GPU编程--Shared Memory
Posted everyday_haoguo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GPU编程--Shared Memory相关的知识,希望对你有一定的参考价值。
GPU的内存按照所属对象大致分为三类:线程独有的、block共享的、全局共享的。细分的话,包含global, local, shared, constant, and texture memoey, 我们重点关注以下两类内存
- Global memory
Global memory resides in device memory and device memory is accessed via 32-, 64-, or 128-bytes memory transactions
- Shared memory
Because it is on-chip, shared memory has much higher bandwidth and much lower latency than local or global memory
简单理解就是,Shared memory更快。以下是内存按照所属对象分类示意图
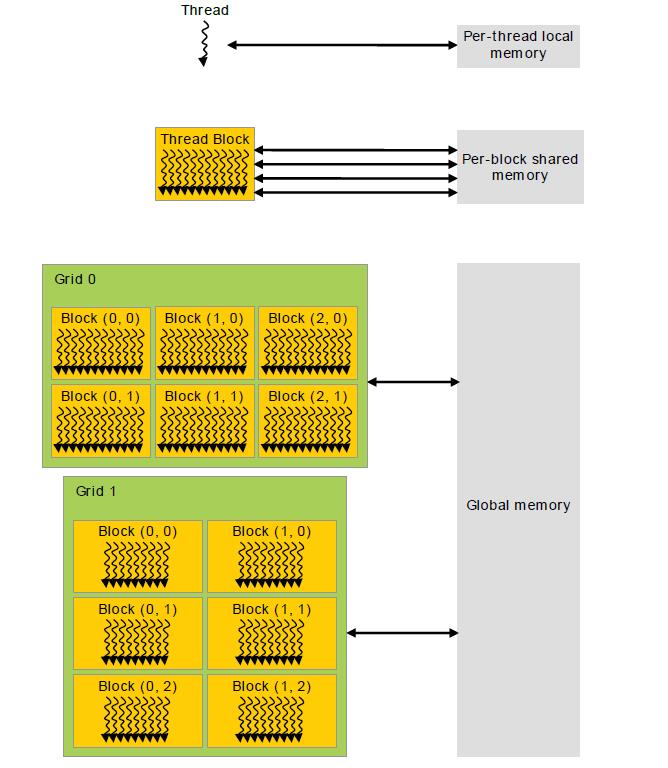
有了对Global memory、Shared memory的印象之后,我们通过矩阵相乘的例子要谈谈这两种内存的运用,并对比他们的优劣(老规矩,先代码,后解释)
// Matrices are stored in row-major order: // M(row, col) = *(M.elements + row * M.width + col) typedef struct { int width; int height; float* elements; } Matrix; // Thread block size #define BLOCK_SIZE 16 // Forward declaration of the matrix multiplication kernel __global__ void MatMulKernel(const Matrix, const Matrix, Matrix); // Matrix multiplication - Host code // Matrix dimensions are assumed to be multiples of BLOCK_SIZE void MatMul(const Matrix A, const Matrix B, Matrix C) { // Load A and B to device memory Matrix d_A; d_A.width = A.width; d_A.height = A.height; size_t size = A.width * A.height * sizeof(float); cudaMalloc(&d_A.elements, size); cudaMemcpy(d_A.elements, A.elements, size, cudaMemcpyHostToDevice); Matrix d_B; d_B.width = B.width; d_B.height = B.height; size = B.width * B.height * sizeof(float); cudaMalloc(&d_B.elements, size); cudaMemcpy(d_B.elements, B.elements, size, cudaMemcpyHostToDevice); // Allocate C in device memory Matrix d_C; d_C.width = C.width; d_C.height = C.height; size = C.width * C.height * sizeof(float); cudaMalloc(&d_C.elements, size); // Invoke kernel dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE); dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y); MatMulKernel<<<dimGrid, dimBlock>>>(d_A, d_B, d_C); // Read C from device memory cudaMemcpy(C.elements, Cd.elements, size, cudaMemcpyDeviceToHost); // Free device memory cudaFree(d_A.elements); cudaFree(d_B.elements); cudaFree(d_C.elements); } // Matrix multiplication kernel called by MatMul() __global__ void MatMulKernel(Matrix A, Matrix B, Matrix C) { // Each thread computes one element of C // by accumulating results into Cvalue float Cvalue = 0; int row = blockIdx.y * blockDim.y + threadIdx.y; int col = blockIdx.x * blockDim.x + threadIdx.x; for (int e = 0; e < A.width; ++e) Cvalue += A.elements[row * A.width + e] * B.elements[e * B.width + col]; C.elements[row * C.width + col] = Cvalue;
}
计算原理如下
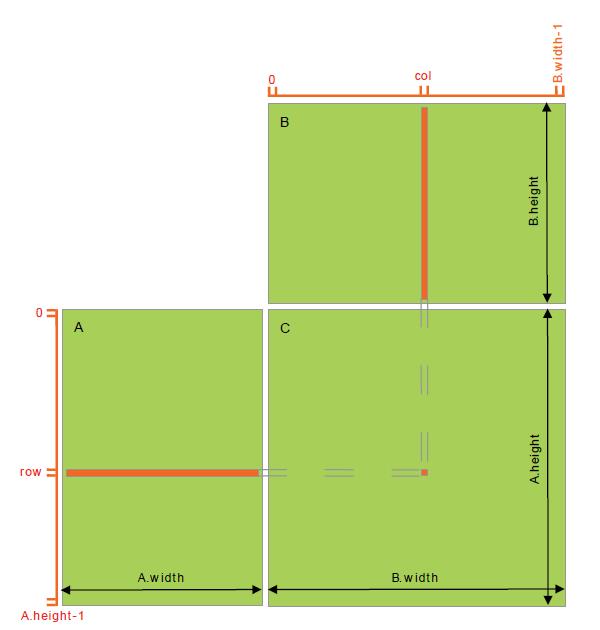
host端代码很常规,我们重点关注__global__标记的这个device端代码,她完成的功能很简单就是去A矩阵的一行、B矩阵的一列。行列对应元素相乘累加,也就是向量的点击运算。当运算结束的时候矩阵C=AB。这是很常规的一种思路。
那么,如何用Shared memory完成上述功能呢?这样的好处又是什么呢?(老规矩,先代码,后解释)
// Matrices are stored in row-major order: // M(row, col) = *(M.elements + row * M.stride + col) typedef struct { int width; int height; int stride; float* elements; } Matrix; // Get a matrix element __device__ float GetElement(const Matrix A, int row, int col) { return A.elements[row * A.stride + col]; } // Set a matrix element __device__ void SetElement(Matrix A, int row, int col, float value) { A.elements[row * A.stride + col] = value; } // Get the BLOCK_SIZExBLOCK_SIZE sub-matrix Asub of A that is // located col sub-matrices to the right and row sub-matrices down // from the upper-left corner of A __device__ Matrix GetSubMatrix(Matrix A, int row, int col) { Matrix Asub; Asub.width = BLOCK_SIZE; Asub.height = BLOCK_SIZE; Asub.stride = A.stride; Asub.elements = &A.elements[A.stride * BLOCK_SIZE * row + BLOCK_SIZE * col]; return Asub; } // Thread block size #define BLOCK_SIZE 16 // Forward declaration of the matrix multiplication kernel __global__ void MatMulKernel(const Matrix, const Matrix, Matrix); // Matrix multiplication - Host code // Matrix dimensions are assumed to be multiples of BLOCK_SIZE void MatMul(const Matrix A, const Matrix B, Matrix C) { // Load A and B to device memory Matrix d_A; d_A.width = d_A.stride = A.width; d_A.height = A.height; size_t size = A.width * A.height * sizeof(float); cudaMalloc(&d_A.elements, size); cudaMemcpy(d_A.elements, A.elements, size, cudaMemcpyHostToDevice); Matrix d_B; d_B.width = d_B.stride = B.width; d_B.height = B.height; size = B.width * B.height * sizeof(float); cudaMalloc(&d_B.elements, size); cudaMemcpy(d_B.elements, B.elements, size, cudaMemcpyHostToDevice); // Allocate C in device memory Matrix d_C; d_C.width = d_C.stride = C.width; d_C.height = C.height; size = C.width * C.height * sizeof(float); cudaMalloc(&d_C.elements, size); // Invoke kernel dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE); dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y); MatMulKernel<<<dimGrid, dimBlock>>>(d_A, d_B, d_C); // Read C from device memory cudaMemcpy(C.elements, d_C.elements, size, cudaMemcpyDeviceToHost); // Free device memory cudaFree(d_A.elements); cudaFree(d_B.elements); cudaFree(d_C.elements); } // Matrix multiplication kernel called by MatMul() __global__ void MatMulKernel(Matrix A, Matrix B, Matrix C) { // Block row and column int blockRow = blockIdx.y; int blockCol = blockIdx.x; // Each thread block computes one sub-matrix Csub of C Matrix Csub = GetSubMatrix(C, blockRow, blockCol); // Each thread computes one element of Csub // by accumulating results into Cvalue float Cvalue = 0; // Thread row and column within Csub int row = threadIdx.y; int col = threadIdx.x; // Loop over all the sub-matrices of A and B that are // required to compute Csub // Multiply each pair of sub-matrices together // and accumulate the results for (int m = 0; m < (A.width / BLOCK_SIZE); ++m) { // Get sub-matrix Asub of A Matrix Asub = GetSubMatrix(A, blockRow, m); // Get sub-matrix Bsub of B Matrix Bsub = GetSubMatrix(B, m, blockCol); // Shared memory used to store Asub and Bsub respectively __shared__ float As[BLOCK_SIZE][BLOCK_SIZE]; __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE]; // Load Asub and Bsub from device memory to shared memory // Each thread loads one element of each sub-matrix As[row][col] = GetElement(Asub, row, col); Bs[row][col] = GetElement(Bsub, row, col); // Synchronize to make sure the sub-matrices are loaded // before starting the computation __syncthreads(); // Multiply Asub and Bsub together for (int e = 0; e < BLOCK_SIZE; ++e) Cvalue += As[row][e] * Bs[e][col]; // Synchronize to make sure that the preceding // computation is done before loading two new // sub-matrices of A and B in the next iteration __syncthreads(); } // Write Csub to device memory // Each thread writes one element SetElement(Csub, row, col, Cvalue);
}
计算原理如下
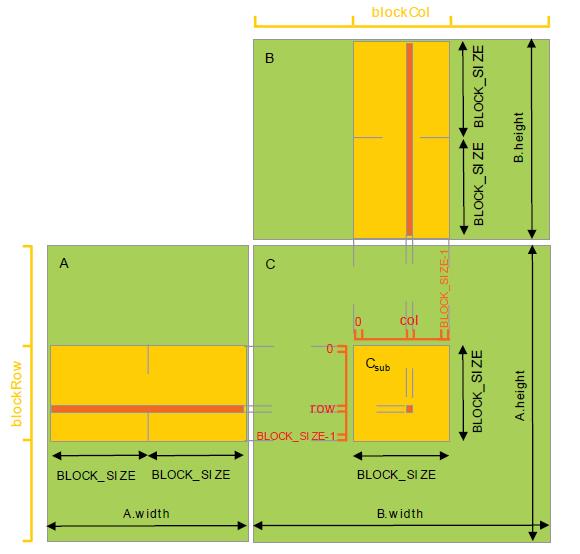
__device__标记的函数只能由__device__、__global__标记的函数调用。GetElement函数就是得到矩阵A(row,col)这一坐标上的值,SetElement函数就是将矩阵A(row,col)的值设置为value。GetSubMatrix函数就是得到矩阵A的子矩阵,用matlab的语法表示就是Asub=A[row:row+BLOCK_SIZE,col:col+BLOCK_SIZE]。
host端代码还是很常规的,下面重点分析__global__标记的函数。这个函数是以block为单位组织的,她首先获取矩阵C的一个子矩阵Csub,然后用该block内的线程ID索引Csub矩阵的所有元素。每一次for循环,获取A的子矩阵Asub、B的子矩阵Bsub(请参考上述示意图)。然后将Asub、Bsub的有global memory搬迁到shared memory。__syncthreads()的作用是,等所有的线程都将数据搬迁完了,再向下执行。之后的一个for循环完成的功能是Asub、Bsub对应元素向量点击运算。沿A的宽度方向、B的高度方向迭代,即可完成Csub内所有点的向量点击运算。
总结:引入shared memory的好处可以概括为“不要把时间浪费在路上,尤其是路途遥远的路上”。将Global memory的数据搬迁到thread比较费时。
以上是关于GPU编程--Shared Memory的主要内容,如果未能解决你的问题,请参考以下文章