Spark2.0源码学习-10.Task执行与回馈
Posted hframe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark2.0源码学习-10.Task执行与回馈相关的知识,希望对你有一定的参考价值。
通过上一节内容,DriverEndpoint最终生成多个可执行的TaskDescription对象,并向各个ExecutorEndpoint发送LaunchTask指令,本节内容将关注ExecutorEndpoint如何处理LaunchTask指令,处理完成后如何回馈给DriverEndpoint,以及整个job最终如何多次调度直至结束。
一、Task的执行流程
承接上一节内容,Executor接受LaunchTask指令后,开启一个新线程TaskRunner解析RDD,并调用RDD的compute方法,归并函数得到最终任务执行结果

- ExecutorEndpoint接受到LaunchTask指令后,解码出TaskDescription,调用Executor的launchTask方法
- Executor创建一个TaskRunner线程,并启动线程,同时将改线程添加到Executor的成员对象中,代码如下:
private val runningTasks = new ConcurrentHashMap[Long, TaskRunner] runningTasks.put(taskDescription.taskId, taskRunner)
- TaskRunner
-
- 首先向DriverEndpoint发送任务最新状态为RUNNING
- 从TaskDescription解析出Task,并调用Task的run方法
- Task
-
- 创建TaskContext以及CallerContext(与HDFS交互的上下文对象)
- 执行Task的runTask方法
-
- 如果Task实例为ShuffleMapTask:解析出RDD以及ShuffleDependency信息,调用RDD的compute()方法将结果写Writer中(Writer这里不介绍,可以作为黑盒理解,比如写入一个文件中),返回MapStatus对象
- 如果Task实例为ResultTask:解析出RDD以及合并函数信息,调用函数将调用后的结果返回
- TaskRunner将Task执行的结果序列化,再次向DriverEndpoint发送任务最新状态为FINISHED
二、Task的回馈流程
TaskRunner执行结束后,都将执行状态发送至DriverEndpoint,DriverEndpoint最终反馈指令CompletionEvent至DAGSchedulerEventProcessLoop中
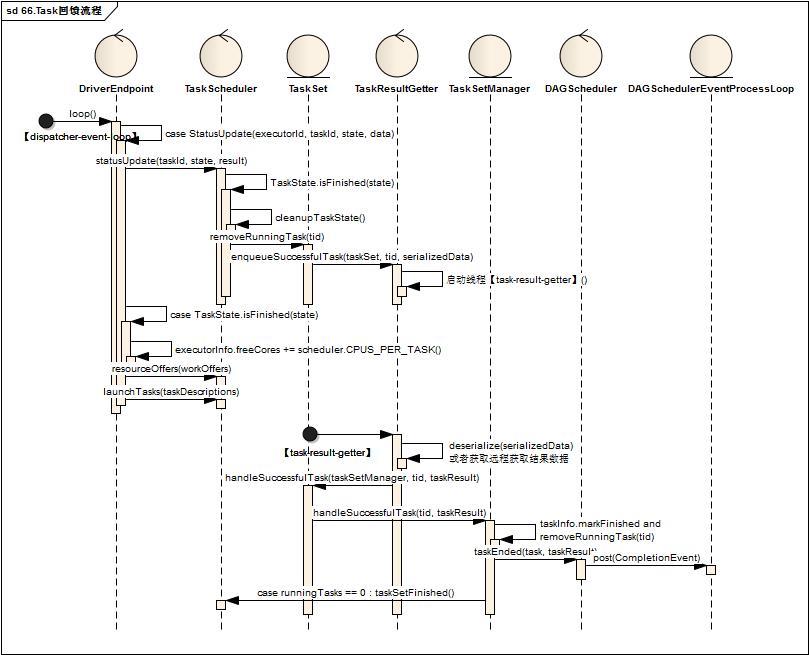
- DriverEndpoint接受到StatusUpdate消息后,调用TaskScheduler的statusUpdate(taskId, state, result)方法
- TaskScheduler如果任务结果是完成,那么清除该任务处理中的状态,并调动TaskResultGetter相关方法,关键代码如下:
val taskSet = taskIdToTaskSetManager.get(tid) taskIdToTaskSetManager.remove(tid) taskIdToExecutorId.remove(tid).foreach { executorId => executorIdToRunningTaskIds.get(executorId).foreach { _.remove(tid) } } taskSet.removeRunningTask(tid) if (state == TaskState.FINISHED) { taskResultGetter.enqueueSuccessfulTask(taskSet, tid, serializedData) } else if (Set(TaskState.FAILED, TaskState.KILLED, TaskState.LOST).contains(state)) { taskResultGetter.enqueueFailedTask(taskSet, tid, state, serializedData) }
- TaskResultGetter启动线程启动线程【task-result-getter】进行相关处理
-
- 通过解析或者远程获取得到Task的TaskResult对象
- 调用TaskSet的handleSuccessfulTask方法,TaskSet的handleSuccessfulTask方法直接调用TaskSetManager的handleSuccessfulTask方法
- TaskSetManager
-
- 更新内部TaskInfo对象状态,并将该Task从运行中Task的集合删除,代码如下:
val info = taskInfos(tid)
info.markFinished(TaskState.FINISHED, clock.getTimeMillis())
removeRunningTask(tid)
-
- 调用DAGScheduler的taskEnded方法,关键代码如下:
sched.dagScheduler.taskEnded(tasks(index), Success, result.value(), result.accumUpdates, info)
- DAGScheduler向DAGSchedulerEventProcessLoop存入CompletionEvent指令,CompletionEvent对象定义如下
private[scheduler] case class CompletionEvent( task: Task[_], reason: TaskEndReason, result: Any, accumUpdates: Seq[AccumulatorV2[_, _]], taskInfo: TaskInfo) extends DAGSchedulerEvent
三、Task的迭代流程
DAGSchedulerEventProcessLoop中针对于CompletionEvent指令,调用DAGScheduler进行处理,DAGScheduler更新Stage与该Task的关系状态,如果Stage下Task都返回,则做下一层Stage的任务拆解与运算工作,直至Job被执行完毕

- DAGSchedulerEventProcessLoop接收到CompletionEvent指令后,调用DAGScheduler的handleTaskCompletion方法
- DAGScheduler根据Task的类型分别处理
- 如果Task为ShuffleMapTask
-
- 待回馈的Partitions减取当前partitionId
- 如果所有task都返回,则markStageAsFinished(shuffleStage),同时向MapOutputTrackerMaster注册MapOutputs信息,且markMapStageJobAsFinished
- 调用submitWaitingChildStages(shuffleStage)进行下层Stages的处理,从而迭代处理最终处理到ResultTask,job结束,关键代码如下:
private def submitWaitingChildStages(parent: Stage) { ... val childStages = waitingStages.filter(_.parents.contains(parent)).toArray waitingStages --= childStages for (stage <- childStages.sortBy(_.firstJobId)) { submitStage(stage) } }
- 如果Task为ResultTask
-
- 改job的partitions都已返回,则markStageAsFinished(resultStage),并cleanupStateForJobAndIndependentStages(job),关键代码如下
for (stage <- stageIdToStage.get(stageId)) { if (runningStages.contains(stage)) { logDebug("Removing running stage %d".format(stageId)) runningStages -= stage } for ((k, v) <- shuffleIdToMapStage.find(_._2 == stage)) { shuffleIdToMapStage.remove(k) } if (waitingStages.contains(stage)) { logDebug("Removing stage %d from waiting set.".format(stageId)) waitingStages -= stage } if (failedStages.contains(stage)) { logDebug("Removing stage %d from failed set.".format(stageId)) failedStages -= stage } } // data structures based on StageId stageIdToStage -= stageId jobIdToStageIds -= job.jobId jobIdToActiveJob -= job.jobId activeJobs -= job
至此,用户编写的代码最终调用Spark分布式计算完毕。
以上是关于Spark2.0源码学习-10.Task执行与回馈的主要内容,如果未能解决你的问题,请参考以下文章