C++实现矩阵压缩
Posted 狼行博客园
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++实现矩阵压缩相关的知识,希望对你有一定的参考价值。
C++实现矩阵压缩
转置运算时一种最简单的矩阵运算。对于一个m*n的矩阵M,他的转置矩阵T是一个n*m的矩阵,且T(i,j) = M(j,i).
一个稀疏矩阵的转置矩阵仍然是稀疏矩阵。
矩阵转置
方案一:
1将矩阵的行列值相互交换
2将每个原则中的i j 相互交换
3重新排列三元组之间的次序
这种方法实现比较简单,一次迭代交换i j 值。
然后就是两层循环进行排序操作了。
方案二
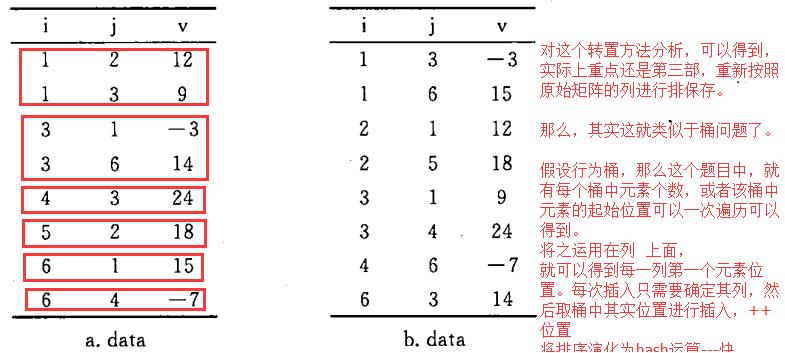
具体实心步骤:
1 迭代遍历,统计列中元素个数
2 由1的结果迭代计算每一列中元素起始位置
3 依据2中得到数据进行转置操作
代码实现如下
//稀疏矩阵 #pragma once #include <vector> template<class T> class Trituple { public: Trituple(int row, int col, T& n) :_row(row) , _col(col) , _value(n) {} int _row; int _col; T _value; }; template<class T> class SparseMatrix//稀疏矩阵 { public: SparseMatrix(T*a, const int m, const int n, T& invalid)///行序排列 :_rowSize(m) , _colSize(n) , _invalid(invalid) { size_t index = 0; for (int i = 0; i < _rowSize; ++i) { for (int j = 0; j < _colSize; ++j) { if (a[i*n + j] != _invalid) { _array.push_back(*(new Trituple<T>(i, j, a[i*n + j]))); //_array[index++] = (new Trituple<T>(i,j,a[i*n+j])); } } } } void Print() { size_t index = 0; for (int i = 0; i < _rowSize; ++i) { for (int j = 0; j < _colSize; ++j) { //if (_array[i*_colSize + j]._value != _invalid) if ((_array[index]._row == i)&&(_array[index]._col == j)) { cout << _array[index++]._value << "->"; } else { cout << _invalid<<" ->"; } } cout << endl; } cout << endl; } //转置方案:交换行列大小 值,交换元祖内部行列值. 重新排序vector; SparseMatrix<T> Transpose() { SparseMatrix<T> x(*this); ::swap(x._rowSize, x._colSize); x._array.clear(); int i = 0; for (int j = 0; j < _colSize; ++j) { i = 0; while (i < _array.size()) { if (j == _array[i]._col) { ////////////////////////////////////////////////////////////////// //Trituple<T> t(_array[i]._row, _array[i]._col, _array[i]._value); Trituple<T> t(_array[i]._col, _array[i]._row, _array[i]._value); x._array.push_back(t); } ++i; } } return x; } SparseMatrix<T> FastTranspose() { //①:计算并保存每一列中非0元的个数; //②:求col列中第一个非0元在矩阵中的行位置。 //③:依据以上,进行插入操作,并且更新cpot中的值 SparseMatrix<T> x(*this); x._colSize = _rowSize; x._rowSize = _colSize; x._invalid = _invalid; if (_array.size()) { int* RowCount = new int[_colSize]; //列中元素数 int* RowStart = new int[_colSize]; //列中元素起始位置 memset(RowCount, 0, sizeof(int)*_colSize); memset(RowStart, 0, sizeof(int)*_colSize); int index = 0; while (index < _array.size()) //一次迭代O(n) { ++RowCount[_array[index++]._col]; } index = 1; while (index < _colSize) //O(n) { RowStart[index] = RowStart[index - 1] + RowCount[index - 1]; ++index; } //执行快速转置 int i = 0; while (i < _array.size()) //两次迭代 O(n) { int col = _array[i]._col; int start = RowStart[col]; x._array[start]._row = _array[i]._col; x._array[start]._col = _array[i]._row; x._array[start]._value = _array[i]._value; ++RowStart[col]; i++; } delete[]RowCount; delete[]RowStart; }//if return x; } ~SparseMatrix() { } private: vector<Trituple<T> > _array; size_t _rowSize; size_t _colSize; T _invalid; };
以上是关于C++实现矩阵压缩的主要内容,如果未能解决你的问题,请参考以下文章