机器人--推荐系统
Posted LeLe.xu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器人--推荐系统相关的知识,希望对你有一定的参考价值。
430的目标是完成机器人的推荐系统,提高机器人回答问题的准确率,关于过程碰到的问题以及解决方案与大家分享一下,(请轻喷!)
那么这个推荐系统到底应该怎么做呢?
最开始的第一个思路是 根据用户 进入到ERP的模块 推荐该模块下的相关问题。其实就是根据用户的轨迹来推荐问题,这是一个思路但是不太完整。因为很有可能用户就从ERP的桌面就进入了机器人,但他实际要咨询的是销售系统的相关知识,那么此时的推荐就不太满足用户的咨询需求。
因此参考一些业界其他公司的做法,可以基于内容的协同过滤(Collaborative Filtering,即CF)来设计机器人推荐系统。
那么什么是基于内容的协同过滤,一个最经典的例子就是看电影,有时候不知道哪一部电影是我们喜欢的或者评分比较高的,那么通常的做法就是问问周围的朋友,看看最近有什么好的电影推荐。在问的时候,都习惯于问跟自己口味差不多的朋友,这就是协同过滤的核心思想。
协同过滤是在海量数据中挖掘出小部分与你品味类似的用户,并让这些用户成为邻居,然后根据他
们喜欢的东西组织成一个排序的目录推荐给你。所以就有如下两个核心问题
(1)如何确定一个用户是否与你有相似的问题?
(2)如何将邻居们的喜好咨询的问题组织成一个排序目录?
协同过滤算法包括基于用户和基于物品的协同过滤算法。so 我们应该怎么做呢
1、收集用户偏好习惯
机器人经过一段时间的积累,已经积累了一些用户经常咨询的问题以及对问题的反馈,以及一些问题本身的属性,比如问题的类型、以及问题所属的模块系统
2、数据预处理
一、降燥处理,主要针对对于用户的误操作数据进行过滤,减少对整体数据的影响
二、归一化处理,不同行为数据的取值相差可能很大,通过归一化,才能使数据更加准确。
3、经过上述处理后
我们得到一张用户的user profile的二维的矩阵。如图:
I1 I2 I3 U1 1 1 1 U2 1 0 0 U3 0 1 0
u表示用户,k表示知识库条目
1:表示机器人对用户咨询问题反馈的知识库条目有效,0:则表示无效。
同样的道理,我们可以建立知识库条目的item profile 二维矩阵,每一个知识库条目 有所属的子系统、所属模块、以及当前的问题类型等。在这里我截取了4个属性,所属子系统、所属一级模块、所属二级模块,以及问题类型。如图:
attr1 | attr2 | attr3 | attr4 | |
I1 | 0.01 | 0.02 | 0.08 | 0.33 |
I2 | 0.01 | 0.03 | 0.17 | 0.5 |
I3 | 0.98 | 0.95 | 0.75 | 0.17 |
4、计算相似度
有了评分矩阵以后,那么开始要找到用户相似度及物品相似度了。
推荐系统中通常使用余弦相似性作为距离度量,在n维孔空间中评价被视为向量,基于这些向量之间的夹角来计算相似性。
计算用户k与用户a的相似度:
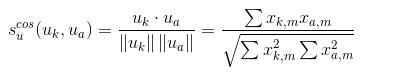
计算条目m与条目b的相似度:
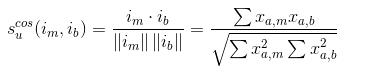
经过计算以后,我们可以拿到用户和物品的相似度矩阵。
5、推荐
准备了这么多,最后最终的目的还是要进行推荐,刚刚我们提到了2个算法,基于用户的协同过滤和基于物品的协同过滤,(虽然可以百度到,但是补充说明一下)
基于用户的协同过滤,因为我们计算出了用户的相似度矩阵,如图:
u1 u2 u3 u1 0 0.156874 0.21221 u2 0.14213 0 0.56231 u3 0.165984 0.62123 0
然后我们还可以设计一个权重,根据最近邻居的相似度以及它们对物品的偏好,预测当前用户偏好的但未涉及条目,计算得到一个排序的条目列表进行推荐
基于物品的协同过滤,类似的我们还可以拿到一个物品的相似度矩阵(不贴图了),他是从物品本身出发,比如A喜欢咨询知识库条目k,那么我们根据物品相似度矩阵,拿到与k相似的并且用户A并未咨询过的条目推荐给A。
6、评估
用于评估预测精确度的指标之一是Root Mean Squared Error(RMSE)
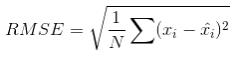
所以我们可以直接用sklearn中的mean_square_error(mse)函数,然后再求个平方根,就是RMSE。
结果如图:

从最终的结果来看,基于用户与基于物品的预测精确度差距不大,同时,由于基于物品计算复杂会比基于用户的计算复杂少很多,目前采用就是基于物品的协同过滤算法。
两种算法的适用场景请参考:
https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/index.html
7、后续
推荐系统在业界一直有一个问题比较难处理,就是冷启动,由于收集到的用户信息不足,导致数据稀疏,推荐效果不是很不理想;那么解决方案是基于模型的协同过滤(MF),采用奇异值分解算法svd。他的推荐效果很不错,如图:
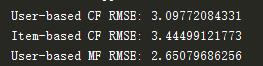
(ps:相对svd算法的复杂度是最高的。。。。。对于没有GPU必要设备的我们来说只能放弃了)
言归正传,后续准备分享建设机器人寒暄库,让机器人可以口吐"人言",甚至口吐"甄嬛体"。
目前还需要童鞋帮忙建设寒暄库,各路大神有时间的,助小的一臂之力。
推荐资料:
https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/index.html
http://blog.163.com/lnhenrylee@126/blog/static/2414832520123269713813/
以上是关于机器人--推荐系统的主要内容,如果未能解决你的问题,请参考以下文章