论文笔记 Spatial contrasting for deep unsupervised learning
Posted everyday_haoguo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记 Spatial contrasting for deep unsupervised learning相关的知识,希望对你有一定的参考价值。
在我们设计无监督学习模型时,应尽量做到
- 网络结构与有监督模型兼容
- 有效利用有监督模型的基本模块,如dropout、relu等
无监督学习的目标是为有监督模型提供初始化的参数,理想情况是“这些初始化的参数能够极大提高后续有监督模型准确率,即使有监督任务的训练样本数很少”。类别理解就是,我们在Imagenet上通过有监督的方式训练得到了表达能力很强的网络,在我们迁移至新的任务时(该任务带有训练标签的样本有限),我们一般固定在Imagenet上训练好模型的前N层(N可以根据实际需要调整),然后微调剩余的层。无监督学习的目的,简单理解就是“即使不用label,我也能学到表达能力很强,甚至更好的网络”,然后我们可以根据具体任务微调网络。
作者在文中指出“It is empirically observed that deeper layers tend to contain more abstract information from the image. Intuitively, features describing different regions within the same image are likely to be semantically similar and indeed the corresponding deep representations tend to be similar. Conversely, regions from two probably unrelated images tend to be far from each other in the deep representations”。
简单理解就是“一幅图像内一个区域的deep representations应该尽可能与另一个区域的deep representations相似,与不相关图像区域的deep representations尽可能相异”。
下图图示了以上含义(请仔细理解一下loss函数的语义,是不是就是上述的“简单理解”呢?):
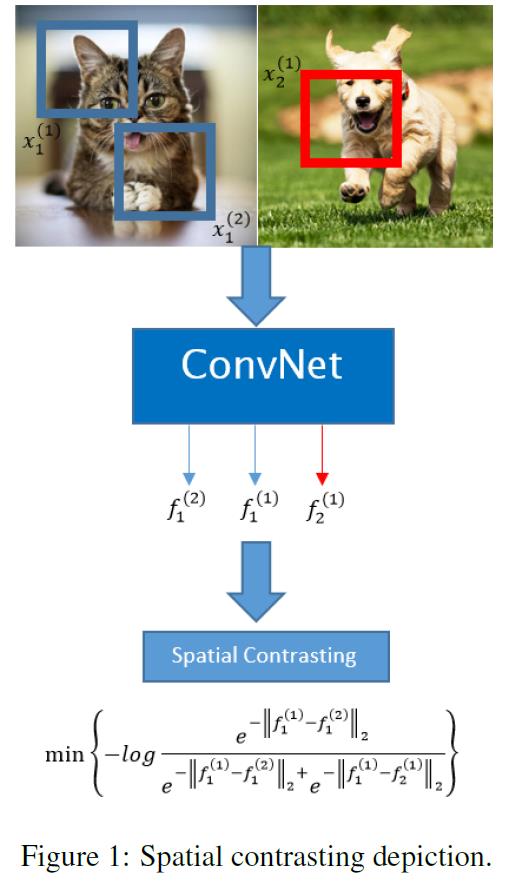
为了能够应用有监督深度学习标准训练流程(SGD, Batch),作者对上图目标函数进行了一些处理。核心就是Batch内每一幅图片取两个区域,所有这些区域两两进行对比,得到:
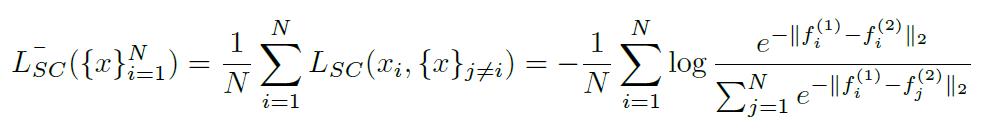
这样就能够采取标准的有监督深度学习训练流程进行训练了。此外有监督深度学习的任何模块,该框架都可以无缝的引入。
我们可以通过下面这个流程图更加对流程有一个更加“程序化”认识(也即,可以用代码实现上述流程)

总结:这种做法可以概括为“基于patch的无监督范式”,这篇文章的思路很简单,也给了我很大启发(也即,将需要在整个数据集上进行的两两对比简化到Batch内的两两对比)。论文中的实验结果很好(但github上有一位网友,难以复现论文的结果)。
以上是关于论文笔记 Spatial contrasting for deep unsupervised learning的主要内容,如果未能解决你的问题,请参考以下文章