scrapy-splash抓取动态数据例子十一
Posted shaomine
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scrapy-splash抓取动态数据例子十一相关的知识,希望对你有一定的参考价值。
一、介绍
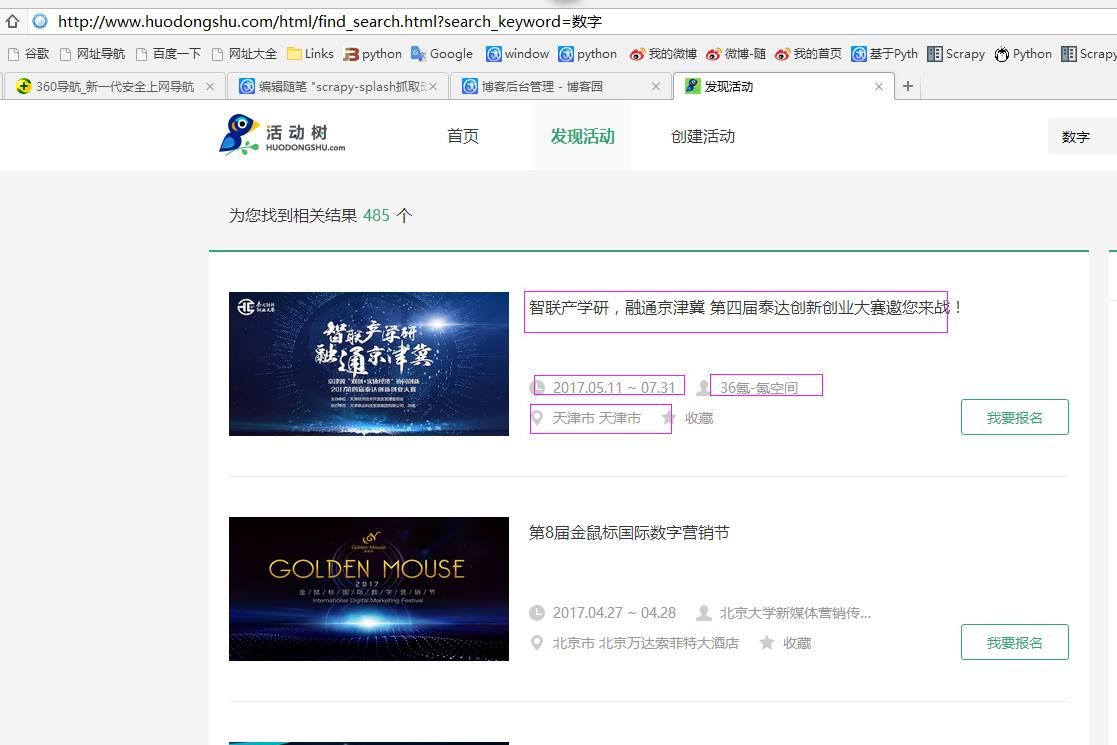
本例子用scrapy-splash抓取活动树网站给定关键字抓取活动信息。
给定关键字:数字;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
二、网站信息
三、数据抓取
针对上面的网站信息,来进行抓取
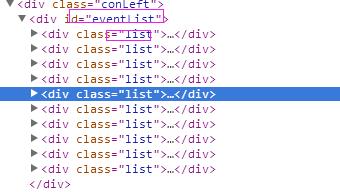
1、首先抓取信息列表
抓取代码:sels = site.xpath("//div[@id =\'eventList\']/div[@class =\'list\']")
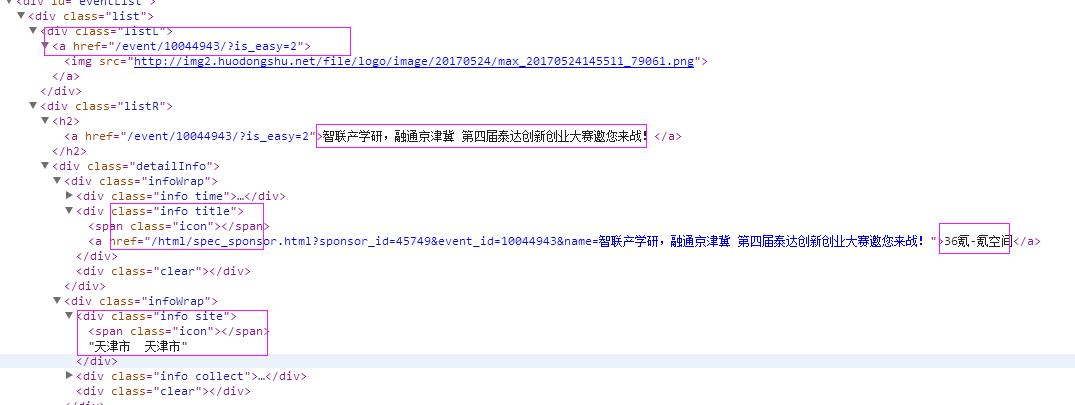
2、抓取标题
抓取代码:title = str(sel.xpath(\'.//div[2]/h2/a/text()\')[0].extract())
3、抓取链接
抓取代码:url = \'http://www.huodongshu.com\' + str(sel.xpath(\'.//div[1]/a/@href\')[0].extract())
4、抓取日期
抓取代码:dates = sel.xpath(\'.//div[@class="info time"]/text()\')
5、抓取来源
抓取代码:sources = sel.xpath(\'.//div[@class="info title"]/a/text()\')
6、地点
抓取代码:areas = sel.xpath(\'.//div[@class="info site"]/text()\')
四、完整代码
# -*- coding: utf-8 -*- import scrapy from scrapy import Request from scrapy.spiders import Spider from scrapy_splash import SplashRequest from scrapy_splash import SplashMiddleware from scrapy.http import Request, htmlResponse from scrapy.selector import Selector from scrapy_splash import SplashRequest from splash_test.items import SplashMeetingItem import IniFile import sys import os import re import time reload(sys) sys.setdefaultencoding(\'utf-8\') import urllib # sys.stdout = open(\'output.txt\', \'w\') class huodongshuSpider(Spider): name = \'huodongshu\' configfile = os.path.join(os.getcwd(), \'splash_test\\spiders\\setting.conf\') cf = IniFile.ConfigFile(configfile) meeting_wordlist = cf.GetValue("section", "meeting_keywords").split(\';\') websearch_url = cf.GetValue("huodongshu", "websearchurl") start_urls = [] for keyword in meeting_wordlist: url = websearch_url +keyword start_urls.append(url) # request需要封装成SplashRequest def start_requests(self): for url in self.start_urls: index = url.rfind(\'=\') yield SplashRequest(url , self.parse , args={\'wait\': \'2\'}, meta={\'keyword\': url[index + 1:]} ) def compareDate(self, dateLeft, dateRight): \'\'\' 比较俩个日期的大小 :param dateLeft: 日期 格式2017-03-04 :param dateRight:日期 格式2017-03-04 :return: 1:左大于右,0:相等,-1:左小于右 \'\'\' dls = dateLeft.split(\'-\') drs = dateRight.split(\'-\') if len(dls) > len(drs): return 1 if int(dls[0]) == int(drs[0]) and int(dls[1]) == int(drs[1]) and int(dls[2]) == int(drs[2]): return 0 if int(dls[0]) > int(drs[0]): return 1 elif int(dls[0]) == int(drs[0]) and int(dls[1]) > int(drs[1]): return 1 elif int(dls[0]) == int(drs[0]) and int(dls[1]) == int(drs[1]) and int(dls[2]) > int(drs[2]): return 1 return -1 def date_isValid(self, strDateText): \'\'\' 判断日期时间字符串是否合法:如果给定时间大于当前时间是合法,或者说当前时间给定的范围内 :param strDateText: 三种格式 \'2017.04.27 ~ 04.28\'; \'2017.04.20 08:30 ~ 12:30\' ; \'2015.12.29 ~ 2016.01.03\' :return: True:合法;False:不合法 \'\'\' datePattern = re.compile(r\'\\d{4}-\\d{2}-\\d{2}\') date = strDateText.replace(\'.\', \'-\') strDate = re.findall(datePattern, date) currentDate = time.strftime(\'%Y-%m-%d\') flag = False startdate = \'\' enddate = \'\' if len(strDate) == 2: if self.compareDate(strDate[1], currentDate) > 0: flag = True startdate = strDate[0] enddate = strDate[1] elif len(strDate) == 1: # 2017.07.13 ~ 07.15 if date.find(\':\') > 0: if self.compareDate(strDate[0], currentDate) >= 0: flag = True startdate = strDate[0] enddate = strDate[0] else: startdate = strDate[0] enddate = date[0:5] + date[len(date) - 5:] if self.compareDate(enddate, currentDate) >= 0: flag = True return flag, startdate, enddate def parse(self, response): site = Selector(response) sels = site.xpath("//div[@id =\'eventList\']/div[@class =\'list\']") keyword = response.meta[\'keyword\'] it_list = [] for sel in sels: dates = sel.xpath(\'.//div[@class="info time"]/text()\') if len(dates) > 0: strdate = str(dates[0].extract()) flag, startdate, enddate = self.date_isValid(strdate) if flag: title = str(sel.xpath(\'.//div[2]/h2/a/text()\')[0].extract()) if title.find(keyword) > -1: url = \'http://www.huodongshu.com\' + str(sel.xpath(\'.//div[1]/a/@href\')[0].extract()) it = SplashMeetingItem() it[\'title\'] = title it[\'url\'] = url it[\'date\'] = strdate it[\'startdate\'] = startdate it[\'enddate\'] = enddate it[\'keyword\'] = keyword areas = sel.xpath(\'.//div[@class="info site"]/text()\') if len(areas) > 0: it[\'area\']=areas[0].extract() sources = sel.xpath(\'.//div[@class="info title"]/a/text()\') if len(sources)>0: it[\'source\'] = sources[0].extract() it_list.append(it) return it_list
以上是关于scrapy-splash抓取动态数据例子十一的主要内容,如果未能解决你的问题,请参考以下文章