storm的流分组
Posted 百里登风
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了storm的流分组相关的知识,希望对你有一定的参考价值。

用的是ShuffleGrouping分组方式,并行度设置为3
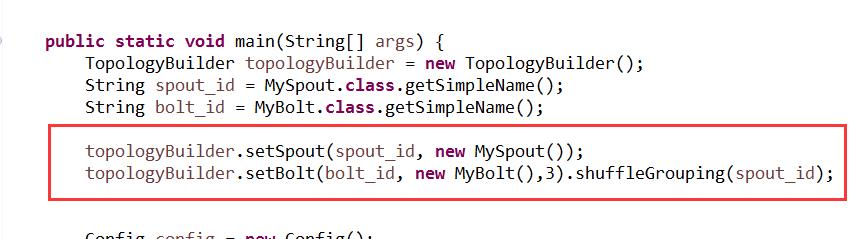
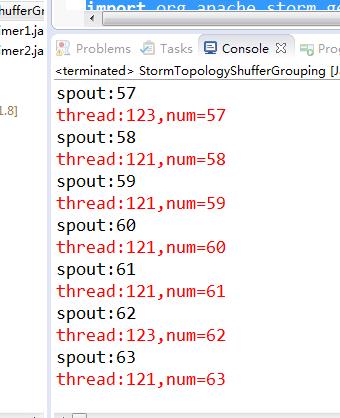
这是跑下来的结果
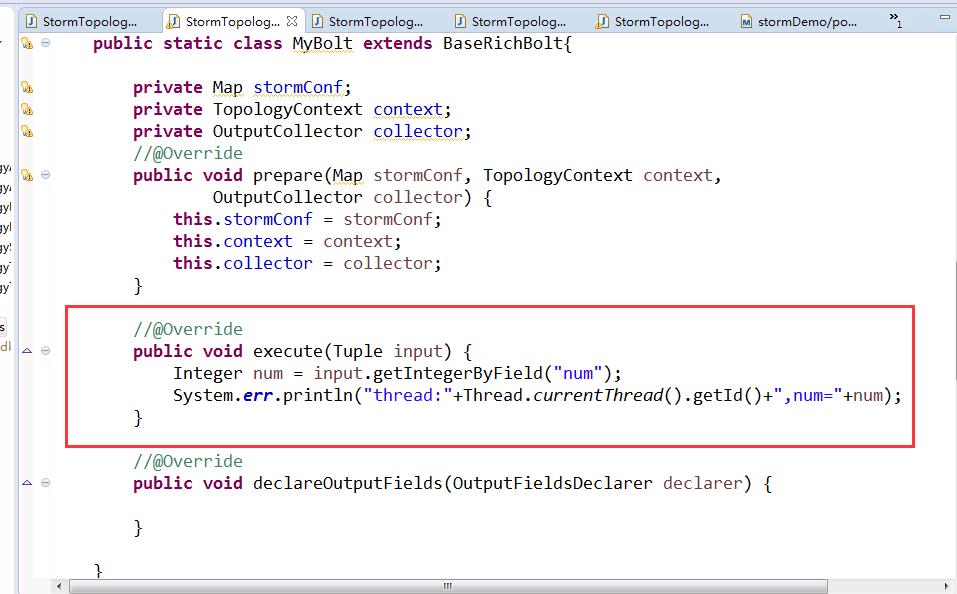
参考代码StormTopologyShufferGrouping.java
package yehua.storm;
import java.util.Map;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
/**
* shufferGrouping
* 没有特殊情况下,就使用这个分组方式,可以保证负载均衡,工作中最常用的
* @author yehua
*
*/
public class StormTopologyShufferGrouping {
public static class MySpout extends BaseRichSpout{
private Map conf;
private TopologyContext context;
private SpoutOutputCollector collector;
// @Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
this.conf = conf;
this.collector = collector;
this.context = context;
}
int num = 0;
//@Override
public void nextTuple() {
num++;
System.out.println("spout:"+num);
this.collector.emit(new Values(num));
Utils.sleep(1000);
}
//@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("num"));
}
}
public static class MyBolt extends BaseRichBolt{
private Map stormConf;
private TopologyContext context;
private OutputCollector collector;
// @Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.stormConf = stormConf;
this.context = context;
this.collector = collector;
}
//@Override
public void execute(Tuple input) {
Integer num = input.getIntegerByField("num");
System.err.println("thread:"+Thread.currentThread().getId()+",num="+num);
}
//@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
public static void main(String[] args) {
TopologyBuilder topologyBuilder = new TopologyBuilder();
String spout_id = MySpout.class.getSimpleName();
String bolt_id = MyBolt.class.getSimpleName();
topologyBuilder.setSpout(spout_id, new MySpout());
topologyBuilder.setBolt(bolt_id, new MyBolt(),3).shuffleGrouping(spout_id);
Config config = new Config();
String topology_name = StormTopologyShufferGrouping.class.getSimpleName();
if(args.length==0){
//在本地运行
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology(topology_name, config, topologyBuilder.createTopology());
}else{
//在集群运行
try {
StormSubmitter.submitTopology(topology_name, config, topologyBuilder.createTopology());
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
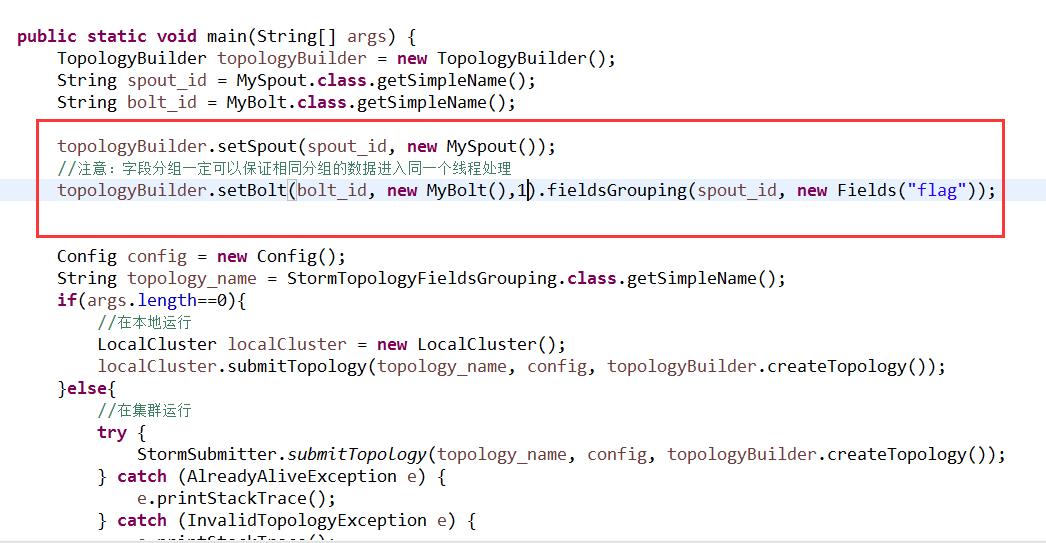
e.printStackTrace();
} catch (AuthorizationException e) {
e.printStackTrace();
}
}
}
}
用fieldsGrouping方法
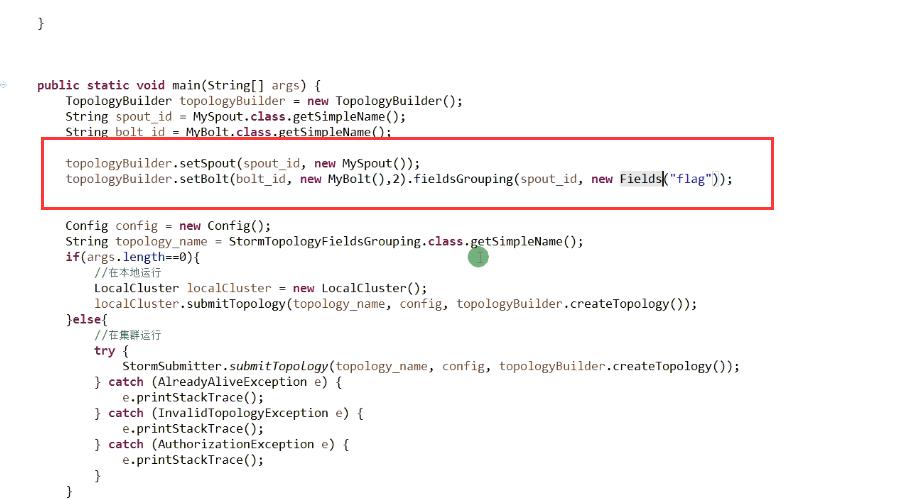
按奇偶数分组(也就是按字段分组)
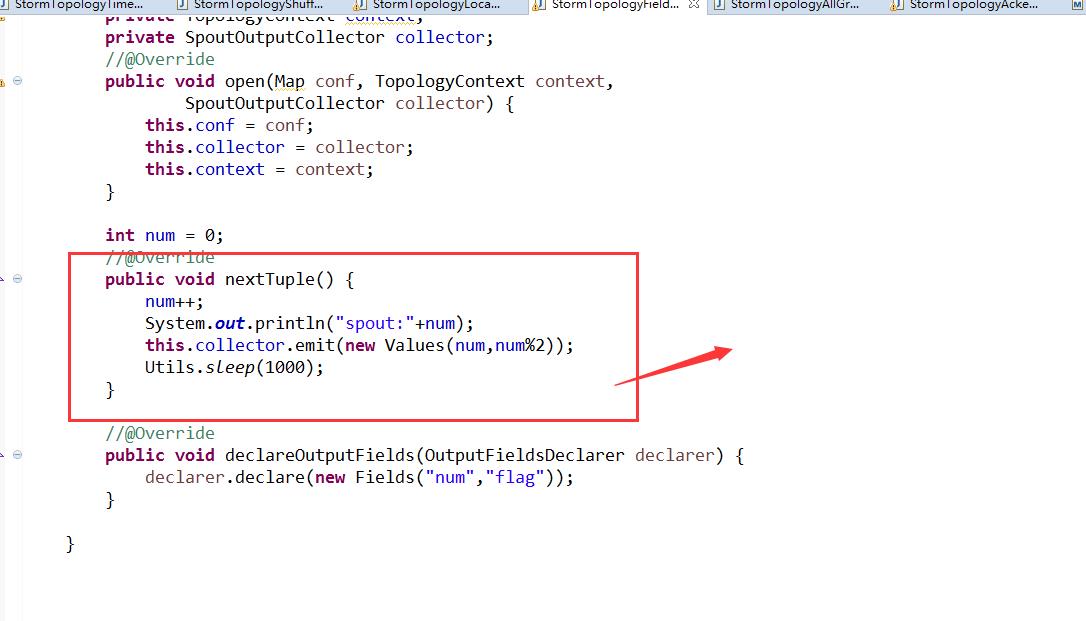
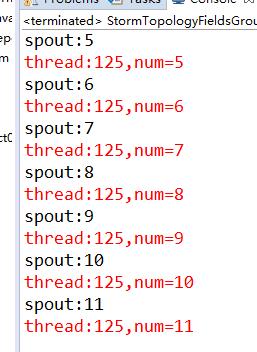
从跑出来的结果看出来,一个线程处理奇数的一个线程处理偶数的
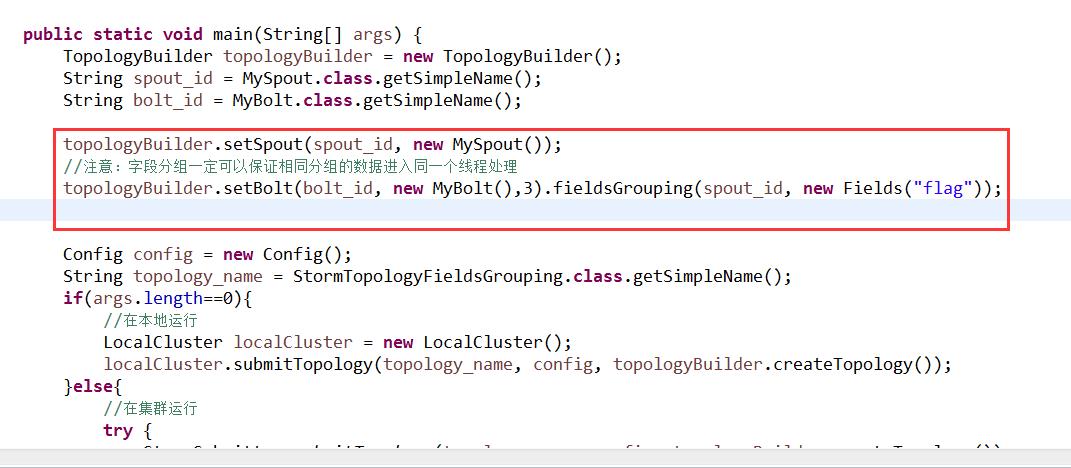
参考代码StormTopologyFieldsGrouping.java
1 package yehua.storm; 2 3 import java.util.Map; 4 5 import org.apache.storm.Config; 6 import org.apache.storm.LocalCluster; 7 import org.apache.storm.StormSubmitter; 8 import org.apache.storm.generated.AlreadyAliveException; 9 import org.apache.storm.generated.AuthorizationException; 10 import org.apache.storm.generated.InvalidTopologyException; 11 import org.apache.storm.spout.SpoutOutputCollector; 12 import org.apache.storm.task.OutputCollector; 13 import org.apache.storm.task.TopologyContext; 14 import org.apache.storm.topology.OutputFieldsDeclarer; 15 import org.apache.storm.topology.TopologyBuilder; 16 import org.apache.storm.topology.base.BaseRichBolt; 17 import org.apache.storm.topology.base.BaseRichSpout; 18 import org.apache.storm.tuple.Fields; 19 import org.apache.storm.tuple.Tuple; 20 import org.apache.storm.tuple.Values; 21 import org.apache.storm.utils.Utils; 22 23 /** 24 * FieldsGrouping 25 * 字段分组 26 * @author yehua 27 * 28 */ 29 30 public class StormTopologyFieldsGrouping { 31 32 public static class MySpout extends BaseRichSpout{ 33 private Map conf; 34 private TopologyContext context; 35 private SpoutOutputCollector collector; 36 //@Override 37 public void open(Map conf, TopologyContext context, 38 SpoutOutputCollector collector) { 39 this.conf = conf; 40 this.collector = collector; 41 this.context = context; 42 } 43 44 int num = 0; 45 //@Override 46 public void nextTuple() { 47 num++; 48 System.out.println("spout:"+num); 49 this.collector.emit(new Values(num,num%2)); 50 Utils.sleep(1000); 51 } 52 53 //@Override 54 public void declareOutputFields(OutputFieldsDeclarer declarer) { 55 declarer.declare(new Fields("num","flag")); 56 } 57 58 } 59 60 61 62 public static class MyBolt extends BaseRichBolt{ 63 64 private Map stormConf; 65 private TopologyContext context; 66 private OutputCollector collector; 67 //@Override 68 public void prepare(Map stormConf, TopologyContext context, 69 OutputCollector collector) { 70 this.stormConf = stormConf; 71 this.context = context; 72 this.collector = collector; 73 } 74 75 //@Override 76 public void execute(Tuple input) { 77 Integer num = input.getIntegerByField("num"); 78 System.err.println("thread:"+Thread.currentThread().getId()+",num="+num); 79 } 80 81 //@Override 82 public void declareOutputFields(OutputFieldsDeclarer declarer) { 83 84 } 85 86 } 87 88 89 90 public static void main(String[] args) { 91 TopologyBuilder topologyBuilder = new TopologyBuilder(); 92 String spout_id = MySpout.class.getSimpleName(); 93 String bolt_id = MyBolt.class.getSimpleName(); 94 95 topologyBuilder.setSpout(spout_id, new MySpout()); 96 //注意:字段分组一定可以保证相同分组的数据进入同一个线程处理 97 topologyBuilder.setBolt(bolt_id, new MyBolt(),2).fieldsGrouping(spout_id, new Fields("flag")); 98 99 100 Config config = new Config(); 101 String topology_name = StormTopologyFieldsGrouping.class.getSimpleName(); 102 if(args.length==0){ 103 //在本地运行 104 LocalCluster localCluster = new LocalCluster(); 105 localCluster.submitTopology(topology_name, config, topologyBuilder.createTopology()); 106 }else{ 107 //在集群运行 108 try { 109 StormSubmitter.submitTopology(topology_name, config, topologyBuilder.createTopology()); 110 } catch (AlreadyAliveException e) { 111 e.printStackTrace(); 112 } catch (InvalidTopologyException e) { 113 e.printStackTrace(); 114 } catch (AuthorizationException e) { 115 e.printStackTrace(); 116 } 117 } 118 119 } 120 121 }
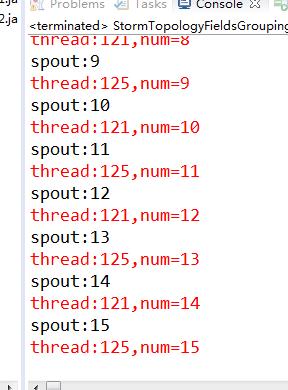
这里补充一下,比如说有两类数据3个线程的时候
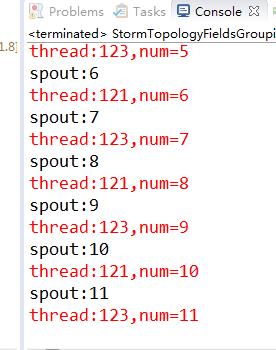
我们再看看运行结果,发现只有两个线程干活了
还有一种情况,只有一个线程的情况,还是两类数据
从运行结果看出来,所有话一个进程干完了
allGrouping方法
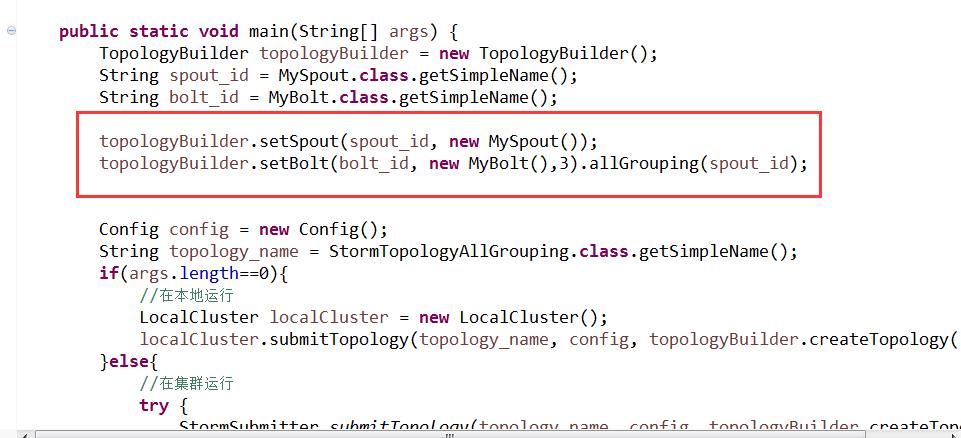
运行结果:spout每发一条数据三个进程都接收到了(基本没什么应用场景)

参考代码StormTopologyAllGrouping.java
1 package yehua.storm; 2 3 import java.util.Map; 4 5 import org.apache.storm.Config; 6 import org.apache.storm.LocalCluster; 7 import org.apache.storm.StormSubmitter; 8 import org.apache.storm.generated.AlreadyAliveException; 9 import org.apache.storm.generated.AuthorizationException; 10 import org.apache.storm.generated.InvalidTopologyException; 11 import org.apache.storm.spout.SpoutOutputCollector; 12 import org.apache.storm.task.OutputCollector; 13 import org.apache.storm.task.TopologyContext; 14 import org.apache.storm.topology.OutputFieldsDeclarer; 15 import org.apache.storm.topology.TopologyBuilder; 16 import org.apache.storm.topology.base.BaseRichBolt; 17 import org.apache.storm.topology.base.BaseRichSpout; 18 import org.apache.storm.tuple.Fields; 19 import org.apache.storm.tuple.Tuple; 20 import org.apache.storm.tuple.Values; 21 import org.apache.storm.utils.Utils; 22 23 /** 24 * AllGrouping 25 * 广播分组 26 * @author yehua 27 * 28 */ 29 30 public class StormTopologyAllGrouping { 31 32 public static class MySpout extends BaseRichSpout{ 33 private Map conf; 34 private TopologyContext context; 35 private SpoutOutputCollector collector; 36 //@Override 37 public void open(Map conf, TopologyContext context, 38 SpoutOutputCollector collector) { 39 this.conf = conf; 40 this.collector = collector; 41 this.context = context; 42 } 43 44 int num = 0; 45 //@Override 46 public void nextTuple() { 47 num++; 48 System.out.println("spout:"+num); 49 this.collector.emit(new Values(num)); 50 Utils.sleep(1000); 51 } 52 53 //@Override 54 public void declareOutputFields(OutputFieldsDeclarer declarer) { 55 declarer.declare(new Fields("num")); 56 } 57 58 } 59 60 61 62 public static class MyBolt extends BaseRichBolt{ 63 64 private Map stormConf; 65 private TopologyContext context; 66 private OutputCollector collector; 67 //@Override 68 public void prepare(Map stormConf, TopologyContext context, 69 OutputCollector collector) { 70 this.stormConf = stormConf; 71 this.context = context; 72 this.collector = collector; 73 } 74 75 //@Override 76 public void execute(Tuple input) { 77 Integer num = input.getIntegerByField("num"); 78 System.err.println("thread:"+Thread.currentThread().getId()+",num="+num); 79 } 80 81 //@Override 82 public void declareOutputFields(OutputFieldsDeclarer declarer) { 83 84 } 85 86 } 87 88 89 90 public static void main(String[] args) { 91 TopologyBuilder topologyBuilder = new TopologyBuilder(); 92 String spout_id = MySpout.class.getSimpleName(); 93 String bolt_id = MyBolt.class.getSimpleName(); 94 95 topologyBuilder.setSpout(spout_id, new MySpout()); 96 topologyBuilder.setBolt(bolt_id, new MyBolt(),3).allGrouping(spout_id); 97 98 99 Config config = new Config(); 100 String topology_name = StormTopologyAllGrouping.class.getSimpleName(); 101 if(args.length==0){ 102 //在本地运行 103 LocalCluster localCluster = new LocalCluster(); 104 localCluster.submitTopology(topology_name, config, topologyBuilder.createTopology()); 105 }else{ 106 //在集群运行 107 try { 108 StormSubmitter.submitTopology(topology_name, config, topologyBuilder.createTopology()); 109 } catch (AlreadyAliveException e) { 110 e.printStackTrace(); 111 } catch (InvalidTopologyException e) { 112 e.printStackTrace(); 113 } catch (AuthorizationException e) { 114 e.printStackTrace(); 115 } 116 } 117 118 } 119 120 }
LocalOrShufferGrouping方法
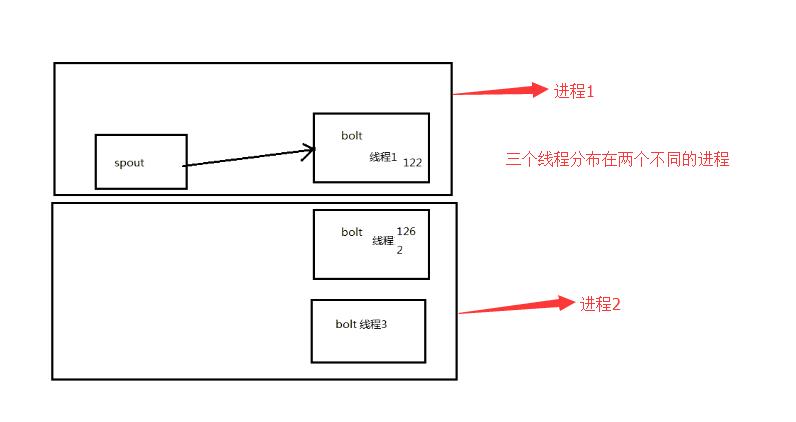
spout只会给同一个主机的线程发送数据(图中的线程1),也就是在同一个线程里会被发送数据,这样做的好处就是在同一个进程里发送数据效率搞,不用跨主机传输
但是当数据量太大的时候,线程1处理不了的时候就麻烦了,所以在实际工作中不建议这样做。
这里用的是3个线程(3个bolt),2个进程(2个worker)
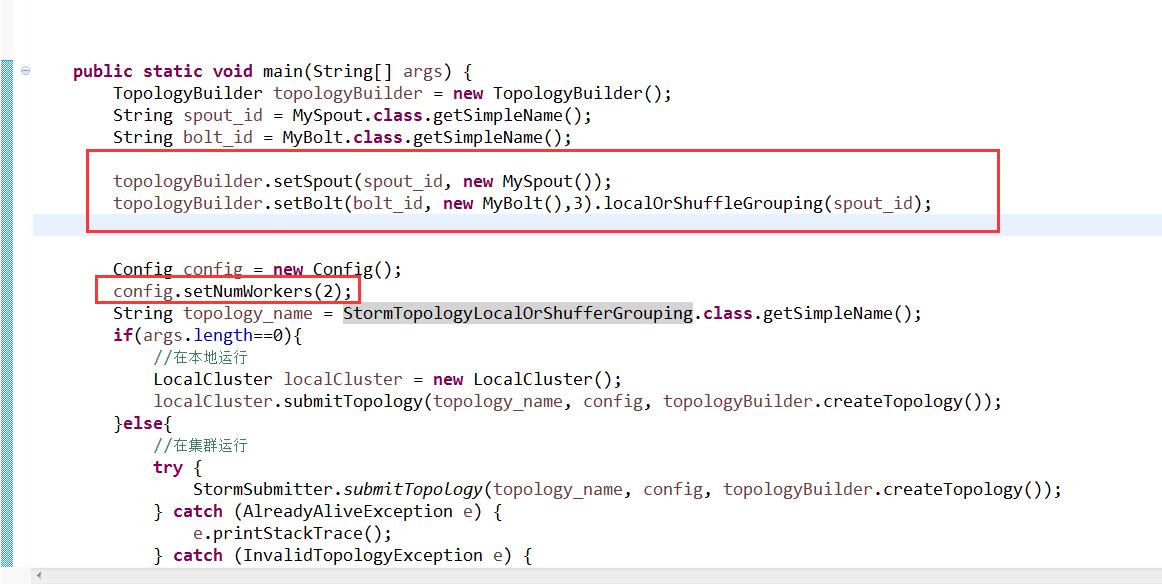
从运行的结果我们可以看出来,只有一个线程在接收数据
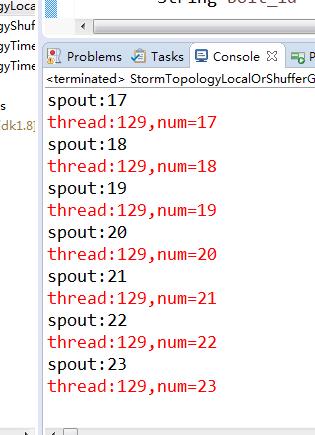
还有一种情况,如果本地没有线程的时候,他就跟ShufferGrouping的效果一样的

参考代码StormTopologyLocalOrShufferGrouping.java
1 package yehua.storm; 2 3 import java.util.Map; 4 5 import org.apache.storm.Config; 6 import org.apache.storm.LocalCluster; 7 import org.apache.storm.StormSubmitter; 8 import org.apache.storm.generated.AlreadyAliveException; 9 import org.apache.storm.generated.AuthorizationException; 10 import org.apache.storm.generated.InvalidTopologyException; 11 import org.apache.storm.spout.SpoutOutputCollector; 12 import org.apache.storm.task.OutputCollector; 13 import org.apache.storm.task.TopologyContext; 14 import org.apache.storm.topology.OutputFieldsDeclarer; 15 import org.apache.storm.topology.TopologyBuilder; 16 import org.apache.storm.topology.base.BaseRichBolt; 17 import org.apache.storm.topology.base.BaseRichSpout; 18 import org.apache.storm.tuple.Fields; 19 import org.apache.storm.tuple.Tuple; 20 import org.apache.storm.tuple.Values; 21 import org.apache.storm.utils.Utils; 22 23 /** 24 * LocalAllshufferGrouping 25 * @author yehua 26 * 27 */ 28 29 public class StormTopologyLocalOrShufferGrouping { 30 31 public static class MySpout extends BaseRichSpout{ 32 private Map conf; 33 private TopologyContext context; 34 private SpoutOutputCollector collector; 35 //@Override 36 public void open(Map conf, TopologyContext context, 37 SpoutOutputCollector collector) { 38 this.conf = conf; 39 this.collector = collector; 40 this.context = context; 41 } 42 43 int num = 0; 44 //@Override 45 public void nextTuple() { 46 num++; 47 System.out.println("spout:"+num); 48 this.collector.emit(new Values(num)); 49 Utils.sleep(1000); 50 } 51 52 //@Override 53 public void declareOutputFields(OutputFieldsDeclarer declarer) { 54 declarer.declare(new Fields("num")); 55 } 56 57 } 58 59 60 61 public static class MyBolt extends BaseRichBolt{ 62 63 private Map stormConf; 64 private TopologyContext context; 65 private OutputCollector collector; 66 //@Override 67 public void prepare(Map stormConf, TopologyContext context, 68 OutputCollector collector) { 69 this.stormConf = stormConf; 70 this.context = context; 71 this.collector = collector; 72 } 73 74 //@Override 75 public void execute(Tuple input) { 76 Integer num = input.getIntegerByField("num"); 77 System.err.println("thread:"+Thread.currentThread().getId()+",num="+num); 78 } 79 80 //@Override 81 public void declareOutputFields(OutputFieldsDeclarer declarer) { 82 83 } 84 85 } 86 87 88 89 public static void main(String[] args) { 90 TopologyBuilder topologyBuilder = new TopologyBuilder(); 91 String spout_id = MySpout.class.getSimpleName(); 92 String bolt_id = MyBolt.class.getSimpleName(); 93 94 topologyBuilder.setSpout(spout_id, new MySpout()); 95 topologyBuilder.setBolt(bolt_id, new MyBolt(),3).localOrShuffleGrouping(spout_id); 96 97 98 Config config = new Config(); 99 config.setNumWorkers(2); 100 String topology_name = StormTopologyLocalOrShufferGrouping.class.getSimpleName(); 101 if(args.length==0){ 102 //在本地运行 103 LocalCluster localCluster = new LocalCluster(); 104 localCluster.submitTopology(topology_name, config, topologyBuilder.createTopology()); 105 }else{ 106 //在集群运行 107 try { 108 StormSubmitter.submitTopology(topology_name, config, topologyBuilder.createTopology()); 109 } catch (AlreadyAliveException e) { 110 e.printStackTrace(); 111 } catch (InvalidTopologyException e) { 112 e.printStackTrace(); 113 } catch (AuthorizationException e) { 114 e.printStackTrace(); 115 } 116 } 117 118 } 119 120 }
以上是关于storm的流分组的主要内容,如果未能解决你的问题,请参考以下文章