XML生成与解析(DOMElementTree)
Posted 全栈测试笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了XML生成与解析(DOMElementTree)相关的知识,希望对你有一定的参考价值。
xml.dom篇
DOM是Document Object Model的简称,XML 文档的高级树型表示。该模型并非只针对 Python,而是一种普通XML 模型。Python 的 DOM 包是基于 SAX 构建的,并且包括在 Python 2.0 的标准 XML 支持里。
一、xml.dom的简单介绍
1、主要方法:
minidom.parse(filename):加载读取XML文件
doc.documentElement:获取XML文档对象
node.getAttribute(AttributeName):获取XML节点属性值
node.getElementsByTagName(TagName):获取XML节点对象集合
node.childNodes :返回子节点列表。
node.childNodes[index].nodeValue:获取XML节点值
node.firstChild:访问第一个节点,等价于pagexml.childNodes[0]
返回Node节点的xml表示的文本:
doc = minidom.parse(filename)
doc.toxml(\'UTF-8\')
访问元素属性:
Node.attributes["id"]
a.name #就是上面的 "id"
a.value #属性的值
2、举例说明
例1:文件名:book.xml
1 <?xml version="1.0" encoding="utf-8"?> 2 <info> 3 <intro>Book message</intro> 4 <list id=\'001\'> 5 <head>bookone</head> 6 <name>python check</name> 7 <number>001</number> 8 <page>200</page> 9 </list> 10 11 <list id=\'002\'> 12 <head>booktwo</head> 13 <name>python learn</name> 14 <number>002</number> 15 <page>300</page> 16 </list> 17 </info>
(1)创建DOM对象
import xml.dom.minidom dom1=xml.dom.minidom.parse(\'book.xml\') print(dom1)
返回结果为:
<xml.dom.minidom.Document object at 0x00000000025CE468>
(2)获取根字节
root=dom1.documentElement # 这里得到的是根节点 print(root) print(root.nodeName) print(root.nodeValue) print(root.nodeType)
返回结果为:
<DOM Element: info at 0x23619c8>
info
None
1
其中:
info是指根节点的名称root.nodeName
None是指根节点的值root.nodeValue
1是指根节点的类型root.nodeType,更多节点类型如下表:
|
NodeType |
Named Constant |
|
1 |
ELEMENT_NODE |
|
2 |
ATTRIBUTE_NODE |
|
3 |
TEXT_NODE |
|
4 |
CDATA_SECTION_NODE |
|
5 |
ENTITY_REFERENCE_NODE |
|
6 |
ENTITY_NODE |
|
7 |
PROCESSING_INSTRUCTION_NODE |
|
8 |
COMMENT_NODE |
|
9 |
DOCUMENT_NODE |
|
10 |
DOCUMENT_TYPE_NODE |
|
11 |
DOCUMENT_FRAGMENT_NODE |
|
12 |
NOTATION_NODE |
(3)子元素、子节点的访问
A、返回root子节点列表
import xml.dom.minidom dom1=xml.dom.minidom.parse(\'book.xml\') root=dom1.documentElement print(root.childNodes)
运行结果为:
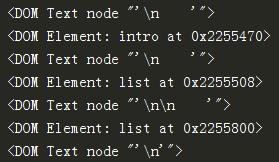
[<DOM Text node "\'\\n \'">, <DOM Element: intro at 0x2255470>, <DOM Text node "\'\\n \'">, <DOM Element: list at 0x2255508>, <DOM Text node "\'\\n\\n \'">, <DOM Element: list at 0x2255800>, <DOM Text node "\'\\n\'">]
for i in root.childNodes:
print(i)
结果:
Text也是一个节点,Text表示两个标签之间的内容,如
第一行结果表示<info>和<intro>之间的内容,为一个回车和4个空格
第五行结果表示</list>和<list id=\'002\'>之间的内容,为两个回车和4个空格
B、获取XML节点值,如返回根节点下第一个子节点、第二个子节点intro的值和名字
print(root.childNodes[0].nodeName) print(root.childNodes[0].nodeValue) print(root.childNodes[1].nodeName) print(root.childNodes[1].nodeValue)
运行结果为:

可以看出,第一个节点的值是一个回车加4个空格(竖线为鼠标光标)
C、访问第一个节点
print(root.firstChild.nodeName)
运行结果为:
#text
D、获取已经知道的元素名字的值,如要获取intro后的book message可以使用下面的方法:
import xml.dom.minidom
dom1=xml.dom.minidom.parse(\'book.xml\')
root=dom1.documentElement
node= root.getElementsByTagName(\'intro\')[0]
for node in node.childNodes:
if node.nodeType in (node.TEXT_NODE,node.CDATA_SECTION_NODE):
print(node.data)
这种方法的不足之处是需要对类型进行判断,使用起来不是很方便。运行结果是:
Book message
二、XML解析
对上面的xml进行解析
方法1 代码如下:
import xml.dom.minidom
dom1=xml.dom.minidom.parse(\'book.xml\')
root=dom1.documentElement
booknode=root.getElementsByTagName(\'list\')
for booklist in booknode:
print(\'=\'*20)
print(\'id:\'+booklist.getAttribute(\'id\'))
for nodelist in booklist.childNodes:
if nodelist.nodeType ==1:
print(nodelist.nodeName+\':\',)
for node in nodelist.childNodes:
print(node.data)
import xml.dom.minidom
dom1=xml.dom.minidom.parse(\'book.xml\')
root=dom1.documentElement
# print(root) # <DOM Element: info at 0x2131a60>
booknode=root.getElementsByTagName(\'list\') # 返回元素列表
# print(booknode) # [<DOM Element: list at 0x22505a0>, <DOM Element: list at 0x2250898>]
for booklist in booknode: # 循环列表,booklist表示每本书
print(\'=\'*20)
print(\'id:\'+booklist.getAttribute(\'id\')) # 标签属性值
# print(booklist.childNodes) # 每本书的节点,[<DOM Text node "\'\\n \'">, <DOM Element: head at 0x2590638>, <DOM Text node "\'\\n \'">, <DOM Element: name at 0x25906d0>, <DOM Text node "\'\\n \'">, <DOM Element: number at 0x2590768>, <DOM Text node "\'\\n \'">, <DOM Element: page at 0x2590800>, <DOM Text node "\'\\n \'">]
for nodelist in booklist.childNodes: # 循环当前书的节点
if nodelist.nodeType ==1: # 如果节点类型是1,表示是ELEMENT_NODE
print(nodelist.nodeName+\':\',end=\'\')
# print(type(nodelist))
\'\'\'
上面一句的输出结果
id:001
<class \'xml.dom.minidom.Element\'>
<class \'xml.dom.minidom.Element\'>
<class \'xml.dom.minidom.Element\'>
<class \'xml.dom.minidom.Element\'>
\'\'\'
# print(nodelist.childNodes)
\'\'\'
上面一句的输出结果
id:001
[<DOM Text node "\'bookone\'">]
[<DOM Text node "\'python che\'...">]
[<DOM Text node "\'001\'">]
[<DOM Text node "\'200\'">]
\'\'\'
for node in nodelist.childNodes:
print(node.data)
运行结果为:
====================
id:001
head: bookone
name: python check
number: 001
page: 200
====================
id:002
head: booktwo
name: python learn
number: 002
page: 300
方法二:
代码:
import xml.dom.minidom
dom1 = xml.dom.minidom.parse(\'book.xml\')
root = dom1.documentElement
booknode = root.getElementsByTagName(\'list\')
for booklist in booknode:
print(\'=\' * 20)
print(\'id:\' + booklist.getAttribute(\'id\'))
print(\'head:\' + booklist.getElementsByTagName(\'head\')[0].childNodes[0].nodeValue.strip())
print(\'name:\' + booklist.getElementsByTagName(\'name\')[0].childNodes[0].nodeValue.strip())
print(\'number:\' + booklist.getElementsByTagName(\'number\')[0].childNodes[0].nodeValue.strip())
print(\'page:\' + booklist.getElementsByTagName(\'page\')[0].childNodes[0].nodeValue.strip())
运行结果与方法一一样。比较上面的两个方法,方法一根据xml的树结构进行了多次循环,可读性上不及方法二,方法二直接对每一个节点进行操作,更加清晰。
为了更加方便程序的调用,可以使用一个list加一个字典进行存储
xml转换为字典(方法一):
import xml.dom.minidom
dom1=xml.dom.minidom.parse(\'book.xml\')
root=dom1.documentElement
book=[]
booknode=root.getElementsByTagName(\'list\')
for booklist in booknode:
bookdict={}
bookdict[\'id\']=booklist.getAttribute(\'id\')
bookdict[\'head\']=booklist.getElementsByTagName(\'head\')[0].childNodes[0].nodeValue.strip()
bookdict[\'name\']=booklist.getElementsByTagName(\'name\')[0].childNodes[0].nodeValue.strip()
bookdict[\'number\']=booklist.getElementsByTagName(\'number\')[0].childNodes[0].nodeValue.strip()
bookdict[\'page\']=booklist.getElementsByTagName(\'page\')[0].childNodes[0].nodeValue.strip()
book.append(bookdict)
print(book)
运行结果为:
[{\'id\': \'001\', \'head\': \'bookone\', \'name\': \'python check\', \'number\': \'001\', \'page\': \'200\'}, {\'id\': \'002\', \'head\': \'booktwo\', \'name\': \'python learn\', \'number\': \'002\', \'page\': \'300\'}]
该列表里包含了两个字典。
xml转换为字典(方法二):
1 <?xml version="1.0"?> 2 <root> 3 <person age="18"> 4 <name>张三</name> 5 <sex>男</sex> 6 </person> 7 <person age="19" des="您好"> 8 <name>李四</name> 9 <sex>女</sex> 10 </person> 11 </root>
from xml.etree import ElementTree as et
import json
# 从xml文件读取结点 转换为json格式,并保存到文件中
print(\'read node from xmlfile, transfer them to json, and save into jsonFile:\')
root1 = et.parse("testXml.xml") # 直接加载文件
print(root1) # <xml.etree.ElementTree.ElementTree object at 0x00000000023E3D30>
f = open(\'testJson.json\', \'a\', encoding="utf8")
for each in root1.getiterator("person"): # 利用getiterator方法得到指定节点
print(each) # <Element \'person\' at 0x000000000211C638>, <Element \'person\' at 0x00000000025DFC78>
tempDict = each.attrib # attrib获取XML节点属性值,返回字典
print(type(tempDict)) # <class \'dict\'>
print(tempDict) # {\'age\': \'18\'}, {\'age\': \'19\', \'des\': \'您好\'}
for childNode in each.getchildren(): # 利用getchildren方法得到子节点
print(childNode) # <Element \'name\' at 0x00000000023E3C28>, <Element \'sex\' at 0x00000000025BFC28>
tempDict[childNode.tag] = childNode.text # tag获取节点名,text获取节点值
print(tempDict) # {\'age\': \'18\', \'name\': \'张三\', \'sex\': \'男\'}, {\'age\': \'19\', \'des\': \'您好\', \'name\': \'李四\', \'sex\': \'女\'}
# 上面的字典,里面键值都是单引号,dumps后,变成双引号
tempJson = json.dumps(tempDict, ensure_ascii=False)
print(tempJson) # {"age": "18", "name": "张三", "sex": "男"}, {"age": "19", "des": "您好", "name": "李四", "sex": "女"}
f.write(tempJson + "\\n")
f.close()
# 从json文件中读取,并打印
print(\'read json from jsonfile:\')
for eachJson in open(\'testJson.json\', \'r\', encoding=\'utf8\'):
tempStr = json.loads(eachJson)
print(tempStr)
结果:
read node from xmlfile, transfer them to json, and save into jsonFile:
<xml.etree.ElementTree.ElementTree object at 0x0000000001E33DD8>
<Element \'person\' at 0x0000000001E1C408>
<class \'dict\'>
{\'age\': \'18\'}
<Element \'name\' at 0x0000000002205C28>
<Element \'sex\' at 0x00000000025DEC28>
{\'age\': \'18\', \'name\': \'张三\', \'sex\': \'男\'}
{"age": "18", "name": "张三", "sex": "男"}
<Element \'person\' at 0x00000000025DECC8>
<class \'dict\'>
{\'age\': \'19\', \'des\': \'您好\'}
<Element \'name\' at 0x00000000025DED18>
<Element \'sex\' at 0x00000000025DED68>
{\'age\': \'19\', \'des\': \'您好\', \'name\': \'李四\', \'sex\': \'女\'}
{"age": "19", "des": "您好", "name": "李四", "sex": "女"}
read json from jsonfile:
{\'age\': \'18\', \'name\': \'张三\', \'sex\': \'男\'}
{\'age\': \'19\', \'des\': \'您好\', \'name\': \'李四\', \'sex\': \'女\'}
三、建立XML文件
这里用方法三得到的结果,建立一个xml文件。
import xml.dom
def create_element(doc,tag,attr):
#创建一个元素节点
elementNode=doc.createElement(tag)
#创建一个文本节点
textNode=doc.createTextNode(attr)
#将文本节点作为元素节点的子节点
elementNode.appendChild(textNode)
return elementNode
dom1=xml.dom.getDOMImplementation()#创建文档对象,文档对象用于创建各种节点。
doc=dom1.createDocument(None,"info",None)
top_element = doc.documentElement# 得到根节点
books=[{\'id\': \'001\', \'head\': \'bookone\', \'name\': \'python check\', \'number\': \'001\', \'page\': \'200\'}, {\'id\': \'002\', \'head\': \'booktwo\', \'name\': \'python learn\', \'number\': \'002\', \'page\': \'300\'}]
for book in books:
sNode=doc.createElement(\'list\')
sNode.setAttribute(\'id\',str(book[\'id\']))
headNode=create_element(doc,\'head\',book[\'head\'])
nameNode=create_element(doc,\'name\',book[\'name\'])
numberNode=create_element(doc,\'number\',book[\'number\'])
pageNode=create_element(doc,\'page\',book[\'page\'])
sNode.appendChild(headNode)
sNode.appendChild(nameNode)
sNode.appendChild(pageNode)
top_element.appendChild(sNode)# 将遍历的节点添加到根节点下
xmlfile=open(\'bookdate.xml\',\'w\')
doc.writexml(xmlfile,addindent=\' \'*4, newl=\'\\n\', encoding=\'utf-8\')
xmlfile.close()
运行后生成bookdate.xml文件,该文件与book.xml一样。
xml.etree.ElementTree篇
依然使用例1的例子,对xml进行解析分析。
1、加载XML
方法一:直接加载文件
import xml.etree.ElementTree root=xml.etree.ElementTree.parse(\'book.xml\') print(root)
结果:
<xml.etree.ElementTree.ElementTree object at 0x00000000022095F8>
方法二:加载指定字符串
import xml.etree.ElementTree root = xml.etree.ElementTree.fromstring(xmltext)
这里xmltext是指定的字符串。
2、获取节点
方法一 利用getiterator方法得到指定节点
book_node=root.getiterator("list")
print(book_node)
结果:
[<Element \'list\' at 0x00000000021E6F98>, <Element \'list\' at 0x00000000025EF3B8>]
方法二 利用getchildren方法得到子节点,如例1中,要得到list下面子节点head的值:
import xml.etree.ElementTree
root=xml.etree.ElementTree.parse(\'book.xml\')
book_node=root.getiterator("list")
for node in book_node:
book_node_child=node.getchildren()[0]
print(book_node_child.tag+\':\'+book_node_child.text)
运行结果为:
head:bookone
head:booktwo
方法三 使用find和findall方法
find方法找到指定的第一个节点:
import xml.etree.ElementTree
root=xml.etree.ElementTree.parse(\'book.xml\')
book_find=root.find(\'list\')
# print(book_find) # <Element \'list\' at 0x0000000002406F48>
# print(type(book_find)) # <class \'xml.etree.ElementTree.Element\'>
for note in book_find:
# print(note)
\'\'\'
<Element \'head\' at 0x00000000025F6B38>
<Element \'name\' at 0x00000000025F6B88>
<Element \'number\' at 0x000000000260A228>
<Element \'page\' at 0x000000000260F368>
\'\'\'
print(note.tag+\':\'+note.text)
运行结果:
head:bookone
name:python check
number:001
page:200
findall方法将找到指定的所有节点:
import xml.etree.ElementTree
root=xml.etree.ElementTree.parse(\'book.xml\')
book=root.findall(\'list\')
print(book) # [<Element \'list\' at 0x0000000001E66F48>, <Element \'list\' at 0x00000000025DF368>]
for book_list in book:
for note in book_list:
print(note.tag+\':\'+note.text)
运行结果:
head:bookone
name:python check
number:001
page:200
head:booktwo
name:python learn
number:002
page:300
3、对book.xml进行解析的实例
import xml.etree.ElementTree
root=xml.etree.ElementTree.parse(\'book.xml\')
book=root.findall(\'list\')
for book_list in book:
print(\'=\'*20)
# print(type(book_list.attrib)) # <class \'dict\'>
if \'id\' in book_list.attrib:
print("id:"+book_list.attrib[\'id\'])
for note in book_list:
print(note.tag+\':\'+note.text)
print(\'=\'*20)
运行结果为:
====================
id:001
head:bookone
name:python check
number:001
page:200
====================
id:002
head:booktwo
name:python learn
number:002
page:300
====================
注意:
当要获取属性值时,如list id=’001’,用attrib方法。
当要获取节点值时,如<head>bookone</head>中的bookone用text方法。
当要获取节点名时,用tag方法。
》》》》》参考1:http://www.cnblogs.com/xiaowuyi/archive/2012/10/17/2727912.html
》》》》》参考2:http://blog.csdn.net/laoyaotask/article/details/41384719
以上是关于XML生成与解析(DOMElementTree)的主要内容,如果未能解决你的问题,请参考以下文章