阿里妈妈MaxCompute架构演进_-_AON(MPI)集群
Posted _夜枫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里妈妈MaxCompute架构演进_-_AON(MPI)集群相关的知识,希望对你有一定的参考价值。
摘要: 1.1 MPI集群 1.1.1 背景 我们的集群规模不断地在加大, 17财年时我们的机器规模预估1.5W台 与此同时我们却有着不同的感受,明显感觉到了各种任务的运行效率都在变低,主要问题如下 1.
阿里云数加MaxCompute (原名:ODPS;https://www.aliyun.com/product/odps)
1.1 MPI集群
1.1.1 背景
我们的集群规模不断地在加大, 17财年时我们的机器规模预估1.5W台
与此同时我们却有着不同的感受,明显感觉到了各种任务的运行效率都在变低,主要问题如下
1.1.2 问题
问题1: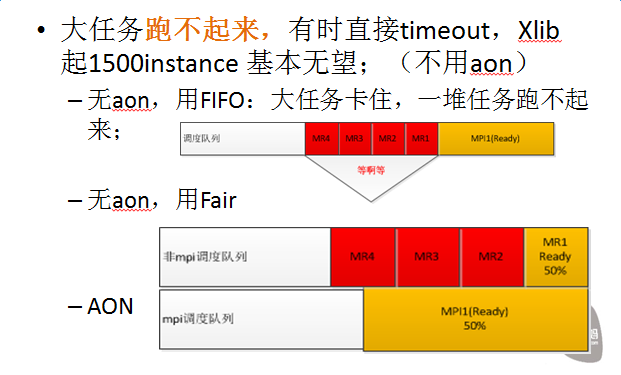
说明
Aon:all-or-nothing
FIFO/Fair:调度系统支持的两种调度策略
问题2:
问题3:

以上三个问题其实主要原因还是aon类任务跑不起来,但同时却占着大量的资源给不了别的任务用;
1.1.3 项目目标
最终的想法其实也很简单,就是拆出独立AON(但大家习惯了歪叫成MPI)集群,建设规模要达到6000台+,让且仅让所有的生产和实验aon任务(主要是PS和Xlib-mpi)跑在这个上面,尽量减少Aon任务攒资源引起的资源浪费。
1.1.4 项目收益

1.1.5 关键问题及解法
这个看似简单的结论却藏着一堆的问题要解
- 关于混合机型;
像MaxCompute这种分布式计算平台的初衷是希望对用户屏蔽掉底层的物理细节的,在MR/Sql这种单instance对资源需求量(1Core + 2~3G)不是很大的情况下是基本成立的,但在这种大的PS任务情况下,发现这个问题很不好搞,AY87B上是混布的s10(128G + 32Core)和N41(192G + 64Core),而一个大的AON任务如PS的Server和Worker单个instance动不动就需要40~50G的资源需求量,你说是设置成50G好还是60G好,用户需要兼顾底层多种机型设置的同时还要考虑任务的执行效率,这给开发同学造成了很大的困扰,因此我们做的第一个决定就是统一aon集群机型,全部使用的是s10系列。
这里面实际还有另外一个问题:用s10还是N41?,考虑到两个我们选的s10,一是LR类迭代任务每轮迭代之后的网络通信量大,在同是万M网卡的情况下我们期望单机的Instance越少越好;二是当时的情况是s10机型为主,腾挪起来方便;
这里关于机型选择的问题我觉得主要还是网络IO资源能不能纳入资源隔离的问题,如果能很好地控制网络的使用那么机型本身也就不是个多大的问题了。
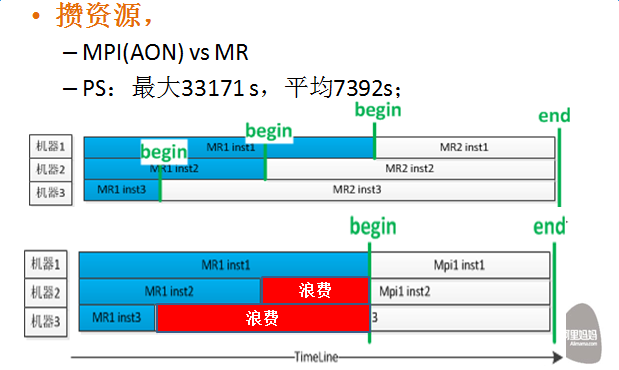
- 计算资源量储备
从单机来看,由于单个Instance的资源需求量大,很容易造成一个现象:“资源碎片”,经常出现20G以上的大“碎片”
从任务来看,独立集群的意义主要在于能让AON任务快速拿到资源,避免掉“攒”资源的过程,所以我们基本会按照需求的130%做资源准备
- 资源利用率和调度策略
由于大碎片和超额的资源配置,集群利用率肯定就不会太高,因此如何把这部分资源用起来就是一个不得不解的问题;
这个时候主要靠的就是全局调度、超卖和抢占了
【全局调度】:顾名思义就是在多个集群间做资源负载均衡的,干的事主要就是当MR集群压力大时且AON集群有空间时将部分MR任务导到AON集群;
但这种做法和以前的做法貌似差别不大,最终也会是MR和AON混跑造成相互影响,唯一好处就是能保证AON是尽量最闲的,因此我们不得不再次升级策略:抢占
【抢占】
抢占的前提是优先级,目前MaxCompute的任务优先级由project的优先级和job的优先级组成,跑在阿里妈妈AON集群上的任务有三大类:线上AON/实验AON/MR(含sql),他们的优先级通常是递减的。
抢占从粒度上分主要有两种:Quota组间的抢占和Quota内的抢占
从力度上分也有两种:温和抢占和暴力抢占
从我们要解决的问题来看,这几个策略都有涉及:
- AON集群中的Aon资源组vs mr资源组:我们的quota是基于min保障和max共享的,一般max会是min的1倍以上,当AON集群中的mr任务所在的quota组资源用得比较超(大于min)时就需要使用组间抢占让aon组尽快把资源收回来;
- AON资源组内:我们的aon任务分实验和生产,产生优先级是高于实验的,因此我们期望达到的效果是生产要跑时实验能把资源释放出来给生产用,因此组内也需要开抢占;
- 暴力抢占:当aon需要抢占mr时,由于mr有自动的failover,因此可以直接把资源抢过来;
- 温和抢占:从人性化和高效率的角度,这个才是正道,他的主要思想就是基于一个抢占协议和抢占消息,让任务的instance能够感知在X秒内将被强制终止,它可以根据自身情况选择跑完还是保存现场或者立即终止,这个事的难点是让mr/ps/xlib等计算框架都支持和能处理这些协议和消息。
这一整套要实施下来周期较长,在实施的过程中,我们发现了另外一个更有用的方案:超卖;
【超卖】
抢占有一个不太好的地方就是基于plan资源的,而物理上机器的实际利用率可能不一定高,且由于需要单独划Quota也会挤占fuxi给AON任务的plan资源,因此最终我们决定用超卖的方式来斛利用率这个问题。
超卖的基本思想:超卖的quota其min是一个很小值,不占用集群的plan额度,直接给集群设定一个超卖率(如20%),当某台机器的负载超过一定阈值的时候就将超卖的任务直接杀掉;
当然超卖也是可以和全局调度结合起来用,其实我觉得全局调度+超卖+温和抢占如果能全部支持的话这个场景下的调度策略的问题能解得基本差不多。
1.1.6 一点感想
建设aon集群实际就是在做物理资源的隔离,实际的建设进度不是很快,主要还是还重了(尤其是存储迁移最费事),我们也在想如果存储计算分离做得足够好后,较为轻便的虚拟集群是不是会更高效点,当然需要把相关的自动化配套建设起来才行,否则一大堆人肉工作也是很难受的。
最后感慨一下:系统调度是一个很难十分十美的跨学科工种;
以上是关于阿里妈妈MaxCompute架构演进_-_AON(MPI)集群的主要内容,如果未能解决你的问题,请参考以下文章