基本概念之算法
Posted 在下雨的Tokyo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基本概念之算法相关的知识,希望对你有一定的参考价值。
什么是算法
算法(Algorithm)定义:
- 一个有限指令集:一堆指令放在一起做一件事情,而这个指令集一定是有限的
- 有零个或多个输入(有些情况下不需要输入)
- 有一个或多个输出(一定有输出)
- 一定在有限步骤之后终止
- 每一条指令必须
- 有充分明确的目标,不可以有歧义
- 计算机能处理的范围之内
- 描述不依赖于任何一种计算机语言以及具体的手段
例1:选择排序算法的伪码描述
void SelectionSort(int List[],int N){ /*将N个整数List[0]...List[N-1]进行非递减排序*/ for(i=0;i<N;i++){ MinPosition=ScanForMin(List,i,N-1); /*从List[i]到List[N-1]中找最小元,并将其位置赋给MinPosition;*/ Swap(List[i],List[MinPosition]); /*将未排序部分的最小元换到有序部分的最后位置;*/ } }
这段伪码的描述是比较抽象的:
- 抽象点1:List到底是数组还是链表?
- 抽象点2:swap用函数还是用宏去实现?
这两个抽象点都需要具体的实现,但是在算法中,这种具体的实现过程是不被关心的。
什么是好的算法?
用以下两个指标来衡量:
- 空间复杂度S(n)——根据算法写成的程序在执行时占用存储单元的长度。这个长度往往与输入数据的规模有关。空间复杂度过高的算法可能导致使用的内存超限,造成程序非正常中断。
- 时间复杂度T(n)——根据算法写成的程序在执行时耗费时间的长度。这个长度往往也与输入数据的规模有关。时间复杂度过高的算法可能导致我们在有生之年都等不到运行结果。
这两个指标与我们处理数据的规模是直接相关的。
例2:PrintN函数的递归实现
1 void PrintN(int N){ 2 if(N){ 3 PrintN(N-1); 4 printf("%d\\n",N); 5 } 6 }
当N=100000时,程序是非正常跳出了。
分析原因:当传入参数N=100000时,程序判断N不为0,开始递归调用PrintN。在调用之前,系统会把当前的函数所有的现有的状态都存到系统内存的某个地方,

然后执行递归函数,执行完后,系统会把这些存储状态回复回来,接着执行此函数的下一句,

直到递归到N为1的时候。

可以发现程序占用空间的数量实际上与原始N的大小成正比,S(N)=C*N,当N非常大的时候,程序可利用的空间有限,会直接爆掉,所以非正常退出了。
但是在循环程序里面,只用到了一个临时变量和一个for循环,没有涉及任何程序调用的问题,所以不管N多大,它所占用的空间始终是固定的,占用空间的量不会随着N的增长而增长,空间占用始终是一个常量,不会出现问题。
例3:求多项式的值。
1 double f(int n,double a[],double x){ 2 int i; 3 double p=a[0]; 4 for(i=1;i<=n;i++){ 5 p+=(a[i]*pow(x,i));//累加求和 6 } 7 return p; 8 }
1 double f(int n,double a[],double x){ 2 int i; 3 double p=a[n]; 4 for(i=n;i>0;i--){ 5 p=a[i-1]+x*p; 6 } 7 return p; 8 }
在分析程序运行效率时,机器执行加减法的效率比执行乘除法的效率要快很多。
第一个函数,每一次for循环执行i次乘法,不要忽略pow(x,i)函数每次执行i-1次乘法,总共执行的乘法次数是:1+2+...+n=(n+1)n/2
第二个函数,每次循环只执行了1次乘法,总共执行的乘法次数是:n
那么,用时间复杂度来衡量时,T1(n)=C1n2+C2n,T2(n)=C•n,当n很大时,第二个程序比第一个程序要快很多很多。
在分析一般算法的效率时,经常关注下面两种复杂度:
- 最坏复杂度Tworst(n)
- 平均复杂度Tavg(n)
显然Tavg(n)<=Tworst(n),我们一般倾向于计算Tworst(n),因为“平均”在不同情况下有不同的理解,分析起来比较复杂。
复杂度的渐进表示
在分析一个算法时,没必要将算法执行了多少次一步步数出来,需要关注的是随着数据规模的增大,复杂度增长的性质是怎样变化的。
- T(n)=O(f(n))表示存在常数C>0,n0>0,使得当n>=n0时有T(n)<=C·f(n)
- T(n)=Ω(g(n))表示存在常数C>0,n0>0,使得当n>=n0时有T(n)<=C·g(n)
- T(n)=θ(h(n))表示同时有T(n)=O(h(n))和T(n)=Ω(h(n))
当讨论一个函数复杂度的上界和下界时,其实不是唯一的,它可以有无穷多个上界和下界。但是太大的上界和太小的下界对于分析算法而言是没有帮助的,所以用大O记法时,一般取能找到的最小的上界,最大的下界。
| 函数 | 1 | 2 | 4 | 8 | 16 | 32 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| logn | 0 | 1 | 2 | 3 | 4 | 5 |
| n | 1 | 2 | 4 | 8 | 16 | 32 |
| nlogn | 0 | 2 | 8 | 24 | 64 | 160 |
| n2 | 1 | 4 | 16 | 64 | 256 | 1024 |
| n3 | 1 | 8 | 64 | 512 | 4096 | 32768 |
| 2n | 2 | 4 | 16 | 256 | 65536 | 4294967296 |
| n! | 1 | 2 | 24 | 40326 | 2092278988000 | 26313×1033 |
在表中所列的输入规模n的最大值才取到32,函数中logn以什么为底并不重要,加了底只是多了一个常数倍而已,影响不大。
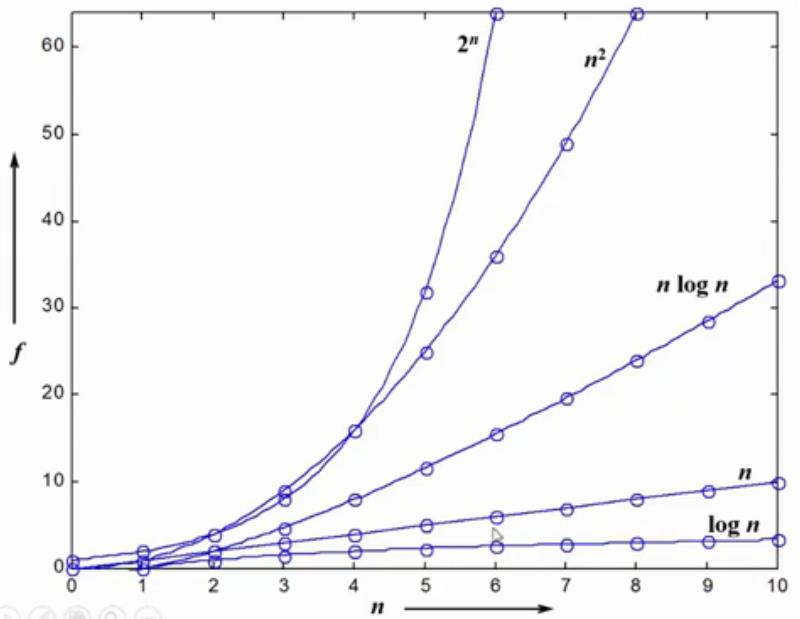
这张图显示了不同函数增长的速率,作为专业的程序员,如果设计的算法复杂度达到n2,要考虑能不能降低算法的复杂度。
| n | f(n)=n | nlogn | n2 | n3 | n4 | n10 | 2n |
| 10 | .01us | .03us | .1us | 1us | 10us | 10sec | 1us |
| 20 | .02us | .09us | .4us | 8us | 160us | 2.84hr | 1ms |
| 30 | .03us | .15us | .9us | 27us | 810us | 6.83d | 1sec |
| 40 | .04us | .21us | 1.6us | 64us | 2.56ms | 121.36d | 13d |
| 50 | .05us | .28us | 2.5us | 125us | 6.25ms | 3.1yr | 4×1013yr |
| 100 | .10us | .66us | 10us | 1ms | 100ms | 3171yr | 32×10283yr |
| 1000 | 1.00us | 9.96us | 1ms | 1sec | 16.67min | 3.17×1013yr | |
| 10000 | 10us | 130.03us | 100ms | 16.67min | 115.7d | 3.17×1023yr | |
| 100000 | 100us | 1.66ms | 10sec | 11.57d | 3171yr | 3.17×1033yr | |
| 1000000 | 1.0ms | 19.92ms | 16.67min | 31.71yr | 3.17×107yr | 3.17×1043yr | |
| us=微秒=10-6秒 | sec=秒 | hr=小时 | yr=年 | ms=毫秒=10-3秒 | min=分钟 | d=日 |
复杂度分析小窍门
- 若两段算法复杂度分别有T1(n)=O(f1(n))和T2(n)=O(f2(n)),则
- T1(n)+T2(n)=max(O(f1(n)),O(f2(n)))
- T1(n)×T2(n)=O(f1(n)×f2(n))
- 若T(n)是关于n的k阶多项式,那么T(n)=Θ(nk)
- 一个for循环的时间复杂度等于循环次数乘以循环体代码的复杂度
- if-else结构的复杂度取决于if的条件判断复杂度和两个分支部分的复杂度,总体复杂度取三者中最大

以上是关于基本概念之算法的主要内容,如果未能解决你的问题,请参考以下文章