Keystone几种token生成的方式分析
Posted MKY-技术驿站
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Keystone几种token生成的方式分析相关的知识,希望对你有一定的参考价值。
从Keystone的配置文件中,我们可见,Token的提供者目前支持四种。 Token Provider:UUID, PKI, PKIZ, or Fernet
结合源码及官方文档,我们用一个表格来阐述一下它们之间的差异。
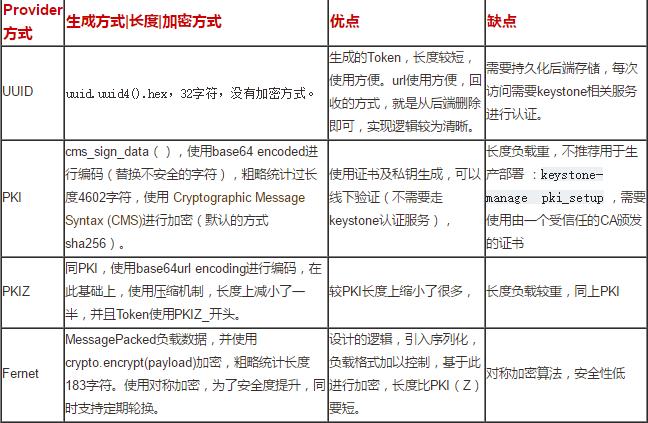
接下去,从源码上来进一步分析流程。
(1)首先,uuid,这种方式较简单,没有特别的加密、编码流程,核心的生成过程,即 uuid.uuid4().hex,生成一串友好的序列。
(2)PKI的流程,首先需要使用 keystone-manage pki_setup命令生成CA及相关的令牌机制,其代码如下所示:
def _get_token_id(self, token_data):
try:
token_json = jsonutils.dumps(token_data, cls=utils.PKIEncoder)
token_id = str(cms.cms_sign_token(token_json,
CONF.signing.certfile,
CONF.signing.keyfile)) #DEFAULT_TOKEN_DIGEST_ALGORITHM=sha256
其中,‘token_data’是获取的user、role、endpoint、catlog等信息集合,而最重要的语句是cms使用签名生成token的过程:cms_sign_token,使用默认的sha256方式加密,处理过程使用process,进行数据的读取、处理,
process = subprocess.Popen([\'openssl\', \'cms\', \'-sign\',
\'-signer\', signing_cert_file_name,
\'-inkey\', signing_key_file_name,
\'-outform\', \'PEM\',
\'-nosmimecap\', \'-nodetach\',
\'-nocerts\', \'-noattr\',
\'-md\', message_digest, ],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
close_fds=True)
最后output, err = process.communicate(data) 生成Token-id,这个过程涉及到openssl相关的加密技术,再次不作详述。我们只需清楚这个生成的大致流程。
(3)PKIZ的Token生成流程,和PKI类似,即在它的基础上进行的压缩,核心逻辑如下:
def _get_token_id(self, token_data):
try:
token_json = jsonutils.dumps(token_data, cls=utils.PKIEncoder)
token_id = str(cms.pkiz_sign(token_json,
CONF.signing.certfile,
CONF.signing.keyfile))
和PKI不同的是采用cms.pkiz_sign这个过程,进一步看这个过程,
def pkiz_sign(text,
signing_cert_file_name,
signing_key_file_name,
compression_level=6,
message_digest=DEFAULT_TOKEN_DIGEST_ALGORITHM):
signed = cms_sign_data(text,
signing_cert_file_name,
signing_key_file_name,
PKIZ_CMS_FORM,
message_digest=message_digest)
compressed = zlib.compress(signed, compression_level)
encoded = PKIZ_PREFIX + base64.urlsafe_b64encode( #PKIZ_PREFIX =pkiz_
compressed).decode(\'utf-8\')
return encoded
在PKI原来的基础上,引入了ZIib压缩,并且使用pkiz_作为token的开头。
(4)Fernet的技术,也需要首先使用命令keystone-manage fernet_setup生成必要的令牌信息,只是它有0,1版本的区分,并且可以指定版本的个数,默认是不超过3个。
(猜测这个是为了提高安全性,和轮询替换相关)Fernet的Token-id生成过程,和参数scope有很大的关系,它的核心代码中,支持Project模式、Domain模式、无模式等等,处理方法略有差异,因此Fernet的Token的逻辑,与用户的项目、域有很大的关系,Token-id的生成随机因素降低了。我们以其中Projec的模式进行分析。
payload = FederatedProjectScopedPayload.assemble(
user_id,
methods,
project_id,
expires_at,
audit_ids,
federated_info)
versioned_payload = (version,) + payload serialized_payload = msgpack.packb(versioned_payload) token = self.pack(serialized_payload)
从上面的代码中,可见首先是对负载数据payload的处理,组装过程,(应该是一个数理学家设计的。。。)
b_user_id = cls.attempt_convert_uuid_hex_to_bytes(user_id)
#user_id 传进来前 u\'b8aff9260dba489a831300630da4079f\' ->后 UUID(\'b8aff926-0dba-489a-8313-00630da4079f\') methods = auth_plugins.convert_method_list_to_integer(methods) 列表对应int的方法对应的是2*int(methods) b_project_id = cls.attempt_convert_uuid_hex_to_bytes(project_id) expires_at_int = cls._convert_time_string_to_int(expires_at) 过期时间的整数形式表示 b_audit_ids = list(map(provider.random_urlsafe_str_to_bytes, audit_ids)) 审计为列表,并用随机的二进制生成
组装过程返回一个列表,进一步组成带有version的负载,然后加密crypto.encrypt(payload).rstrip(\'=\'),最后然后进行编码处理,返回Token-id。
通过以上四种的Token生成方式分析,可见每种方式都有优缺点,如果希望少去和Keystone交互,减少认证请求带宽,可以采用PKI、PKIZ、Fernet的方式,而这几种方式的逻辑各有差异,涉及到加密方法的安全性,CA的权威性,这都需要进一步斟酌,uuid是keystone目前版本默认的安装方式,其使用简单,只是存在每次请求token都需要和keytone交互。总之,它们的存在都有自己的优跟缺。
以上是关于Keystone几种token生成的方式分析的主要内容,如果未能解决你的问题,请参考以下文章