流量控制与拥塞控制
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了流量控制与拥塞控制相关的知识,希望对你有一定的参考价值。
拥塞控制
在某段时间,若对网络中某资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏——产生拥塞(congestion)。
出现资源拥塞的条件:对资源需求的总和 > 可用资源
若网络中有许多资源同时产生拥塞,网络的性能就要明显变坏,整个网络的吞吐量将随输入负荷的增大而下降。
拥塞控制与流量控制的关系
拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。
拥塞控制是一个全局性的过程,涉及到所有的主机、所有的路由器,以及与降低网络传输性能有关的所有因素。
流量控制往往指在给定的发送端和接收端之间的点对点通信量的控制。
流量控制所要做的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
拥塞控制所起作用
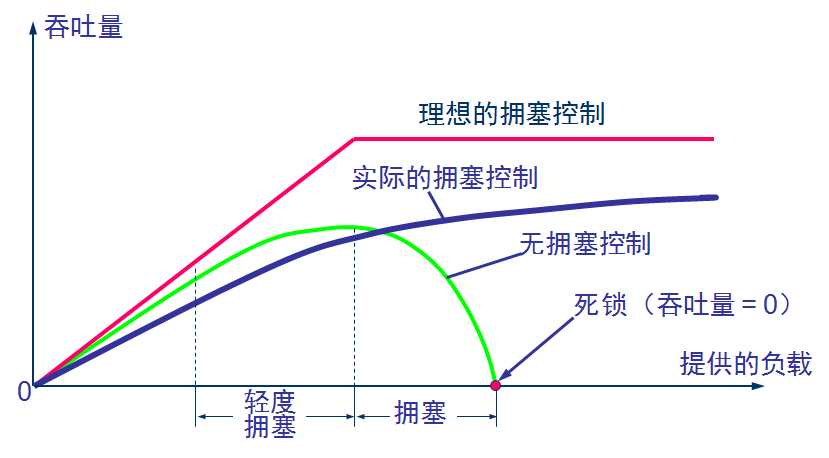
直接死锁
直接死锁即由互相占用了对方需要的资源而造成的死锁。
例如两个结点都有大量的分组要发往对方,但两个结点中的缓存在发送之前就已经全部被待发分组占满了。
当每个分组到达对方时,由于没有地方存放,只好被丢弃。发送分组的一方因收不到对方发来的确认信息,只能将发送过的分组依然保存在自己结点的缓存中。
这两个结点就这样一直互相僵持着,谁也无法成功地发送出一个分组。

重装死锁

- 报文A、B和C经过路由器P、Q和R发往主机H。
- 每一报文由4个分组构成。每个路由器的缓存只能容纳4个分组。
- 路由器R已为报文A预留了4个分组的缓存。
- 由于分组A3还未到达,所以目前还不能交付给主机H。
- 分组A3暂存于路由器P的缓存中,它无法转发到路由器Q,
- 因为路由器Q的缓存已全占满了。
拥塞控制一般原理
拥塞控制是很难设计的,因为它是一个动态的(而不是静态的)问题。
当前网络正朝着高速化的方向发展,这很容易出现缓存不够大而造成分组的丢失。但分组的丢失是网络发生拥塞的征兆而不是原因。
在许多情况下,甚至正是拥塞控制本身成为引起网络性能恶化甚至发生死锁的原因。这点应特别引起重视。
开环控制和闭环控制
开环控制方法就是在设计网络时事先将有关发生拥塞的因素考虑周到,力求网络在工作时不产生拥塞。
闭环控制是基于反馈环路的概念。属于闭环控制的有以下几种措施:
监测网络系统以便检测到拥塞在何时、何处发生。
将拥塞发生的信息传送到可采取行动的地方。
调整网络系统的运行以解决出现的问题。
值得注意的是拥塞不仅出现在网络层,在数据链路层、网络层、传输层都有。三者的不同比较如下:
|
层 次 |
影响拥塞的策略 |
|
传输层 |
往返延迟估计算法 超时算法 重传策略 失序缓存策略 确认策略 流量控制策略 缓冲区管理策略 |
|
网络层 |
连接机制(虚电路、数据报) 分组排队和服务策略 分组丢弃策略 路由选择算法 分组生存期管理 |
|
数据链路层 |
重传策略 排队和服务策略 分组丢失策略 确认策略 流量控制策略
|
拥塞产生原因
- 缓冲区容量有限
- 传输线路的频带有限
- 结点处理能力有限
- 由于网络中某部分刚发生故障
拥塞控制策略
- 缓冲区预分配
- 信息包丢弃法
- 定数拥塞控制法
- 流量控制
- 抑制信息包法
- 限制输出队的长度
流量控制
如果发送端发送的数据过多或者数据发送速率过快,导致接收端来不及处理,则会造成数据在接收端丢失。为了避免这种现象的发生,通常的处理办法就是采用流量控制,即控制发送端发送的数据量以及数据发送速率。使其不超过接收端的承受能力,这个能力主要指接收端的缓存和数据处理速度。
流控协议的层次关系
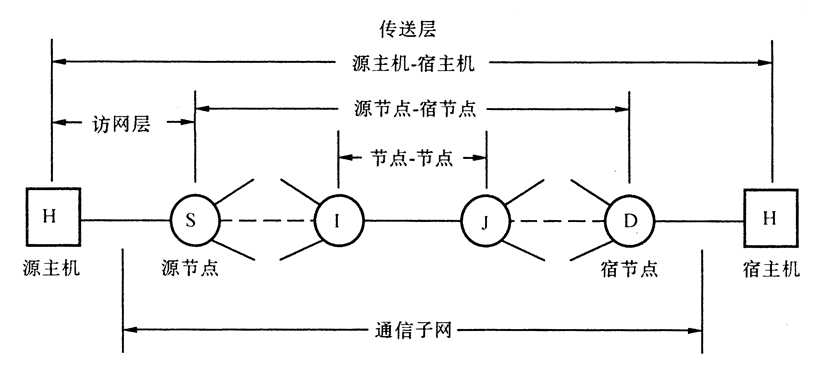
- 链路层:即在相邻两结点之间的一条链路上实行流控,称为“结点-结点流控”。
- 网络层:即在一条虚拟线路两端的源结点与宿结点之间实行流控,称为“源点-宿点流控”。
- 访网层:即在用户主机访问通信子网的进网线路对进入通信子网的业务量实行流控,称为对通信子网的“全局性流控”。
- 传送层:即在用户对的源主机与宿主机之间实行流控,称为“主机-主机流控”。
结点-结点流量控制
- 停止等待流量控制
- 滑动窗口流量控制
源点-宿点流量控制
- 预约发送法
- 窗口控制法
结点与主机之间的流量控制
- 局部拥塞测量:在源结点上测量该结点缓冲池的占据率。
- 全局拥塞测量:估计整个子网内所占用的全部缓冲器数目。
- 选择性拥塞测量:对选定的通路上的缓冲池占据率进行测量。
以上是关于流量控制与拥塞控制的主要内容,如果未能解决你的问题,请参考以下文章