机器人--寒暄库(数据准备2)
Posted LeLe.xu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器人--寒暄库(数据准备2)相关的知识,希望对你有一定的参考价值。
上次说了机器人的寒暄库需要基于seq2seq模型来做训练,训练的前提是我们准备好了足够的数据。
这次来说一下数据准备工作。
数据的来源一般分为内部已有的积累数据,另一个就是互联网数据,比如百度。。。百度几乎就是互联网的一个镜像。内部积累的文本数据有限,远不如网络数据丰富。so我们就要考虑怎么获取到网络文本数据了,可能你已经猜到了,那就是爬虫。
python的scrapy是一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据
安装
yum install libffi-devel
yum install openssl-devel
pip install scrapy
中文教程:http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
创建项目
scrapy startproject myrobot_search

项目结构:
settings.py是爬虫的配置文件
USER_AGENT是ua,也就是发http请求时指明我是谁,因为我们的目的不纯,所以我们伪造成浏览器,改成
USER_AGENT = \'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36\'
ROBOTSTXT_OBEY表示是否遵守robots协议(被封禁的不抓取),因为我们的目的不纯,所以我们不遵守,改成
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY表示对同一个站点抓取延迟,也就是抓一个,歇一会,为了对方站点冲击,我们调整为1,也就是一秒抓一个CONCURRENT_REQUESTS_PER_DOMAIN表示对同一个站点并发有多少个线程抓取,同样道理,我们也调整为1
CONCURRENT_REQUESTS_PER_IP同理也调整为1
编写项目
新建一个爬虫文件RobotSearchSpider.py,如下:
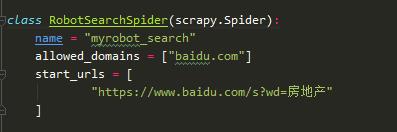
爬虫命名为 myrobot_search.
允许爬取的域名 baidu.com
爬虫初始爬取的种子链接:https://www.baidu.com/s?wd=房地产
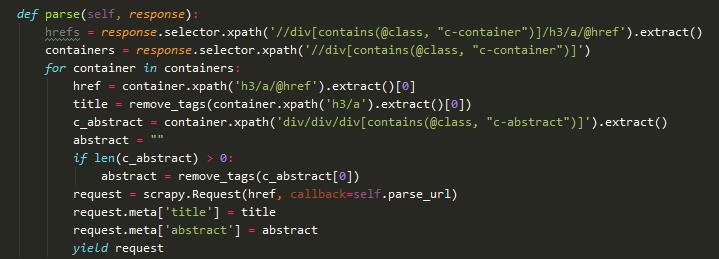
parse方法会对爬取后的内容进行解析。如图:
思路:通过百度搜索 "房地产"这个关键词,我们看如下结果:
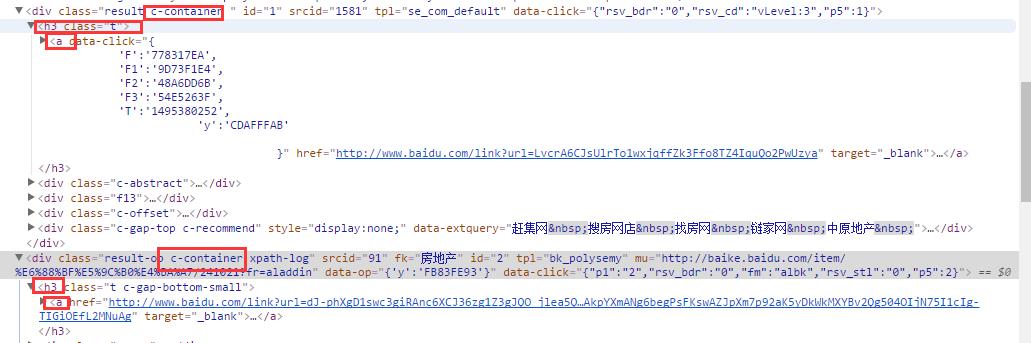
每个url都是在 class="c-container" 标签下的<h3>下的<a>标签中href属性。so我们用python提供的selector选择器进行文本解析。
同理,通过for container in containers: 依次取出container下的 url、title、abstract。
然后递归调用scrapy.Request(href,callback=self.parse_url) parse_url方法获取content。如题:

执行项目
写完后,我们进入到该目录下执行脚本命令:scrapy runspider RobotSearchSpider.py
结果如图:
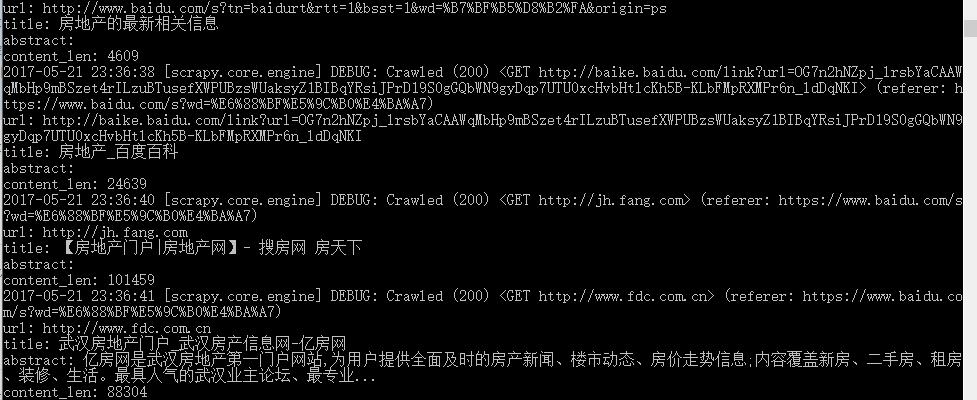
结果提取到以后,就要开始数据入库了,这时候就要用到item.py文件了。这个不细说了,看官方文档即可。
以上是关于机器人--寒暄库(数据准备2)的主要内容,如果未能解决你的问题,请参考以下文章