JavaScript高级程序设计(第三版)学习笔记111217章
Posted 平凡世界平凡人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JavaScript高级程序设计(第三版)学习笔记111217章相关的知识,希望对你有一定的参考价值。
第11章, DOM扩展
选择符 API
querySelector方法
//取得body 元素 var body = document.querySelector(“body”); //取得ID 为”myDiv”的元素 var myDiv = document.querySelector(“#myDiv”); //取得类为”selected” 的第一个元素 var selected = document.querySelector(“.selected”); //取得类为”button” 的第一个图像元素 var img = document.querySelector(“img.button”);
querySelectorAll方法
//取得某<div>中所有<em>元素(类似getElementsByTagName("em")) var ems = document.getElementById("myDiv").querySelectorAll("em"); //取得类为"selected"的所有元素 var selecteds = document.querySelectorAll(".selectored"); //取得所有<p>元素中的所有<strong>元素 var strongs = document.querySelectorAll("p strong");
封装该方法代码:
function matchesSelector(element,selecrot){ if(element.matchesSelector){ return element.matchesSelector(selector); }else if(element.msMatchesSelector){ return element.msMatchesSelector(selector); }else if(element.mozMatchesSelector){ return element.mozMatchesSelector(selector); }else if(element.webkitMatchesSelector){ return element.webkitMatchesSelector(selector); }else { throw new Error("Not supported"); } } if(matchesSelector(document.body,"body.page1")){ //操作 }
元素遍历
html5
1、getElementsByClassName方法
//取得所有类中包含"username"和"current"的元素,类名先后顺序无关 var allCurrentUsernames = document.getElementsByClassName("username current"); //取得ID为"myDiv"的元素中所有类名"selected"的所有元素 var selected = document.getElementById("myDiv").getElementsByClassName("selected");
2、classList属性
<div class="bd user disabled">..</div> //删除"disabled"类 div.classList.remove("disabled"); //切换"user"类 div.classList.toggle("user");
焦点管理
H5扩展了HTMLDocument
1、readyState属性
2、兼容模式
3、head属性
字符集属性
H5新增charset属性,表示文档实际使用字符集,可更改,支持浏览器IE,Safari,Chrome,Opera。Firefox支持Characterset
defaultCharset属性,表示根据默认浏览器和操作系统设置,确定用啥字符集,支持浏览器IE,Safari,Chrome
可以自定义非标准属性,要添加前缀data-,dataset属性可以访问,dataset是DOMStringMap的实例
插入标记
1、innerHTML属性
读模式,返回与调用元素的所有子节点对应的HTML标记,包括属性,注释,文本节点
写模式,根据指定值创建DOM树,然后用这个DOM树替换原先所有子节点
注:设置的HTML字符串,会经过解析
注:限制:在大多数浏览器中通过此属性插入<script>元素并不会执行其中的脚本,IE8及更早版本可以,条件还挺多
不支持此属性的元素:<col>,<colgroup>,<frameset>,<head>,<html>,<style>,<table>,<tbody>,<thead>,<tfoot>,<tr>,在IE8及更早浏览器<title>也没有
2、outerHTML属性
读模式,返回与调用元素的所有子节点对应的HTML标记
写模式,根据指定值创建DOM树,然后用这个DOM树替换原先元素
支持的浏览器IE4+,Safari4+,Chrome,Opera8+。Firefox7及之前版本都不支持
3、insertAdjacentHTML方法
接收两个参数:要插入的位置,要插入的HTML文本,第一个参数必须是下列值之一
"beforebegin",在当前元素之前插入紧邻的同辈元素
"afterbegin",在当前元素插入一个新的子元素或在第一个子元素之前插入新的子元素
"beforeend",在当前元素之下插入一个新的子元素或在最后一个子元素之后插入新的子元素
"afterend",在当前元素之后插入一个同辈元素
4、内存性能问题
使用以上的方法可能造成浏览器内存占用问题。调用方法是,最好手工删除被替换元素的所有事件处理程序
注:尽量减少innerHTML和outerHTML的次数,压缩使用
例:
for(var i = 0, len = values.length;i < len; i++){ ul.innerHTML += "<li>"+values[i] +"</li>"; //要访问两次innerHTML,一次读,一次写,渣渣的性能 } //改进版本: var item = ""; for(var i = 0, len = values.length;i < len; i++){ item += "<li>"+values[i] +"</li>"; //构建HTML字符串 } ul.innerHTML = item; //只进行一次调用,一定程度上提高了性能 document.documentMode; //返回给定页面使用的文档模式的版本号
contains方法:接收一个参数,要检测的节点,返回调用此方法的节点是否包含检测节点
支持的浏览器IE,Safari,Firefox9+,Chrome,Opera。
DOM Level 3 compareDocumentPosition方法也可以确定节点间关系,支持浏览器IE9+,Safari,Firefox,Chrome,Opera9.5+。返回用于表示两个节点间的关系的位掩码
|
掩码 |
节点关系 |
|
1 |
无关,给定节点不在当前文档中 |
|
2 |
居前 |
|
4 |
居后 |
|
8 |
包含 |
|
16 |
被包含 |
插入文本
没有纳入H5规范的属性
1、innerText
<div id="content"> <p>This is a <strong>paragraph</strong> with a list following it.</p> <ul> <li>Item 1</li> <li>Item 2</li> <li>Item 3</li> </ul> </div>
对<div>元素而言innerText返回:(不一定包含原始代码的缩进)
This is a paragraph with a list following it.
Item 1
Item 2
Item 3
使用innerText设置:
div.innerText = "hello world!";
结果:
<div id="content">hello world!</div>
注:innerText也会对文本中的HTML语法字符(>,<,",&)进行编码
支持的浏览器IE4+,Safari3+,Chrome,Opera8+。Firefox不支持,但支持类似属性textContent属性,textContent是DOM Level 3规定的一个属性,IE9+,Safari3+,Chrome,Opera10+也支持textContent
2、outerText
除了作用范围扩大到了包含调用它的节点之外,outerText与innerText基本一样
第12章,DOM2和DOM3
DOM1级主要定义HTML和XML文档底层结构。DOM2和DOM3则在此基础引入更多交互能力,支持更高级的XML特性。
DOM2级:
核心:在1级基础上,为节点添加更多方法和属性
视图:为文档定义了基于样式信息的不同视图
事件:说明了如何使用事件与DOM文档交互
样式:定义了如何以编程方式来访问和改变CSS样式信息
遍历和范围:引入了遍历DOM文档和选择其特定部分的新接口
HTML:在1级基础上,添加更多属性,方法和新接口
检测浏览器是否支持DOM模块:
var supportsDOM2Core = document.implementation.hasFeature("Core","2.0"); var supportsDOM3Core = document.implementation.hasFeature("Core","3.0"); var supportsDOM2HTML = document.implementation.hasFeature("HTML","2.0"); var supportsDOM2Views = document.implementation.hasFeature("Views","2.0"); var supportsDOM2XML = document.implementation.hasFeature("XML","2.0");
针对XML命名空间变化
<!-- 不加前缀:--> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <title>Example XHTML page</title> </head> <body> Hello World! </body> </html> <!-- 加前缀:--> <xhtml:html xmlns:xhtml="http://www.w3.org/1999/xhtml"> <xhtml:head> <xhtml:title>Example XHTML page</xhtml:title> </xhtml:head> <xhtml:body> Hello World! </xhtml:body> </xhtml:html>
混合使用两种语言,命名空间用处才能够体现
DOM2级核心为大多数DOM1级方法提供特定于命名空间的版本解决问题
1、Node类型变化
在DOM2级,包含下列特定于命名空间的属性
localName:不带命名空间前缀的节点名称
namespaceURI:命名空间URI或(未指定情况下)null
prefix:命名空间前缀或(未指定情况)null
当节点使用了命名空间前缀时,nodeName等于prefix+":"+localName,如下:
<html xmlns="http://www.w3.org/1999/xhtml"> <head> <title>Example XHTML page</title> </head> <body> <s:svg xmlns:s="http://www.w3.org/2000/svg" version="1.1" viewBox="0 0 100 100" style="width:100%; height:100%"> <s:rect x="0" y="0" width="100" height="100" style="fill:red"/> </s:svg> </body> </html>
<html>:localName和tagName="html",namespaceURI="http://www.w3.org/1999/xhtml",prefix=null
<s:svg>:localName="svg",tagName="s:svg",namespaceURI="http://www.w3.org/2000/svg",prefix="s"
DOM3级在此基础再引入:
isDefaultNamespace(namespaceURI),指定的namespaceURI是否是当前节点的默认命名空间
lookupNamespaceURI(prefix),返回给定的prefix的命名空间
lookupPrefix(namespaceURI),返回给定的namespaceURI的前缀
2、Document类型变化
包含下列与命名空间有关的方法:
createElementNS(namespaceURI,tagName):使用给定的tagName创建一个属于命名空间namespaceURI的新元素
createAttributeNS(namespaceURI,attributeName):使用给定的attributeName创建一个属于命名空间namespaceURI的新特性
getElementsByTagNameNS(namespaceURI,tagName):返回属于命名空间namespaceURI的tagName元素的NodeList
例:
//创建一个新的svg元素 var svg = document.createElementNS("http://www.w3.org/2000/svg","svg"); //创建一个属于某个命名空间的新特性 var att = document.createAttributeNS("http://www.somewhere.com","random"); //取得所有XHTML元素 var elems = document.getElementsByTagNameNS("http://www.w3.org/1999/xhtml","*");
注:只有在文档中存在多个命名空间的时候,这些与命名空间有关的方法才是必需的
3、Element类型变化
主要涉及操作特性,新增方法如下
getAttributeNS(namespaceURI,localName):取得属于命名空间namespaceURI且名为localName的特性
getAttributeNodeNS(namespaceURI,localName):取节点
getElementsByTagNameNS(namespaceURI,tagName):返回属于命名空间的tagName元素的NodeList
hasAttributeNS(namespaceURI,localName):确定当前元素是否有一个名为localName的特性,而且该特性的命名空间是namespaceURI。注意:DOM2核心,也增加一个hasAttribute方法,用于不考虑命名空间的情况
removeAttributeNS(namespaceURI,localName):删除特性
setAttributeNS(namespaceURI,qualifiedName,value):设置属于命名空间且名为qualifiedName的特性值为value
setAttributeNodeNS(attNode):设置属于命名空间的特性节点
注:除第一个参数外,这些方法与DOM1级相关方法作用相同
4、NamedNodeMap类型变化
新增方法多数情况只针对特性使用
其他变化
1、DocumentType类型
新增属性:publicId,systemId,internalSubset,前两个表示文档类型声明中的信息段,在DOM1中无法访问
使用:document.doctype.publicId
internalSubset用于访问文档类型声明中的额外定义
就是没啥用的说
2、Document类型
变化中唯一与命名空间无关的方法:importNode(),用途:从一个文档中取得一个节点,将其导入到另一个文档
注:每个节点都有一个ownerDocument属性,使用appendChild时传入的节点属于不同文档,则会出错,importNode则不会
与Element的cloneNode方法非常相似,接收两个参数,要复制的节点,是否复制子节点的布尔值
DOM2级视图添加defaultView属性,指向拥有给定文档的窗口,除IE外,都支持,IE支持等价属性:parentWindow
DOM2级核心为document.implementation对象规定两个新方法:createDocumentType(创建新的DocumentType节点,接收三个参数:文档类型名称,publicId,systemId),creteDocument(接收三个参数:针对文档元素的namespaceURI,文档元素标签名,新文档的文档类型)
DOM2级HTML为document.implementation新增方法createHTMLDocument,接收一个参数:新创建的文档的标题,只有Opera和Safari支持
3、Node类型
唯一一个与命名空间无关变化,isSupported方法用于确定当前节点具有啥能力,接收两个参数:特性名,版本号,存在于hasFeature相同的问题
建议:最好还是使用能力检测确定某个特性是否可用
DOM3级:isSameNode和isEqualNode,接收一个节点参数
isSameNode是否同一个对象,指向的是同一个对象
isEqualNode是否相同类型,具有相等属性(相同位置,相同值)
例:
var div1 = document.createElement("div"); div1.setAttribute("class","box"); var div2 = document.createElement("div"); div2.setAttribute("class","box"); alert(div1.isSameNode(div1)); //true alert(div1.isEqualNode(div2)); //true alert(div1.isSameNode(div2)); //false
DOM3级:setUserData,接收3个参数:要设置的键,实际数据,处理函数
getUserData传入相同的键可以获得数据
处理函数接收5个参数:操作类型(1复制,2导入,3删除,4重命名),数据键,数据值,源节点,目标节点
4、框架变化
样式
定义样式方式:<link/>包含外部文件,<style/>定义嵌入样式,style特性定义针对特定元素样式
//确定浏览器是否支持DOM2级定义CSS能力 var supportsDOM2CSS = document.implementation.hasFeature("CSS","2.0"); var supportsDOM2CSS2 = document.implementation.hasFeature("CSS2","2.0");
style特性中指定的任何CSS属性都将表现为这个style对象的属性,对于使用短划线(background-image)的CSS属性,必须转换为驼峰大小写形式
注:float为js保留字,不能通过大小写转换,DOM2级样式规定,对应对象属性名应是cssFloat,Firefox,Safari,Opera,Chrome都支持,IE支持styleFloat
1、DOM样式属性和方法:
cssText:访问style特性中的CSS代码
length:CSS属性数量
parentRule:CSS信息的CSSRule对象
getPropertyCssValue(propertyName):返回给定属性值的CSSValue对象
getPropertyPriority(propertyName):若给定的属性使用了!important设置,返回important,否则,返回空串
getPropertyValue(propertyName):返回给定属性的字符串值
item(index):返回给定位置的CSS属性名称
removeProperty(propertyName):从样式中删除给定属性
setProperty(propertyName,value,priority):将给定属性设置为相应的值,并加上优先权标志(important或一个空串)
操作样式表
CSSStyleSheet类型表示的是样式表,CSSStyleSheet对象是一套只读接口,CSSStyleSheet继承自StyleSheet
应用于文档的所有样式表通过document.styleSheets集合来表示,通过length可以知道样式表数量,通过方括号法和item方法可以访问每一个样式表
1、CSS规则
CSSRule对象表示样式表中每一条规则,实际上是一个供其他多种类型继承的基类型,常见的是CSSStyleRule类型
2、创建规则
使用insertRule方法,接收两个参数:规则文本,在哪里插入规则的索引
支持浏览器:Firefox,Safari,Opera,Chrome。IE8及更早版本支持类似方法addRule,接收两个必选参数:选择符文本和CSS样式信息,一个可选参数:插入规则位置
建议:采用之前介绍过的动态加载样式表的技术
3、删除规则:慎用
deleteRule接收一个参数:要删除的规则的位置
遍历
DOM2级遍历和范围定义了顺序遍历DOM结构的类型:NodeIterator,TreeWalker,这两个类型执行深度优先遍历(深搜)
NodeIterator类型
可以使用document.createNodeIterator方法创建实例,接收4个参数:root(起点),whatToShow(要访问的节点的数字代码),filter(NodeFilter对象,或表示应该接受或拒绝某种特定节点的函数),entityReferenceExpansion(布尔值,是否要扩展实体引用)
whatToShow是一个掩位码,以常量形式在NodeFilter类型中定义
NodeFilter.SHOW_ALL:显示所有
NodeFilter.SHOW_ELEMENT:显示元素节点
NodeFilter.SHOW_ATTRIBUTE:特性节点,由于DOM结构原因,实际上,这个值不能使用
NodeFilter.SHOW_TEXT:文本节点
NodeFilter.SHOW_CDATA_SECTION:显示CDATA节点,对HTML没用
NodeFilter.SHOW_ENTITY_REFERENCE:实体引用节点,对HTML没用
NodeFilter.SHOW_ENTITYE:实体节点,对HTML没用
NodeFilter.SHOW_PROCESSING_INSTRUCTION:处理指令节点,对HTML没用
NodeFilter.SHOW_COMMENT:注释节点
NodeFilter.SHOW_DOCUMENT:文档节点
NodeFilter.SHOW_DOCUMENT_TYPE:文档类型节点
NodeFilter.SHOW_DOCUMENT_FRAGMENT:文档片段节点,对HTML没用
NodeFilter.SHOW_NOTATION:符号节点,同上
除NodeFilter.SHOW_ALL外,可以使用按位或操作符组合多个选项
每个NodeFilter对象只有一个方法:acceptNode(),返回NodeFilter.FILTER_ACCEPT或者NodeFilter.FILTER_SKIP,NodeFilter是一个抽象类型,不能直接创建实例,必要时可以创建一个包含accpetNode方法的对象,传入createNodeIterator即可
例:
var filter = { acceptNode:function(node){ return node.tagName.toLowerCase() == "p" ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP; } }; var iterator = document.createNodeIterator(root,NodeFilter.SHOW_ELEMENT,filter,false); //或者使用一个与acceptNode方法类似的函数 var filter = function(node){ return node.tagName.toLowerCase() == "p" ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP; };
NodeIterator类型两个主要方法:nextNode(),previousNode()
TreeWalker
NodeIterator的更高级版本除了NodeIterator的两个方法外,还提供用于在不同方向遍历DOM的方法:
parentNode():遍历到当前节点父节点
firstChild():到当前节点的第一个子节点
lastChild():到当前节点的最后一个子节点
nextSibling():到当前节点的下一个同辈节点
previousSibling():到当前节点的上一个同辈节点
使用document.createTreeWalker方法,与document.createNodeIterator类似接收4各参数:根节点,要显示的节点类型,过滤器,是否扩展实体引用布尔值
不同:filter返回值:除了 NodeFilter.FILTER_ACCEPT,NodeFilter.FILTER_SKIP,还有NodeFilter.FILTER_REJECT,NodeFilter.FILTER_SKIP会进入子节点搜索,而NodeFilter.FILTER_REJECT则跳过整个子节点树,剪枝算法
TreeWalker类型还有一个属性:currentNode,通过修改此属性还能改变搜索起点
范围(有点难)
DOM2级在Document类型中定义了createRange方法。属于document对象,使用hasFeature或直接检测该方法,可以确定浏览器是否支持范围
注:新创建的范围直接与创建它的文档关联,只能用于当前文档
每个范围由一个Range实例表示,下列属性提供了当前范围在文档中的信息:
startContainer:包含范围起点的节点(选区中第一个子节点的父节点)
startOffset:范围在startContainer中起点的偏移量,若startContainer是文本节点,注释节点,CDATA节点,则startOffset就是范围起点之前跳过的字符数量,否则就是范围中第一个子节点的索引
endContainer:包含范围重点的节点(即选区中最后一个节点的父节点)
endOffset:范围在endContainer中终点的偏移量,与startOffset规则相同
commonAncestorContainer:startContainer和endContainer共同祖先节点在文档树位置最深的那个
1、使用DOM范围实现简单选择
使用selecNode和selectNodeContents方法使用范围选择文档一部分,两个方法都接收一个参数:DOM节点,selectNode选择整个节点,selectNodeContents选择节点的子节点
例:
<!DOCTYPE html> <html> <body> <p id="p1"><b>Hello</b> world!</p> </body> </html>
var range1 = document.createRange(); range2 = document.createRange(); p1 = document.getElementById("p1"); range1.selectNode(p1); range2.selectNodeContainer(p1);
结果
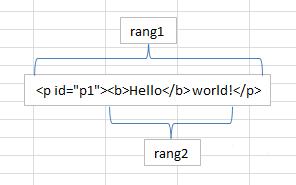
调用selectNode时,startContainer,endContainer,commonAncestorContainer都是传入的父节点,也就是document.body,startOffset等于给定节点在其父节点的childNodes集合中的索引,endOffset=startOffset+1,因为只选了一个节点
调用selectNodeContainer时,startContainer,endContainer,commonAncestorContainer都是传入的节点,也就是<p>元素,startOffset始终等于0,因为范围从给定节点的第一个子节点开始,endOffset等于子节点数量,本例中是2
2、使用DOM范围实现复杂选择(关键)(难度在这里,搞定了这个,之后的操作就没啥大问题,需要再研究研究)
3、操作DOM范围中的内容
4、插入DOM范围中的内容
5、折叠DOM范围
6、比较DOM范围
7、复制DOM范围
8、清理DOM范围
IE8及更早版本中的范围
IE8及更早版本并不支持DOM范围(IE就是这么拽),支持类似概念文本范围
第17章,错误处理与调试
使用try-catch,throw语句得到一定的错误信息
格式:
try{ //可能出错的代码 }catch(error){ //出错时应该怎么处理的代码 }
finally语句是try-catch语句的可选语句,但finally语句一经使用,无论如何都会执行。有了finally语句,catch就成了可选的
注:IE7及更早版本有bug:除非有catch语句,否则不执行finally语句,(又来拽一波了)
错误类型
Error
EvalError
RangeError
ReferenceError
SyntaxError //语法错误
TypeError //类型错误
URIError
Error是基类,其他类型都继承自该类,所有错误类型共享同一组属性
EvalError在使用eval是抛出,简单说,就是没有把eval当函数用,就抛出错误
RangeError在数值超出相应范围时触发
var item = new Array(-20); //触发 var item = new Array(Number.MAX_VALUE); //触发
找不到对象,发生ReferenceError
变量保存意外类型,访问不存在的方法,都会抛出TypeError
var o = new 10; alert("name" in true); Function.prototype.toString.call("name"); //以上都会抛出TypeError
encodeURI,decodeURI,会抛出URIError,少见,这两货的容错性高
遇到throw操作符,代码立即停止执行
throw 1234; throw "hello"; throw true; throw {name:"js"}; //以上代码都是有效的
还可以创建自定义错误消息:
throw new Error("some message"); throw new SyntaxError("syntax error"); throw new ReferenceError("reference error");
还能够创建自定义错误类型:(通过继承Error)
function CustomError(message){ this.name = "CustomError"; this.message = message; } CustomError.prototype = new Error(); throw new CustomError("my message");
错误事件
任何没有通过try-catch处理的错误都会触发window对象的error事件
常见错误类型
类型转换错误
数据类型错误
通信错误
调试技术
将消息记录到控制台
将错误消息记录到当前页面
抛出错误
常见IE错误(IE,最难调试js错误的浏览器,难怪那么拽)
操作终止
无效字符
未找到成员
未知运行时错误
语法错误
系统无法找到指定资源