什么是随机森林
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是随机森林相关的知识,希望对你有一定的参考价值。
参考技术ABagging是 bootstrap aggregating 。思想就是从总体样本当中 随机取一部分样本进行训练,通过多次这样的结果,进行投票获取平均值作为结果输出 ,这就极大可能的 避免了不好的样本数据,从而提高准确度 。因为有些是不好的样本,相当于噪声,模型学入噪声后会使准确度不高。Bagging降低 Variance ,因此采用的都是强学习器。
举个例子 :
假设有1000个样本,如果按照以前的思维,是直接把这1000个样本拿来训练,但现在不一样,先抽取800个样本来进行训练,假如噪声点是这800个样本以外的样本点,就很有效的避开了。重复以上操作,提高模型输出的平均值。
Random Forest(随机森林)是 一种基于树模型的Bagging的优化版本 ,一棵树的生成肯定还是不如多棵树,因此就有了随机森林,解决 决策树泛化能力弱的 特点。(可以理解成三个臭皮匠顶过诸葛亮)
而同一批数据,用同样的算法只能产生一棵树,这时Bagging策略可以 帮助我们产生不同的数据集 。 Bagging 策略来源于bootstrap aggregation:从样本集(假设样本集N个数据点)中重采样选出Nb个样本(有放回的采样,样本数据点个数仍然不变为N),在所有样本上,对这n个样本建立分类器(ID3\\C4.5\\CART\\SVM\\LOGISTIC), 重复以上两步m次,获得m个分类器 ,最后根据这m个分类器的投票结果,决定数据属于哪一类。
每棵树的按照如下规则生成:
一开始我们提到的随机森林中的“随机”就是指的这里的两个随机性。两个随机性的引入对随机森林的分类性能至关重要。由于它们的引入,使得随机森林 不容易陷入过拟合,并且具有很好得抗噪能力 (比如:对缺省值不敏感)。
总的来说就是随机选择样本数,随机选取特征,随机选择分类器,建立多颗这样的决策树,然后通过这几课决策树来投票,决定数据属于哪一类( 投票机制有一票否决制、少数服从多数、加权多数 )
减小 特征选择个数m,树的相关性和分类能力也会相应的降低 ;增大m,两者也会随之增大。所以关键问题是 如何选择最优的m (或者是范围),这也是随机森林唯一的一个参数。
优点:
缺点:
根据随机森林创建和训练的特点,随机森林对缺失值的处理还是比较特殊的。
其实,该缺失值填补过程类似于推荐系统中采用协同过滤进行评分预测,先计算缺失特征与其他特征的相似度,再加权得到缺失值的估计,而随机森林中计算相似度的方法(数据在决策树中一步一步分类的路径)乃其独特之处。
OOB :
上面我们提到,构建随机森林的关键问题就是 如何选择最优的m ,要解决这个问题主要依据计算 袋外错误率oob error(out-of-bag error) 。
bagging方法中Bootstrap每次约有 1/3的样本不会出现在Bootstrap所采集的样本集合中 ,当然也就没有参加决策树的建立,把这1/3的数据称为 袋外数据oob(out of bag) ,它可以用于 取代测试集误差估计方法 。
袋外数据(oob)误差的计算方法如下:
优缺点 :
这已经经过证明是 无偏估计的 ,所以在随机森林算法中 不需要再进行交叉验证或者单独的测试集来获取测试集误差 的无偏估计。
为什么极度随机树比随机森林更随机?这个极度随机的特性有什么好处?在训练阶段极度随机数比随机森林快还是慢?
为什么极度随机树比随机森林更随机?这个极度随机的特性有什么好处?在训练阶段、极度随机数比随机森林快还是慢?
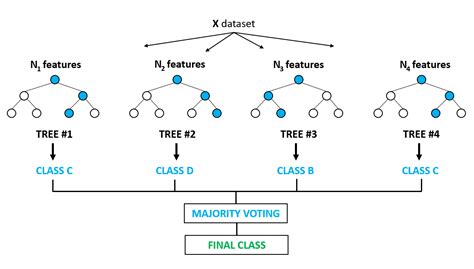
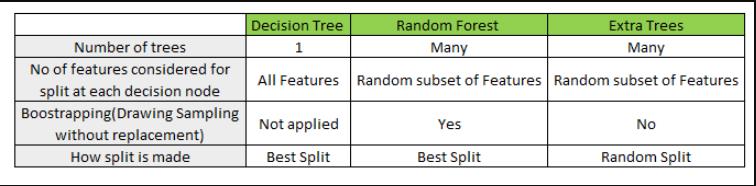
ExtRa Trees是Extremely Randomized Trees的缩写,意思就是极度随机树。极端随机树,简称ExtRa Trees,是一种集成机器学习算法。具体地说,它是一个决策树的集成学习方法,并与其他决策树集成算法相关,如bagging和随机森林(random forest)。
极度随机树比常规随机森林更具有随机性(Randomness),因为该模型在每次分裂或者分枝的时都会随机选择一个特征子集进行分枝特征的选择,而且该模型不需要选择最佳阈值,而是采用随机阈值进行分枝。
也就是说,ExtRa Trees算法在每个节点随机选择和一个特征子集,并且随机分裂来获取最优的分枝属性和分枝阈值(随机森林是有固定的个数的特征子集进行最优分裂);
这种增加的随机性有助于创建更多彼此独立的决策树(各个子决策树约独立,综合的效果就越符合大数定律),并有助于训练一个好的集成学习模型。
极度随机树比常规随机林模型训
以上是关于什么是随机森林的主要内容,如果未能解决你的问题,请参考以下文章