刨根究底字符编码之十二——UTF-8究竟是怎么编码的
Posted 刨根究底学编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了刨根究底字符编码之十二——UTF-8究竟是怎么编码的相关的知识,希望对你有一定的参考价值。

UTF-8究竟是怎么编码的
1.
UTF-8编码是Unicode字符集的一种编码方式(CEF),其特点是使用变长字节数(即变长码元序列、变宽码元序列)来编码。一般是1到4个字节,当然,也可以更长。
为什么要变长呢?这可以理解为按需分配,比如一个字节足以容纳所有的ASCII字符,那何必补一堆0用更多的字节来存储呢?
实际上变长编码有其优势也有其劣势,优势是节省空间、自动纠错性能好、利于传输、扩展性强,劣势是不利于程序内部处理,比如正则表达式检索;而UTF-32这样等长码元序列(即等宽码元序列)的编码方式就比较适合程序处理,当然,缺点是比较耗费存储空间。
2.
那UTF-8究竟是怎么编码的呢?也就是说其编码算法是什么?
UTF-8编码最短的为一个字节、最长的目前为四个字节,从首字节就可以判断一个UTF-8编码有几个字节:
- 如果首字节以0开头,肯定是单字节编码(即单个单字节码元);
- 如果首字节以110开头,肯定是双字节编码(即由两个单字节码元所组成的双码元序列);
- 如果首字节以1110开头,肯定是三字节编码(即由三个单字节码元所组成的三码元序列),以此类推。
另外,UTF-8编码中,除了单字节编码外,由多个单字节码元所组成的多字节编码其首字节以外的后续字节均以10开头(以区别于单字节编码以及多字节编码的首字节)。
0、110、1110以及10相当于UTF-8编码中各个字节的前缀,因此称之为前缀码。其中,前缀码110、1110及10中的0,是前缀码中的终结标志。
UTF-8编码中的前缀码起到了很好的区分和标识的作用——当解码程序读取到一个字节的首位为0,表示这是一个单字节编码的ASCII字符;当读取到一个字节的首位为1,表示这是一个非ASCII字符的多字节编码字符中的某个字节(可能是首字节,也可能是后续字节),接下来若继续读取到一个1,则确定为首字节,再继续读取直到遇见终结标志0为止,读取了几个1,就表示该字符为几个字节的编码;当读取到一个字节的首位为1,紧接着读取到一个终结标志0,则该字节显然是非ASCII字符的后续字节(即非首字节)。
(笨笨阿林原创文章,转载请注明出处)
3.
所以,1~4字节的UTF-8编码看起来分别是这样的:
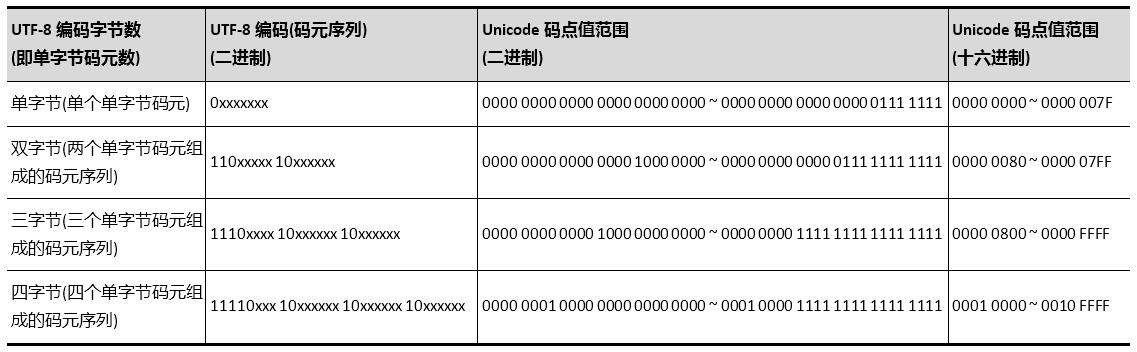
单字节可编码的Unicode码点值范围十六进制为0x0000 ~ 0x007F,十进制为0 ~ 127;
双字节可编码的Unicode码点值范围十六进制为0x0080 ~ 0x07FF,十进制为128 ~ 2047;
三字节可编码的Unicode码点值范围十六进制为0x0800 ~ 0xFFFF,十进制为2048 ~ 65535;
四字节可编码的Unicode码点值范围十六进制为0x10000 ~ 0x1FFFFF,十进制为65536 ~ 2097151(目前Unicode字符集码点编号的最大值为0x10FFFF,实际尚未编号到0x1FFFFF;这说明作为变长字节数的UTF-8编码其未来扩展性非常强,即便目前的四字节编码也还有大量编码空间未被使用,更不论还可扩展为五字节、六字节……)。
(笨笨阿林原创文章,转载请注明出处)
4.
上述Unicode码点值范围中十进制值127、2047、65535、2097151这几个临界值是怎么来的呢?
因为UTF-8编码中的每个字节中都含有起到区分和标识之用的前缀码0、110、1110以及10之一,所以1~4个字节的UTF-8编码其实际有效位数分别为8-1=7位(2^7-1=127)、16-5=11位(2^11-1=2047)、24-8=16位(2^16-1=65535)、32-11=21位(2^21-1=2097151),如下表所示:
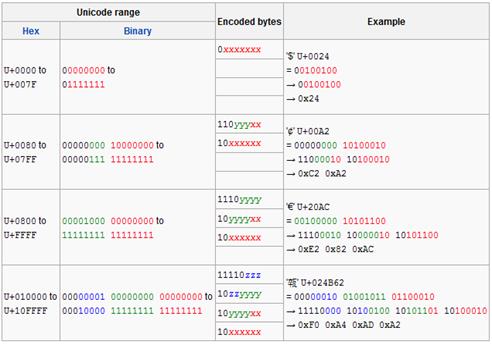
注:上图中的Unicode range即Unicode码点值范围(也就是Unicode码点编号范围),Hex为16进制,Binary为二进制;Encoded bytes即UTF-8编码中各字节的编码方式(即编码算法),其中,x代表Unicode二进制码点值的单字节或低字节中的低7位或8位、y代表两字节码点值的高字节中的低3位或8位以及三字节码点值的中字节中的8位、z代表三字节码点值的高字节中的低5位。
因此,UTF-8编码的算法简单地用一句话来概括就是:首先确定UTF-8编码中各个字节的前缀码;之后再将UTF-8编码中各个字节除了前缀码所占用之外的位,依次分配给Unicode字符码点值二进制中各个位的值,换言之,就是用Unicode字符码点值二进制中各个位的值,依次填充UTF-8编码中的各个字节除了前缀码所占用之外的位。
5.
由于ASCII字符的UTF-8编码使用单字节,而且和ASCII编码一模一样,这样所有原先使用ASCII编码的文档就可以直接解码了,无需进行任何转换,实现了完全兼容。考虑到计算机世界中英文文档的数量之多,这一点意义重大。
而对于其他非ASCII字符,则使用2~4个字节的编码来表示。其中,首字节中前置的1的个数代表该字符编码的字节数(110代表两个字节、1110代表三个字节,以此类推),非首字节之外的剩余字节的高2位始终是10,这样就不会与ASCII字符编码以及非ASCII字符的首字节编码相冲突。
例如,假设某个字符的首字节是1110yyyy,前置有三个1,说明该字符编码总共有三个字节,必须和后面两个以10开头的字节结合才能正确解码该字符。
6.
由此可知,UTF-8编码设计得非常精巧,虽说不上完美无缺,但若与后文将要介绍的UTF-16、UTF-32以及前文介绍过的那些ANSI编码相比较,对于其精巧设计将体会得更为深切透彻。因此,UTF-8越来越得到全球一致认可,大有一统字符编码之势。
(笨笨阿林原创文章,转载请注明出处)
(未完待续)
本系列文章上一篇为:刨根究底字符编码之十一——UTF-8编码方式与字节序标记
【预告:本系列文章下一篇将重点介绍UTF-16编码,敬请关注!】
以上是关于刨根究底字符编码之十二——UTF-8究竟是怎么编码的的主要内容,如果未能解决你的问题,请参考以下文章
刨根究底字符编码之十四——UTF-16究竟是怎么编码的(“代理区(Surrogate Zone)”,范围为0xD800~0xDFFF(十进制55296~57343),共2048个码点未定义。UTF8和
刨根究底字符编码之十六——Windows记事本的诡异怪事:微软为什么跟联通有仇?(没有BOM,所以被误判为UTF8。“联通”两个汉字的GB内码,其第一第二个字节的起始部分分别是“110”和“10”,,