1.4.7 HPA 横向自动扩容 4.8 statefulset
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了1.4.7 HPA 横向自动扩容 4.8 statefulset相关的知识,希望对你有一定的参考价值。
参考技术A HPA实现原理: 通过分析追踪指定RC控制的所有目标POD的负载变化情况,来确定是否需要针对性地调整目标POD的副本数量
HPA度量指标: 1: CPU 2: 应用程序自定义的度量指标 比如服务在每秒内的相应请求数,如TPS QPS
CPU利用率 Pod Request/ pod 使用量
如果没有定义Pod Request的值,则无法实现Pod 横向自动扩容
kubernetes 从1.2开始也在尝试支持应用程序自定义的度量指标
------------------------------------------------------------------------------------------------------------
CPU使用量通常是1MIN内的平均值
从1.7版本开始,kubernetes自身孵化了一个基础性能数据采集监控框架:
kubernetes Monitoring Architecture
HMA
kubernetes自定义了一套标准化的API接口, Resource Metrics API
客户端应用程序(HPA)
------------------------------------------------------------------------
下面是HPA定义的一个具体例子:
超过90% 会自动扩容,约束条件是Pod的副本数为1-10
也可以通过简单命令行直接创建等价的HPA对象:
POD的管理对象 RC Deployment DaemonSet Job都面向无状态的服务
复杂的中间件集群: 如mysql mongodb akka zookeeper集群都是有状态的
-----------------------------------------------------------------------------------
StatefulSet 可以看作是RC/Deployment 的一个特殊变种
RC/Deployment无法满足
1: 固定id 相互通信
2: 集群规模固定,不能随意变动
3: 每个节点都是有状态的,通常持久化数据到永久存储中
4: 磁盘顺坏则无法正常运行,集群功能受损
----------------------------------------------------------------
statefulSet有如下特性:
1: 稳定,唯一的网络标识
用来发现集群内其他成员 如第一个: kafka-0 第二个: kafka-1
2: statefulSet控制的POD启动顺序是受控的,操作n个POD,前面n-1是运行且准备好的状态
3: Pod采用稳定的持久化存储卷
通过PV或PVC来实现
删除POD时不会删除存储卷
-------------------------------------------------------------------------------------
StatefulSet 与PV 绑定以存储POD的状态数据
还要与Headless Service 配合使用
在每个StatefulSet中声明它属于哪个headless Service
HEADless Service 与 普通 Service的区别:
它没有Cluster IP 如果解析Headless Service的域名返回的是Service对应的全部POD的Endpoint列表
StateFulSet在HEadless Service的基础上又为StatefulSet 控制的每个POD 实例都创建了一个DNS域名,域名为 $(podname).$(headless service name)
如: kafka-1.kafka kafka-0.kafka
Docker Swarm 横向扩容/收缩简单使用
Swarm 是 Docker 官方提供的一款集群管理工具,其主要作用是把若干台 Docker 主机抽象为一个整体,并且通过一个入口统一管理这些 Docker 主机上的各种 Docker 资源。 Swarm 和 Kubernetes 比较类似,但是更加轻,具有的功能也较 kubernetes 更少一些。
Swarm 横向扩容准备服务器:
swarm1(master):192.168.75.191
swarm2(node1):192.168.75.192
swarm3(node2):192.168.75.193
注:docker 1.12 版本后都自带 swarm 命令,无需安装
一、启动集群
在 swarm1 上启动集群,即 swarm1 为 master 节点:
[root@swarm1 ~]# docker swarm init --listen-addr 192.168.75.191:1234
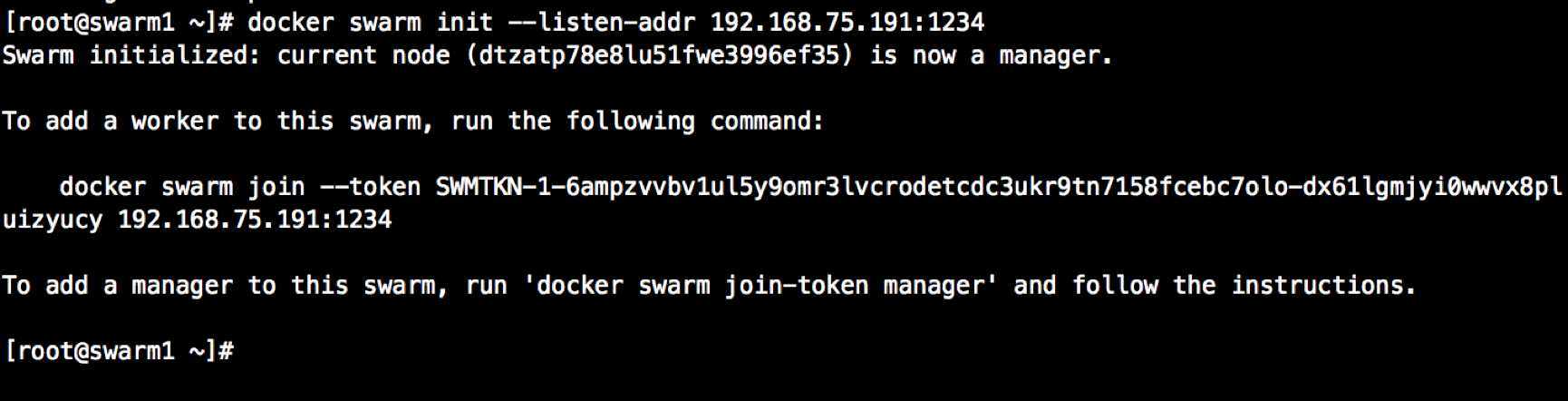
# --listen-addr 集群暴漏给外界调用的 HTTPAPI 的 socket 地址, IP 为本机 ip ,端口可自定义
上述命令运行成功会生成如下信息,此命令用于节点(被管理主机)加入集群
docker swarm join
--token SWMTKN-1-6ampzvvbv1ul5y9omr3lvcrodetcdc3ukr9tn7158fcebc7olo-dx61lgmjyi0wwvx8pluizyucy
192.168.75.191:1234
在 swarm1 上查看各节点信息:
[root@swarm1 ~]# docker node ls #目前只有本机(管理主机 swarm1 )加入集群

二、分别将 swarm2 & swarm3 节点(被管理节点)加入集群

swarm1 (管理主机)再次查看节点信息,如下所示则集群添加成功

Swarm 集群以搭建完毕接下来进行横向扩容/收缩
三、测试:拉取tomcat镜像,横向扩容
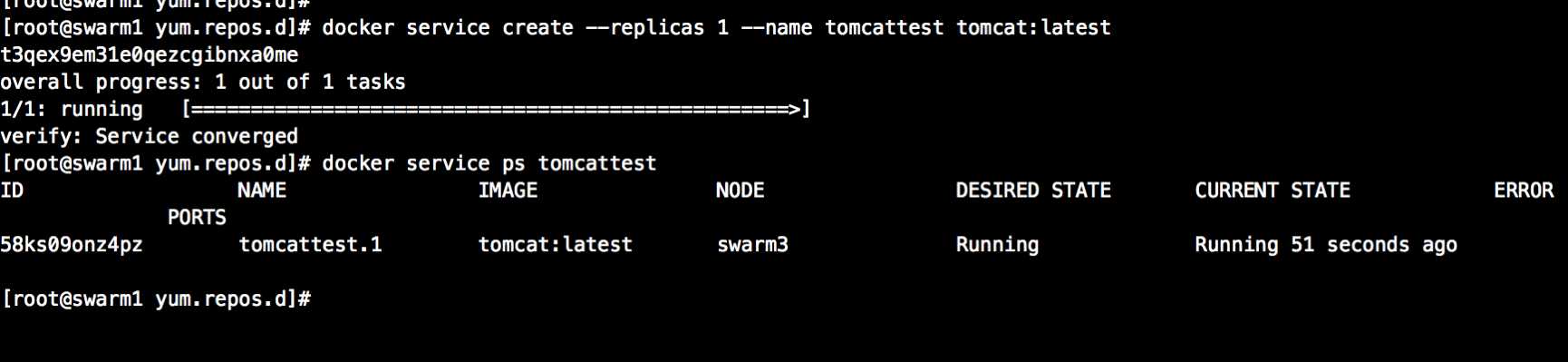
1、创建实例
[swarm1 ~]# docker service create --replicas 1 --name tomcattest tomcat:latest
# --replicas 始终运行实例数目
# --name 运行服务名称,非容器名称
[root@swarm1 ~]# docker service ps tomcattest #查看实例运行状态
2、横向扩容/收缩
[root@swarm1 ~]# docker service scale tomcattest=3
#tomcattest服务增加为3个实例
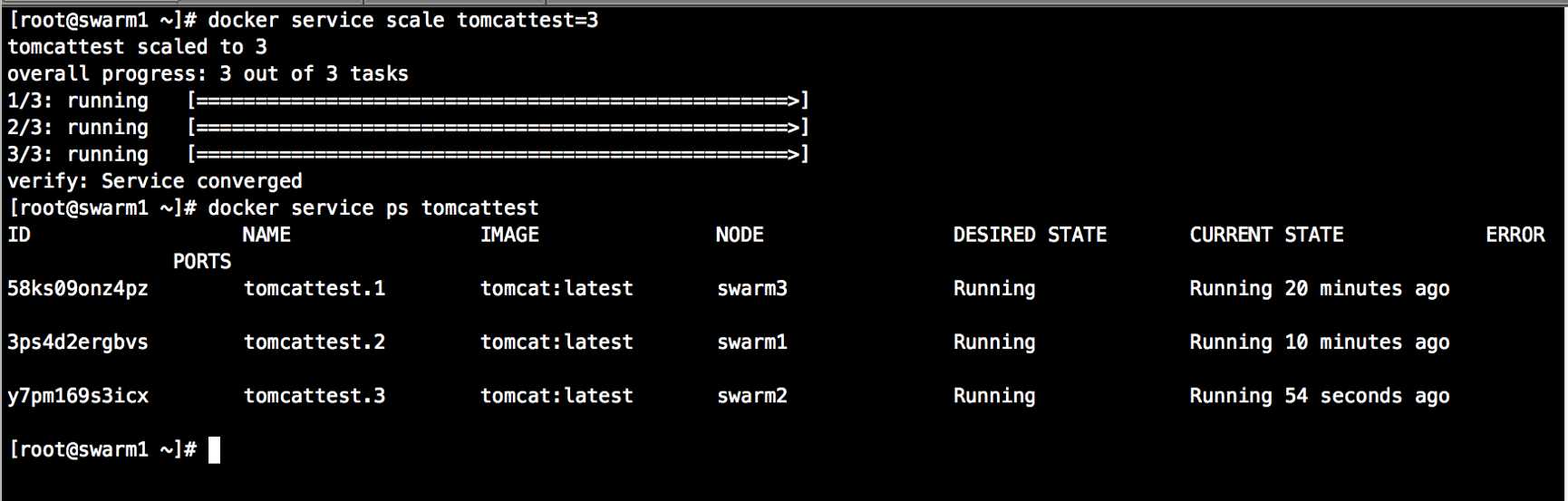
#实例自动在3台节点上分配,保证运行数量为3个实例,并且当某节点出现异常状态导致该节点上的服务宕机,
将会在其余节点自动运行实例。始终保持实例数量为需求数量。
3、停止 swarm3 节点,查看实例状态
[root@swarm3 ~]# systemctl stop docker
在 swarm1 上查看服务运行状态:
[root@swarm1 ~]# docker service ps tomcattest

#swarm3节点服务自动转移至swarm1服务器上,实例数仍为3.
swarm3 上 tomcat 实例为宕机状态,且在 swarm1 上新生成实例,使 tomcat 实例总数仍为3
至此 Swarm 集群搭建以及简单都横向扩容及收缩都已经完成了。
后话:
Swarm 虽为 Docker 官方提供的管理工具,但因 swarm 本身功能的不完善性,以及与其他插件的耦合度较低,所以现在基本都不建议使用 swarm 作为管理工具,现在较为流行的管理工具为 k8s ,这里就不多说了,大家有兴趣就自行百度查看吧,另 Rancher 是目前比较新兴的管理工具,使用 Rancher 可以来管理 k8s 集群。。。
以上是关于1.4.7 HPA 横向自动扩容 4.8 statefulset的主要内容,如果未能解决你的问题,请参考以下文章