Secondary NameNode究竟是做什么的
Posted 小流积江河,跬步至千里
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Secondary NameNode究竟是做什么的相关的知识,希望对你有一定的参考价值。
Secondary NameNode:它究竟有什么作用?
在hadoop中,有一些命名不好的模块,Secondary NameNode是其中之一。从它的名字上看,它给人的感觉就像是NameNode的备份。但它实际上却不是。很多Hadoop的初学者都很疑惑,Secondary NameNode究竟是做什么的,而且它为什么会出现在HDFS中。因此,在这篇文章中,我想要解释下Secondary NameNode在HDFS中所扮演的角色。
从它的名字来看,你可能认为它跟NameNode有点关系。没错,你猜对了。因此在我们深入了解Secondary NameNode之前,我们先来看看NameNode是做什么的。
NameNode
NameNode主要是用来保存HDFS的元数据信息,比如命名空间信息,块信息等。当它运行的时候,这些信息是存在内存中的。但是这些信息也可以持久化到磁盘上。
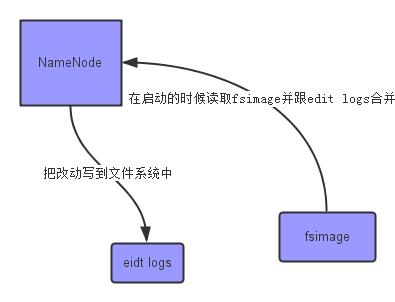
上面的这张图片展示了NameNode怎么把元数据保存到磁盘上的。这里有两个不同的文件:
- fsimage - 它是在NameNode启动时对整个文件系统的快照
- edit logs - 它是在NameNode启动后,对文件系统的改动序列
只有在NameNode重启时,edit logs才会合并到fsimage文件中,从而得到一个文件系统的最新快照。但是在产品集群中NameNode是很少重启的,这也意味着当NameNode运行了很长时间后,edit logs文件会变得很大。在这种情况下就会出现下面一些问题:
- edit logs文件会变的很大,怎么去管理这个文件是一个挑战。
- NameNode的重启会花费很长时间,因为有很多改动[笔者注:在edit logs中]要合并到fsimage文件上。
- 如果NameNode挂掉了,那我们就丢失了很多改动因为此时的fsimage文件非常旧。[笔者注: 笔者认为在这个情况下丢失的改动不会很多, 因为丢失的改动应该是还在内存中但是没有写到edit logs的这部分。]
因此为了克服这个问题,我们需要一个易于管理的机制来帮助我们减小edit logs文件的大小和得到一个最新的fsimage文件,这样也会减小在NameNode上的压力。这跟Windows的恢复点是非常像的,Windows的恢复点机制允许我们对OS进行快照,这样当系统发生问题时,我们能够回滚到最新的一次恢复点上。
现在我们明白了NameNode的功能和所面临的挑战 - 保持文件系统最新的元数据。那么,这些跟Secondary NameNode又有什么关系呢?
Secondary NameNode
SecondaryNameNode就是来帮助解决上述问题的,它的职责是合并NameNode的edit logs到fsimage文件中。
下面我们来看一下SecondaryNameNode工作的流程,如下图:
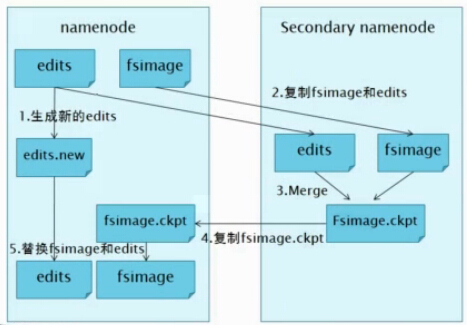
1.NameNode管理着元数据信息,元数据信息会定期的刷到磁盘中,其中的两个文件是edits即操作日志文件和fsimage即元数据镜像文件,新的操作日志不会立即与fsimage进行合并,也不会刷到NameNode的内存中,而是会先写到edits中(因为合并需要消耗大量的资源)。当edits文件的大小达到一个临界值(默认是64MB)或者间隔一段时间(默认是1小时)的时候checkpoint会触发SecondaryNameNode进行工作。
2.当触发一个checkpoint操作时,NameNode会生成一个新的edits即上图中的edits.new文件,同时SecondaryNameNode会将edits文件和fsimage复制到本地。
3.SecondaryNameNode将本地的fsimage文件加载到内存中,然后再与edits文件进行合并生成一个新的fsimage文件即上图中的Fsimage.ckpt文件。
4.SecondaryNameNode将新生成的Fsimage.ckpt文件复制到NameNode节点。
5.在NameNode结点的edits.new文件和Fsimage.ckpt文件会替换掉原来的edits文件和fsimage文件,至此,刚好一个轮回即在NameNode中又是edits和fsimage文件了。
6.等待下一次checkpoint触发SecondaryNameNode进行工作,一直这样循环操作。
说明:新生成的edits.new应该是一个空文件,此时若NameNode元信息出现了改动,则会被写入到edits.new中。
Secondary NameNode的整个目的是在HDFS中提供一个检查点。它只是NameNode的一个助手节点。这也是它在社区内被认为是检查点节点的原因。现在,我们明白了Secondary NameNode所做的不过是在文件系统中设置一个检查点来帮助NameNode更好的工作。它不是要取代掉NameNode也不是NameNode的备份。所以从现在起,让我们养成一个习惯,称呼它为检查点节点吧。
Secondary NameNode是hadoop1.x中HDFS HA的一个解决方案,在实际的生产系统中只能减少系统宕机时丢失的数据量,减少系统重启时间,但是并不能降低NameNode宕机风险。在hadoop2.x中都是采用NameNode HA的解决方案!
参考链接:
http://blog.csdn.net/xh16319/article/details/31375197
http://www.cnblogs.com/thinkpad/p/5173705.html
以上是关于Secondary NameNode究竟是做什么的的主要内容,如果未能解决你的问题,请参考以下文章