基于FPGA的均值滤波算法的实现
Posted NingHeChuan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于FPGA的均值滤波算法的实现相关的知识,希望对你有一定的参考价值。
前面实现了基于FPGA的彩色图像转灰度处理,减小了图像的体积,但是其中还是存在许多噪声,会影响图像的边缘检测,所以这一篇就要消除这些噪声,基于灰度图像进行图像的滤波处理,为图像的边缘检测做好夯实基础。
椒盐噪声(salt & pepper noise)是数字图像的一个常见噪声,所谓椒盐,椒就是黑,盐就是白,椒盐噪声就是在图像上随机出现黑色白色的像素。椒盐噪声是一种因为信号脉冲强度引起的噪声,产生该噪声的算法也比较简单。
均值滤波的方法将数据存储成3x3的矩阵,然后求这个矩阵。在图像上对目标像素给一个模板,该模板包括了其周围的临近像素(以目标象素为中心的周围 8 个像素,构成一个滤波模板,即去掉目标像素本身),再用模板中的全体像素的平均值来代替原来像素值。
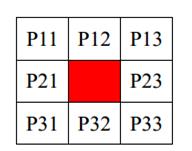
如图所示,我们要进行均值滤波首先要生成一个3x3矩阵。算法运算窗口一般采用奇数点的邻域来计算中值,最常用的窗口有3X3和5X5模型。下面介绍3X3窗口的Verilog实现方法。
(1)通过2个或者3个RAM的存储来实现3X3像素窗口;
(2)通过2个或者3个FIFO的存储来实现3X3像素窗口;
(3)通过2行或者3行Shift_RAM的存储来实现3X3像素窗口;
要想用实现均值滤波和中值滤波,必须要先生成3x3阵列,在Altera系列里,可以用QuatusII调用IP核——shift_RAM,具体设置参数如图所示。
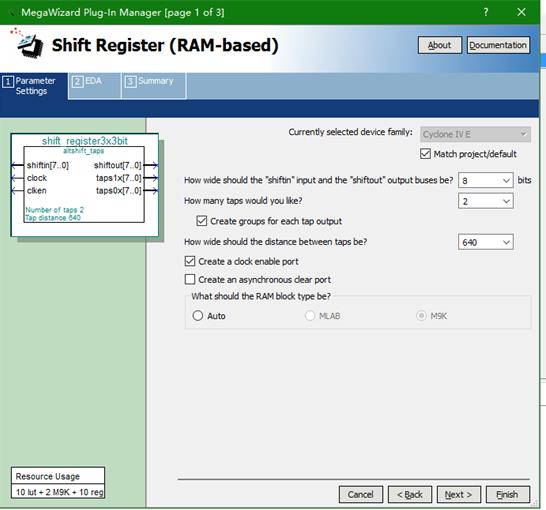
如上图所示,其中shiftin是实时输入的数据,taps1x,taps2x输入数据的第二三行,当数据输入成一行三个时,自动跳到下一行,最终形成每行是三列的一个矩阵,用均值滤波和中值滤波的处理方法即可,这样基本是每一个目标都可以找到自己对应的一个3x3矩阵,最后进行处理。先进入IP核里面的是最开始的的数据,所以在读出的时候也是要放在第一行。
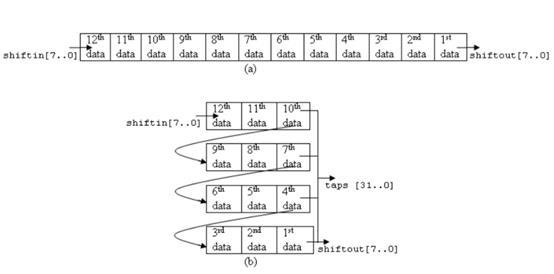
关于shift_ram的更详细的解释可以查看我的另一篇博文:http://www.cnblogs.com/ninghechuan/p/6789399.html。
这学期做比赛用的是国产FPGA,开发软件是PDS,这个软件说实话比较简洁,快,里面也有shift_ram IP core,但是不能设置多行(一个IP只能存储一行),不过只要你理解了shift_ram的工作的原理,完全可以用几个来实现多行处理,我通过PDS开发套件调用两个shift_register IP核来生成3X3矩阵实现3X3像素窗口。shift_register IP核可定义数据宽度、移位的行数、每行的深度。这里我们需要8bit。640个数据每行,同事移位寄存2行即可。同时选择时钟使能端口clken。
1 shift_ram_end u_shift_ram_end1 2 ( 3 .din (row3_data), 4 .clk (shift_clk_en), 5 .rst (~rst_n), 6 .dout (row2_data) 7 ); 8 9 shift_ram_end u_shift_ram_end2 10 ( 11 .din (row2_data), 12 .clk (shift_clk_en), 13 .rst (~rst_n), 14 .dout (row1_data) 15 );

如图所示,我们这里将行设置为8,场设置为4,所以可以明显的看到,当数据缓存到一行时,就会移位寄存到下一行,缓存两行后便会生成3X3矩阵。
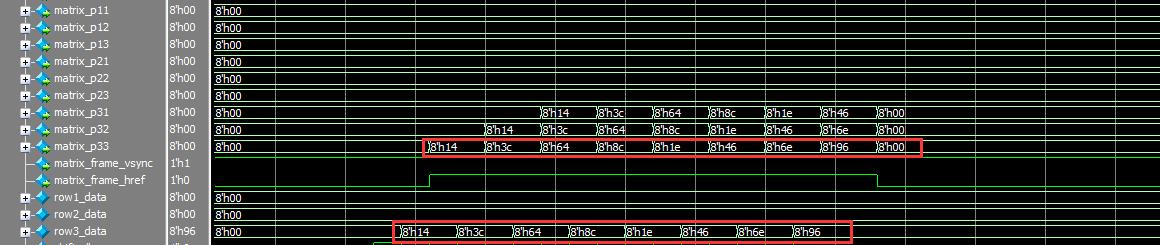
如图所示,比较缓存的第一行的数据在3x3矩阵中,占第一行,结果相同,显然是正确的。
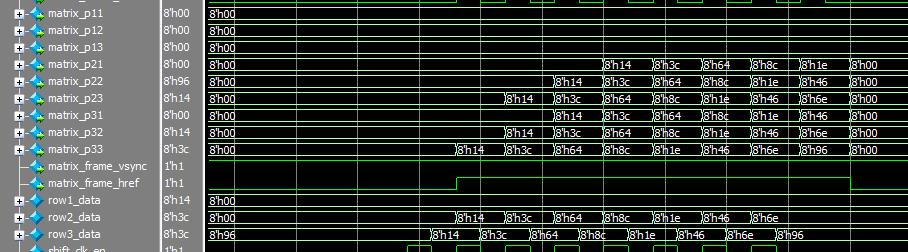
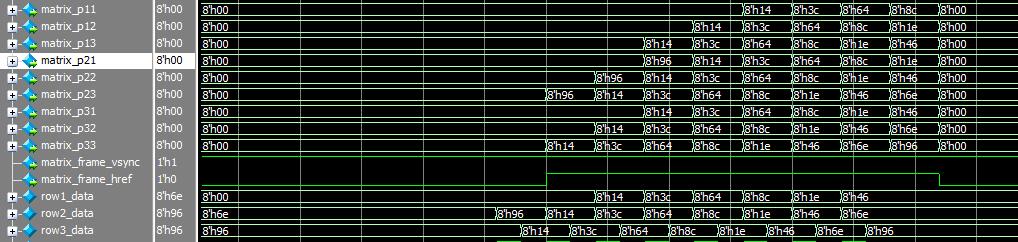
如图所示,第二行、第三行和最终生成的3x3矩阵作比较,结果显然是正确的。


1 //wire [32:0] matrix_row1 = {matrix_p11, matrix_p12,matrix_p13};//just for test 2 //wire [32:0] matrix_row2 = {matrix_p21, matrix_p22,matrix_p23}; 3 //wire [32:0] matrix_row3 = {matrix_p31, matrix_p32,matrix_p33}; 4 always @(posedge clk or negedge rst_n) 5 begin 6 if(!rst_n)begin 7 {matrix_p11, matrix_p12, matrix_p13} <= 33\'h0; 8 {matrix_p21, matrix_p22, matrix_p23} <= 33\'h0; 9 {matrix_p31, matrix_p32, matrix_p33} <= 33\'h0; 10 end 11 else if(read_frame_href)begin 12 if(read_frame_clken)begin//shift_RAM data read clock enbale 13 {matrix_p11, matrix_p12, matrix_p13} <= {matrix_p12, matrix_p13, row1_data};//1th shift input 14 {matrix_p21, matrix_p22, matrix_p23} <= {matrix_p22, matrix_p23, row2_data};//2th shift input 15 {matrix_p31, matrix_p32, matrix_p33} <= {matrix_p32, matrix_p33, row3_data};//3th shift input 16 end 17 else begin 18 {matrix_p11, matrix_p12, matrix_p13} <= {matrix_p11, matrix_p12, matrix_p13}; 19 {matrix_p21, matrix_p22, matrix_p23} <= {matrix_p21, matrix_p22, matrix_p23}; 20 {matrix_p31, matrix_p32, matrix_p33} <= {matrix_p31, matrix_p32, matrix_p33}; 21 end 22 end 23 else begin 24 {matrix_p11, matrix_p12, matrix_p13} <= 33\'h0; 25 {matrix_p21, matrix_p22, matrix_p23} <= 33\'h0; 26 {matrix_p31, matrix_p32, matrix_p33} <= 33\'h0; 27 end 28 end
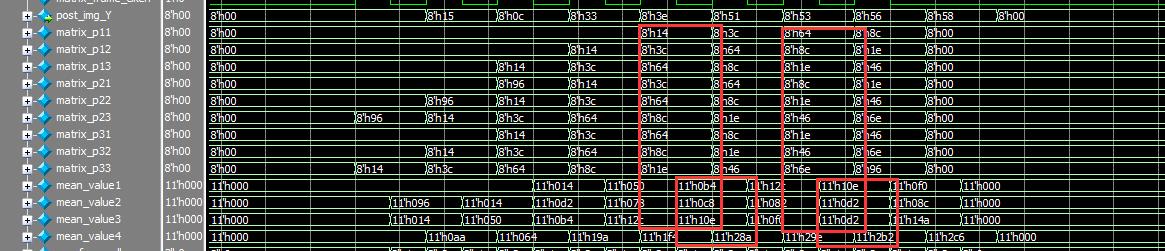
1 assign post_img_Y = mean_value4[10:3];//求平均值除以8,向右移位3位
如图所示,将3x3矩阵的中心像素的周围八个点求和,我们上面还是采取了流水线的设计方法,来增加吞吐量,然后再求平均值代替目标像素的值,从波形图上观察,计算的结果显然是正确的。这样便完成了均值滤波的仿真。
1 //-------------------------------------------- 2 //Generate 8bit 3x3 matrix for video image processor 3 //Image data has been processd 4 wire matrix_frame_vsync; //Prepared Image data vsync valid signal 5 wire matrix_frame_href; //Prepared Image data href vaild signal 6 wire matrix_frame_clken; //Prepared Image data output/capture enable clock 7 wire [7:0] matrix_p11, matrix_p12, matrix_p13;//3x3 materix output 8 wire [7:0] matrix_p21, matrix_p22, matrix_p23; 9 wire [7:0] matrix_p31, matrix_p32, matrix_p33; 10 11 shift_RAM_3x3 u_shift_RAM_3x3 12 ( 13 //global signals 14 .clk (clk), 15 .rst_n (rst_n), 16 //Image data prepred to be processd 17 .per_frame_vsync (per_frame_vsync), //Prepared Image data vsync valid signal 18 .per_frame_href (per_frame_href), //Prepared Image data href vaild signal 19 .per_frame_clken (per_frame_clken), //Prepared Image data output/capture enable clock 20 .per_img_Y (per_img_Y), //Prepared Image brightness input 21 22 //Image data has been processd 23 .matrix_frame_vsync (matrix_frame_vsync), //Prepared Image data vsync valid signal 24 .matrix_frame_href (matrix_frame_href), //Prepared Image data href vaild signal 25 .matrix_frame_clken (matrix_frame_clken), //Prepared Image data output/capture enable clock 26 .matrix_p11 (matrix_p11), 27 .matrix_p12 (matrix_p12), 28 .matrix_p13 (matrix_p13), //3X3 Matrix output 29 .matrix_p21 (matrix_p21), 30 .matrix_p22 (matrix_p22), 31 .matrix_p23 (matrix_p23), 32 .matrix_p31 (matrix_p31), 33 .matrix_p32 (matrix_p32), 34 .matrix_p33 (matrix_p33) 35 36 ); 37 38 //----------------------------------------------------------------------- 39 //step1 40 reg [10:0] mean_value1, mean_value2, mean_value3; 41 always @(posedge clk or negedge rst_n) 42 begin 43 if(!rst_n)begin 44 mean_value1 <= 11\'d0; 45 mean_value2 <= 11\'d0; 46 mean_value3 <= 11\'d0; 47 end 48 else begin 49 mean_value1 <= matrix_p11 + matrix_p12 + matrix_p13; 50 mean_value2 <= matrix_p21 + 11\'d0 + matrix_p23; 51 mean_value3 <= matrix_p31 + matrix_p32 + matrix_p33; 52 end 53 end 54 55 //step2 56 reg [10:0] mean_value4; 57 always @(posedge clk or negedge rst_n) 58 begin 59 if(!rst_n) 60 mean_value4 <= 11\'d0; 61 else 62 mean_value4 <= mean_value1 + mean_value2 + mean_value3; 63 end
当然,最后为了保持时钟的同步性,将消耗的时钟延时输出。
1 //------------------------------------------------------------ 2 //delay 2 clk 3 reg [1:0] per_frame_clken_r; 4 reg [1:0] per_frame_href_r; 5 reg [1:0] per_frame_vsync_r; 6 7 always @(posedge clk or negedge rst_n) 8 begin 9 if(!rst_n)begin 10 per_frame_clken_r <= 2\'b0; 11 per_frame_href_r <= 2\'b0; 12 per_frame_vsync_r <= 2\'b0; 13 end 14 else begin 15 per_frame_clken_r <= {per_frame_clken_r[0], matrix_frame_clken}; 16 per_frame_href_r <= {per_frame_href_r[0], matrix_frame_href}; 17 per_frame_vsync_r <= {per_frame_vsync_r[0], matrix_frame_vsync}; 18 end 19 end 20 21 assign post_frame_vsync = per_frame_vsync_r[1]; 22 assign post_frame_href = per_frame_href_r[1]; 23 assign post_frame_clken = per_frame_clken_r[1];


图上为灰度图像,图下为均值滤波后的图像,可以看出滤波后的图像有一些模糊,这是因为均值滤波就是将图像做平滑处理,像素值高的像素会被拉低,像素值低像素会被拉高,趋向于一个平均值,所以图像会变模糊一些。这样基于FPGA的均值滤波就完成了,下一篇我会发布基于FPGA的中值滤波处理,并且比较这两种滤波方式的优劣,最终选取较好的一种滤波方式进行图像边缘检测处理。

转载请注明出处:NingHeChuan(宁河川)
个人微信订阅号:NingHeChuan
如果你想及时收到个人撰写的博文推送,可以扫描左边二维码(或者长按识别二维码)关注个人微信订阅号
知乎ID:NingHeChuan
微博ID:NingHeChuan
以上是关于基于FPGA的均值滤波算法的实现的主要内容,如果未能解决你的问题,请参考以下文章
FPGA教程案例45图像案例5——基于FPGA的图像均值滤波verilog实现,通过MATLAB进行辅助验证
FPGA教程案例78通信案例4——基于FPGA的RLS自适应滤波算法实现
基于FPGA的LMS自适应滤波器verilog实现,包括testbench
数字下变频基于quartusii的FPGA数字下变频系统设计,包括NCO,CIC,半带滤波器等模块的详细FPGA实现过程