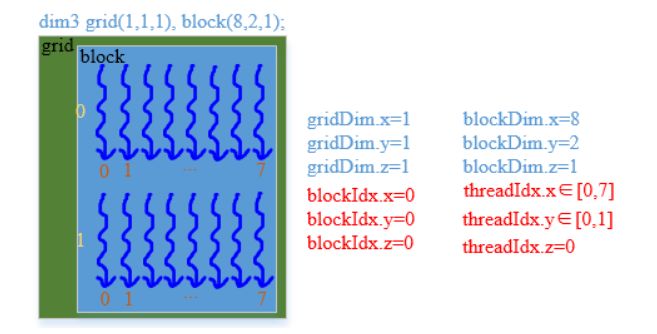
索引执行代码
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.y * blockDim.x + threadIdx.x; // 使用了threadIdx.x, threadIdx.x, blockDim.x
c[i] = a[i] + b[i];
}
方式三: grid(16, 1, 1), block(1, 1, 1)
dim3 grid(16, 1, 1), block(1, 1, 1); // 设置参数
直观图示:
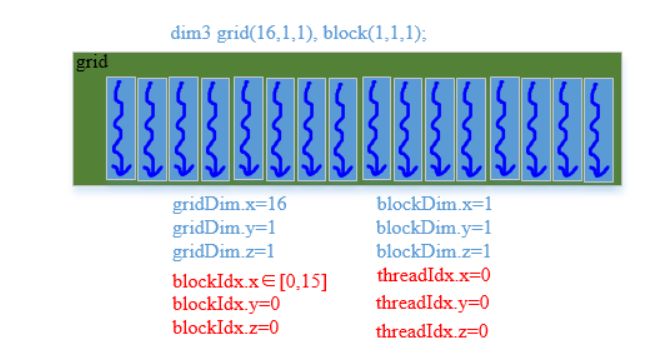
索引执行代码
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = blockIdx.x;
c[i] = a[i] + b[i];
}
方式四: grid(4, 1, 1), block(4, 1, 1)
dim3 grid(4, 1, 1), block(4, 1, 1); // 设置参数
直观图示:
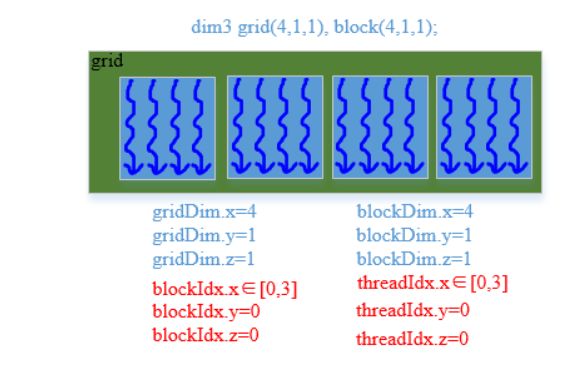
索引执行代码
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = blockIdx.x * gridDim.x + threadIdx.x;
c[i] = a[i] + b[i];
}
方式五: grid(2, 2, 1), block(2, 2, 1)
dim3 grid(2, 2, 1), block(2, 2, 1); // 设置参数
直观图示:
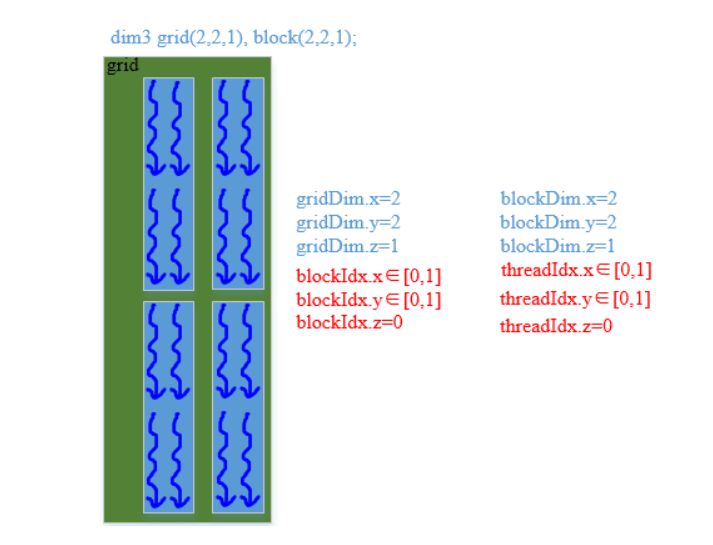
索引执行代码
__global__ void addKernel(int *c, const int *a, const int *b)
{
// 在第几个块中 * 块的大小 + 块中的x, y维度(几行几列)
int i = (blockIdx.y * gridDim.x + blockIdx.x) * (blockDim.x * blockDim.y) + threadIdx.y * blockDim.y + threadIdx.x;
c[i] = a[i] + b[i];
}
参考
[CUDA基础(1):操作流程与kernel概念]https://www.cnblogs.com/hankeyyh/p/6580427.html
[【CUDA】grid、block、thread的关系及thread索引的计算]https://blog.csdn.net/hujingshuang/article/details/53097222
-长按关注-
以上是关于cuda编程问题 运行出错的主要内容,如果未能解决你的问题,请参考以下文章
cuda编程CUDA的运行方式以及gridblock结构关系
cuda编程CUDA的运行方式以及gridblock结构关系
GPU高性能运算之CUDA,CUDA编程报错,大牛帮忙解答啊