pluskid'SVM系列笔记(可当做目录对照看)
Posted 易然~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pluskid'SVM系列笔记(可当做目录对照看)相关的知识,希望对你有一定的参考价值。
0.训练数据对分类器性能的影响
原文链接:http://blog.pluskid.org/?p=223
1.训练数据的不平衡性对分类器性能的影响(precision 、accuracy、error rate 等)
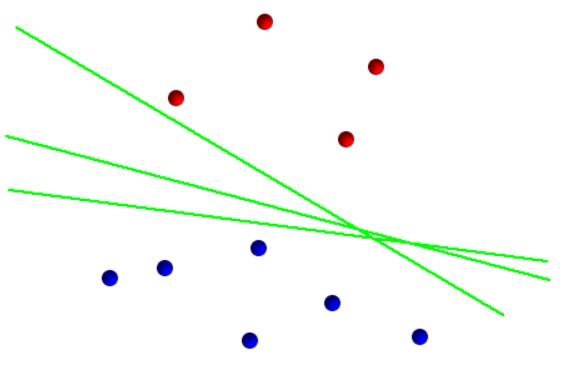
2.SVM(support vector machine)通过hyperplane切分数据,so we can have lots of reasonable hyperplane.
对于需要复杂曲线才能切分的边界:将数据映射到高维空间,这样通常都能转化成可用线性边界切分的情况,
use Kernel trick (https://en.wikipedia.org/wiki/Kernel_method)(用核函数映射到高维空间,实现线性可分)
3.We have infinite reasonable hyperplanes,but we just pick one,and SVM choose the hyperplane with the best margin.
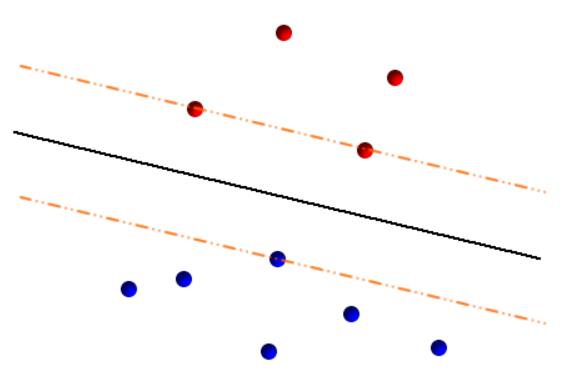
margin 就是超平面到离它最近的点的距离,图中黑线到橙色虚线的距离,SVM 在不同位置和方向的超平面之中选择了黑色的这个,因为它的 margin 最大。
4.这样做有不少好处:a. SVM 只要集中关注在边缘上的那些点,亦即图中橙色虚线上的点,(这些点被称作 Support Vector ,因为每一个 数据可被表示成一个 D 维向量的),这在数据量变得非常大的时候可以很有效地减少计算复杂度。
b.SVM 在实践中也被证明性能非常好, SVM 的归纳偏执可以看成是“margin 最大的 hyperplane 才是最好的”,实践证明,这看上去 颇有些 naive 的偏执表现很好,有优异的 generalization。
c.由于训练数据中的 70% 实际上最终是没有什么用的,可以想像,如果“运气好”的话,刚好找到那三个 Support Vector ,直接把它们拿去做训练,一点都不浪费!这个想法是非常诱人的,因为在许多领域,要收集带 label 的训练数据通常代价都比较昂贵——需要人工进行标记。
5.不平衡的训练数据通常会降低分类器的性能,影响大小不能一概而论(原文有实验图),
而解决这个问题的办法一般有两种:
a.(数据)under sample(减少sample多的那一类的训练数据,通常选孤立点等);over sample(增加sample少的那一类的训练数据,通常人工标注,复制粘贴让数据重复)
b.(算法)只要能把“我希望你不要歧视小众”这个美好愿望传达过去,结合到最终模型中,都可以算一种方法。
比如,有一种最土的办法是在训练完成之后再偷偷地把 hyperplane 往另一边挪一下。而其他看起来靠谱一点的方法却又有些复杂了(比如 moonykily 前几天给我看的这篇 Class-Boundary Alignment for Imbalanced Dataset Learning 就是在 Kernel Function/Matrix 上做手脚)
6.关于5的展开:我们已经有了一个 SVM 了,要选更多的 sample 吗?我们不是想要新加入的点都尽可能地变成 Support Vector 吗?那么 Support Vector 在哪里呢?靠近 hyperplane 的地方!bingo! 我们只要在收集到的所有 unlabeled data 中选取离 hyperplane 最近的一些点,标记一下,那么它们成为 Support Vector 的概率就很大了,并且结果很有可能比之前的 hyperplane 更好,然后我们可以用迭代的方法来选更多的点。
从 unlabeled data 中选出“重要”的 sample 来进行标记并用做下一步的训练数据.
一。
以上是关于pluskid'SVM系列笔记(可当做目录对照看)的主要内容,如果未能解决你的问题,请参考以下文章