农大图书馆-新闻公告反爬虫
Posted 随缘梦中人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了农大图书馆-新闻公告反爬虫相关的知识,希望对你有一定的参考价值。
1、地址:http://lib.henau.edu.cn/Default/go?sortID=109
反爬虫的机制,通过cookie值。第1次请求该地址,会检查cookie,如果没有相应的cookie会先通过js设置cookie值。再重新请求该页面。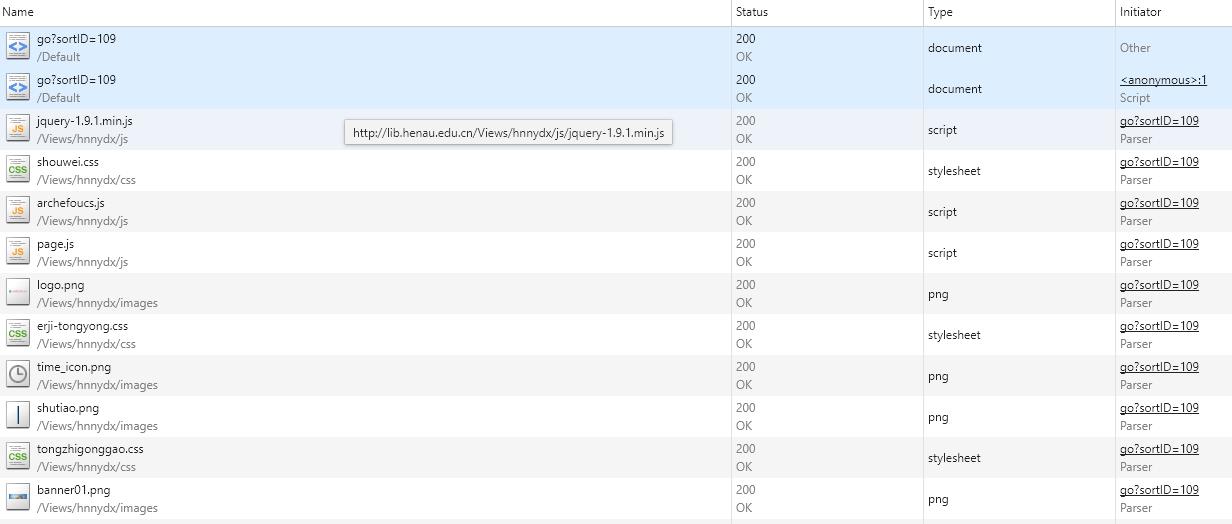
这是第1次请求该页面返回的文档,我们可以看到js设置cookie的代码,
document|href|location|cookie|ant_stream_58b3fe214a7d4|path|3252469838|1496243372
<html> <head> <meta http-equiv="Content-Type" content="text/html;charset=utf-8"> <title>lib.henau.edu.cn</title> </head> <body onload="t3_ar_guard();"> <script> function t3_ar_guard() { eval(function(p, a, c, k, e, d) { e = function(c) { return c }; if (!\'\'.replace(/^/, String)) { while (c--) { d[c] = k[c] || c } k = [function(e) { return d[e] }]; e = function() { return \'\\\\w+\' }; c = 1 }; while (c--) { if (k[c]) { p = p.replace(new RegExp(\'\\\\b\' + e(c) + \'\\\\b\', \'g\'), k[c]) } } return p }(\'0.3="4=7/6;5=/";0.2.1=0.2.1;\', 8, 8, \'document|href|location|cookie|ant_stream_58b3fe214a7d4|path|3252469838|1496243372\'.split(\'|\'), 0, {})) } </script> <a href="/stream_58b3fe214a7d4_59295e01c335c?id=2" style="display:none"></a><a href="/stream_58b3fe214a7d4/admin/" style="display:none">admin</a><a href="/stream_58b3fe214a7d4/wp-admin/" style="display:none">wp-admin</a><a href="/stream_58b3fe214a7d4/backend/" style="display:none">backend</a></body> </html>
2、再次请求页面
发送cookie值:ant_stream_58b3fe214a7d4=1496243372/3252469838

3、对应的python部分代码
headers = {\'User-Agent\':
\'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.25 Safari/537.36\'}
opener = urllib2.build_opener()
# 请求第一次 获取cookie中的script
request = urllib2.Request(url, headers=headers)
html = opener.open(request)
soup = bs4.BeautifulSoup(html, \'html.parser\')
scriptCookie = str(soup.find(\'script\'))
start = scriptCookie.index(\'cookie\')
end = scriptCookie.index("\'.split(")
strs = scriptCookie[start:end].split(\'|\')
opener.addheaders.append(
(\'Cookie\', \'%s=%s/%s\' % (strs[1], strs[4], strs[3])))
html = opener.open(request)
以上是关于农大图书馆-新闻公告反爬虫的主要内容,如果未能解决你的问题,请参考以下文章