elasticsearch系列score
Posted ulysses_you
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了elasticsearch系列score相关的知识,希望对你有一定的参考价值。
概述
score在ES中有着很重要的作用,有了它才有了rank,是验证文档相关性的关键数据,score越大代表匹配到的文档相关性越大
官方解释
查询的时候可以用explain来展示score的计算过程,也可以增加format=yaml来讲json转成yaml方便阅读
类似xxx/_search?explain&format=yaml
下图是通过explain看到的一部分json,其实这个解释中就展示出了计算公式,不得不说ES在这点上还是很人性化的
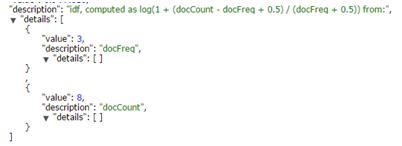
计算方式
常说的相关性是指计算一个全文(full-text)字段的内容与全文查询字符串的相似程度的算法。
这个算法默认是BM25,一个基于TF-IDF(term frequency/inverse document frequency)的算法。
TF-IDF
首先是TF(term frequency),顾名思义,term在field出现的频率越高,则该term与field的相关性越高。
公式:
sqrt(TF)
然后是IDF(inverse document frequency),term在整个index出现的频率越高,则该term与该document的相关性越低。
公式:
Log(numDocs / docFreq + 1) + 1
BM25
BM全称(Best Match),这个名称不得不说有点过分,这个算法也同样有TF和IDF。
TF,BM25把TF的影响范围减小了,不像TF-IDF一样没有边界
公式:
(k+1)* tf /(k + tf),k一般是个常量,[1.2,2],通过k可以改变回归的速度。
IDF几乎一样,只是多加了1(为了提高其整体影响比重)
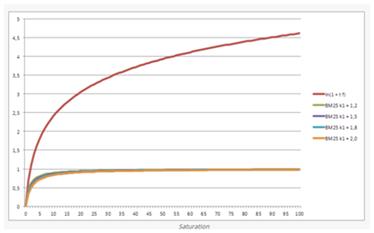
BM25新加了另一个特征,Field-length norm,field的长度有多少,如果field的长度越长,则该term与field的相关性越低(分母越大,概率越小)。
公式:
|d|/avgDl(本文档的长度除以平均文档的长度)
下图为不同文档长度对应相同tf所影响最终tf的曲线。
公式:
(k + 1)* tf / k * ( 1.0 - b + b - L + tf) (其中b为常数)
BM25 Field-length norm之间的对比

TF-IDF和BM25对比
在TF角度的对比
计算流程
Score的计算过程依赖query clause(查询子条件),例如:
1.模糊查询计算匹配到的word和原来的word(匹配前的word)的相似度
2.term查询会包含找到该term所占的百分比
个别查询会结合TF-IDF的socre和其它因素,越多的query clause(查询子条件)匹配到,那么score就越高,具体来说,是query clause匹配得到的score联合起来计算出最终的score。
需要注意的是,TF-IDF默认是基于shard来计算的,假设1个index有5个shards,则就有5个TF-IDF的结果,也就是5个score,然后score再汇聚到request node,做排序后得到最终结果。所以这有产生了另一个问题,当index的documents数量较少时,score的结果会不准确,毕竟不是全局的,shard也只是通过hash来区分,有很大的随机性和偶然性。针对这种情况,ES给出了DFS Query Then Fetch(默认是采用Query Then Fetch)这种解决方案,采用全局计算TF-IDF的方式,解决这个问题,在查询的时候可以这么设置
search_type=dfs_query_then_fetch
(不过会影响效率,毕竟是全局计算,多了几次socket传输)。其实还有一种解决方法,直接把index的shard设置成1,这样自己就代表了全局。
Query Then Fetch
稍微解释一下Query Then Fetch,顾名思义,是先查询后获取。
查询流程如下

score as percentage
刚接触score的时候,总有疑惑,为什么不是一个百分比,这样可能更加直观的表现出匹配到正确的概率,也就是术语”normalized socre”。
这么想是错误的!
Score的意义仅仅在于对比一次查询的多个结果的对比,起到rank作用,并不能代表匹配到的概率,更不能拿几个匹配到的概率做比较,比如:当一个document本身没有发生变化,但是index发生变化,就会影响匹配到document的sorce。这样的概率是没什么意义的,虽然你可以强行造出一个概率。
另外
在做业务的过程中领悟到,搜索系统和推荐系统不是一个系统(之前没想过这个问题),重要区别之一就是主动和被动,详细看这篇博客吧,说的很详细了
http://blog.csdn.net/cserchen/article/details/50422553
参考资料
//官方对相关性的解释,也就是score的计算标准
https://www.elastic.co/guide/en/elasticsearch/guide/master/relevance-intro.html
//当你的数据很少时,请用DFS Query Then Fetch搜索方法
https://www.elastic.co/blog/understanding-query-then-fetch-vs-dfs-query-then-fetch
//ES的两个搜索方法
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-request-search-type.html
//ES官方解释的BM25和TF-IDF区别
https://www.elastic.co/blog/found-similarity-in-elasticsearch
//外国友人对BM25和TF-IDF的解读
http://opensourceconnections.com/blog/2015/10/16/bm25-the-next-generation-of-lucene-relevation/
//外国友人吐槽 当score变成percentage的后果
以上是关于elasticsearch系列score的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch function_score 打分源代码跟踪
Spring Boot 整合 Elasticsearch,实现 function score query 权重分查询