hive增量抽取方案
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive增量抽取方案相关的知识,希望对你有一定的参考价值。
参考技术A 简单说,sqoop支持两种增量mysql导入到hive的模式,一种是 append,即通过指定一个递增的列,比如:
--incremental append --check-column id --last-value 0
导入id>0的数
另一种是可以根据时间戳的模式叫 lastmodified ,比如:
--incremental lastmodified --check-column createTime --last-value '2012-02-01 11:0:00'
就是只导入createTime 比'2012-02-01 11:0:00'更大的数据。
oozie4.3.0+sqoop1.4.6实现mysql到hive的增量抽取
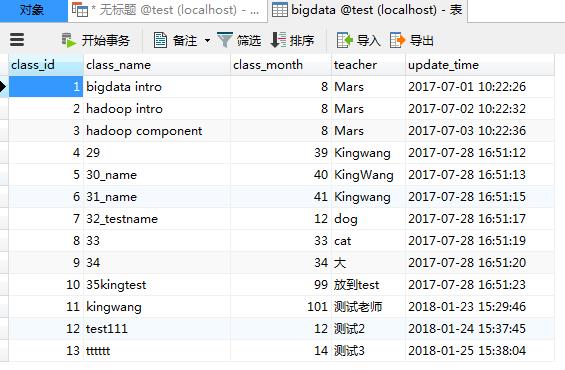
1.准备数据源
mysql中表bigdata,数据如下:
2. 准备目标表
目标表存放hive中数据库dw_stg表bigdata
保存路径为 hdfs://localhost:9000/user/hive/warehouse/dw_stg.db/bigdata
hive中建表语句如下:
create external table bigdata( class_id string comment \'课程id\', class_name string comment \'课程名称\', class_month int comment \'课程周期\', teacher string comment \'课程老师\', update_time string comment \'更新日期\' ) partitioned by(dt string comment \'年月日\') row format delimited fields terminated by \'\\001\' lines terminated by \'\\n\' stored as textfile;
注意点: 字段分隔符使用\\001,行分隔符使用\\n ,增加表分区dt格式为yyyMMdd
在hive中创建上面表bigdata.
3. 编写oozie脚本文件
3.1 配置job.properties
# 公共变量 timezone=Asia/Shanghai jobTracker=dwtest-name1:8032 nameNode=hdfs://dwtest-name1:9000 queueName=default warehouse=/user/hive/warehouse dw_stg=${warehouse}/dw_stg.db dw_mdl=${warehouse}/dw_mdl.db dw_dm=${warehouse}/dw_dm.db app_home=/user/oozie/app oozie.use.system.libpath=true # coordinator oozie.coord.application.path=${nameNode}${app_home}/bigdata/coordinator.xml workflow=${nameNode}${app_home}/bigdata # source connection=jdbc:mysql://192.168.1.100:3306/test username=test password=test source_table=bigdata # target target_path=${dw_stg}/bigdata # 脚本启动时间,结束时间 start=2018-01-24T10:00+0800 end=2199-01-01T01:00+0800
3.2 配置coordinator.xml
<coordinator-app name="coord_bigdata" frequency="${coord:days(1)}" start="${start}" end="${end}" timezone="${timezone}" xmlns="uri:oozie:coordinator:0.5"> <action> <workflow> <app-path>${workflow}</app-path> <configuration> <property> <name>startTime</name> <value>${coord:formatTime(coord:dateOffset(coord:nominalTime(), -1, \'DAY\'), \'yyyy-MM-dd 00:00:00\')}</value> </property> <property> <name>endTime</name> <value>${coord:formatTime(coord:dateOffset(coord:nominalTime(), 0, \'DAY\'), \'yyyy-MM-dd 00:00:00\')}</value> </property> <property> <name>outputPath</name> <value>${target_path}/dt=${coord:formatTime(coord:dateOffset(coord:nominalTime(), 0, \'DAY\'), \'yyyyMMdd\')}/</value> </property> </configuration> </workflow> </action> </coordinator-app>
注意点:
增量的开始时间startTime获取: 当前时间的前一天 输出值为 2018-01-23 00:00:00
${coord:formatTime(coord:dateOffset(coord:nominalTime(), -1, \'DAY\'), \'yyyy-MM-dd 00:00:00\')}
增量的结束时间endTime获取: 输出值为 2018-01-24 00:00:00
${coord:formatTime(coord:dateOffset(coord:nominalTime(), 0, \'DAY\'), \'yyyy-MM-dd 00:00:00\')}
输出路径需要带上分区字段dt: 输出值 /user/hive/warehouse/dw_stg.db/bigdata/dt=20180124/
${target_path}/dt=${coord:formatTime(coord:dateOffset(coord:nominalTime(), 0, \'DAY\'), \'yyyyMMdd\')}/
3.3 配置workflow.xml
1 <?xml version="1.0" encoding="UTF-8"?> 2 <!-- 3 Licensed to the Apache Software Foundation (ASF) under one 4 or more contributor license agreements. See the NOTICE file 5 distributed with this work for additional information 6 regarding copyright ownership. The ASF licenses this file 7 to you under the Apache License, Version 2.0 (the 8 "License"); you may not use this file except in compliance 9 with the License. You may obtain a copy of the License at 10 11 http://www.apache.org/licenses/LICENSE-2.0 12 13 Unless required by applicable law or agreed to in writing, software 14 distributed under the License is distributed on an "AS IS" BASIS, 15 WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 16 See the License for the specific language governing permissions and 17 limitations under the License. 18 --> 19 <workflow-app xmlns="uri:oozie:workflow:0.4" name="wf_bigdata"> 20 <start to="sqoop-node"/> 21 22 <action name="sqoop-node"> 23 <sqoop xmlns="uri:oozie:sqoop-action:0.2"> 24 <job-tracker>${jobTracker}</job-tracker> 25 <name-node>${nameNode}</name-node> 26 <prepare> 27 <delete path="${nameNode}${outputPath}"/> 28 </prepare> 29 <configuration> 30 <property> 31 <name>mapred.job.queue.name</name> 32 <value>${queueName}</value> 33 </property> 34 </configuration> 35 <arg>import</arg> 36 <arg>--connect</arg> 37 <arg>${connection}</arg> 38 <arg>--username</arg> 39 <arg>${username}</arg> 40 <arg>--password</arg> 41 <arg>${password}</arg> 42 <arg>--verbose</arg> 43 <arg>--query</arg> 44 <arg>select class_id,class_name,class_month,teacher,update_time from ${source_table} where $CONDITIONS and update_time >= \'${startTime}\' and update_time < \'${endTime}\'</arg> 45 <arg>--fields-terminated-by</arg> 46 <arg>\\001</arg> 47 <arg>--target-dir</arg> 48 <arg>${outputPath}</arg> 49 <arg>-m</arg> 50 <arg>1</arg> 51 </sqoop> 52 <ok to="end"/> 53 <error to="fail"/> 54 </action> 55 56 <kill name="fail"> 57 <message>Sqoop free form failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message> 58 </kill> 59 <end name="end"/> 60 </workflow-app>
4. 上传脚本
将以上3个文件上传到hdfs的oozie目录app下如下:

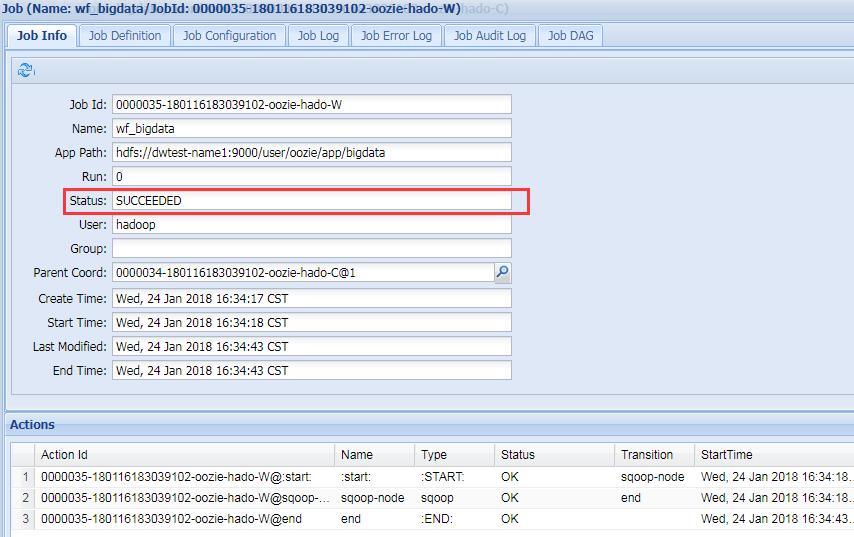
5. 执行job
oozie job -config job.properties -run

6. 查看job状态
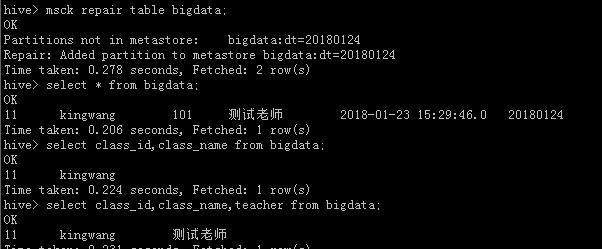
7. 查询hive中表
使用 msck repair table bigdata 自动修复分区,然后查询结果,测试没用问题。
8. 开发中遇到的坑如下:
8.1 workflow.xml中字段分隔符不能带单引号。正确的是<arg>\\001</arg> ,错误的是<arg>\'\\001\'</arg>
8.2 由于sqoop的脚本配置在xml中,所以在判断条件时使用小于号"<"会报错,xml文件校验不通过。
解决方法使用 < 代替 "<" ,所以使用大于号时最好也使用 >代替 ">"
以上是关于hive增量抽取方案的主要内容,如果未能解决你的问题,请参考以下文章
SQOOP增量抽取时,在HIVE中实现类似Oracle的merge操作
在idea上链接hive 并将mysql上的数据抽取到hive表中
HADOOP MapReduce 处理 Spark 抽取的 Hive 数据解决方案一