jemalloc存储块(regionrunchunk)
Posted YYPapa
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了jemalloc存储块(regionrunchunk)相关的知识,希望对你有一定的参考价值。
jemalloc中按存储单元的块大小分,有region、run、chunk三种存储块。
最小的单元是region,它的大小是8字节~14KB,1个或多个相同大小的region组成一个run。
run的大小必须是页(4kB)的整数倍,相同大小region对应的run的大小总是相同的,多个run组成一个chunk。
chunk的大小固定是2M(或4M,可配置)。
| region size | run size | number of region in run |
| 8 | 4K | 512 |
| 16 | 4k | 256 |
| 32 | 4k | 128 |
| 48 | 12k | 256 |
| 64 | 4k | 64 |
| 80 | 20k | 256 |
| 96 | 12k | 128 |
| 112 | 28k | 256 |
| 128 | 4k | 32 |
| 160 | 20k | 128 |
| 192 | 12k | 64 |
| 224 | 28k | 128 |
| 256 | 4k | 16 |
| 320 | 20k | 64 |
| 384 | 12k | 32 |
| 448 | 28k | 64 |
| 512 | 4k | 8 |
| 640 | 20k | 32 |
| 768 | 12k | 16 |
| 896 | 28k | 32 |
| 1024 | 4k | 4 |
| 1280 | 20k | 16 |
| 1536 | 12k | 8 |
| 1792 | 28k | 16 |
| 2048 | 4k | 2 |
| 2560 | 20k | 8 |
| 3072 | 12k | 4 |
| 3584 | 20k | 8 |
| 4096 | 4k | 1 |
| 5120 | 20k | 4 |
| 6144 | 12k | 2 |
| 7168 | 28k | 4 |
| 8192 | 8k | 1 |
| 10240 | 20k | 2 |
| 12288 | 12k | 1 |
| 14336 | 28k | 2 |
相关代码:
arena_bin_info_t arena_bin_info[NBINS]; static void bin_info_init(void) { arena_bin_info_t *bin_info; #define BIN_INFO_INIT_bin_yes(index, size) \\ bin_info = &arena_bin_info[index]; \\ bin_info->reg_size = size; \\ bin_info_run_size_calc(bin_info); \\ bitmap_info_init(&bin_info->bitmap_info, bin_info->nregs); #define BIN_INFO_INIT_bin_no(index, size) #define SC(index, lg_grp, lg_delta, ndelta, bin, lg_delta_lookup) \\ BIN_INFO_INIT_bin_##bin(index, (ZU(1)<<lg_grp) + (ZU(ndelta)<<lg_delta)) SIZE_CLASSES #undef BIN_INFO_INIT_bin_yes #undef BIN_INFO_INIT_bin_no #undef SC }
gdb中打印arena_bin_info:
(gdb) p je_arena_bin_info
$353 = {{
reg_size = 8,
redzone_size = 0,
reg_interval = 8,
run_size = 4096,
nregs = 512,
bitmap_info = {
nbits = 512,
ngroups = 8
},
reg0_offset = 0
}, {
reg_size = 16,
redzone_size = 0,
reg_interval = 16,
run_size = 4096,
nregs = 256,
bitmap_info = {
nbits = 256,
ngroups = 4
},
reg0_offset = 0
}, {
reg_size = 32,
redzone_size = 0,
reg_interval = 32,
run_size = 4096,
nregs = 128,
bitmap_info = {
nbits = 128,
ngroups = 2
},
reg0_offset = 0
}, {
...
}, {
reg_size = 12288,
redzone_size = 0,
reg_interval = 12288,
run_size = 12288,
nregs = 1,
bitmap_info = {
nbits = 1,
ngroups = 1
},
reg0_offset = 0
}, {
reg_size = 14336,
redzone_size = 0,
reg_interval = 14336,
run_size = 28672,
nregs = 2,
bitmap_info = {
nbits = 2,
ngroups = 1
},
reg0_offset = 0
}}
region、run、chunk之间的位置关系如下:
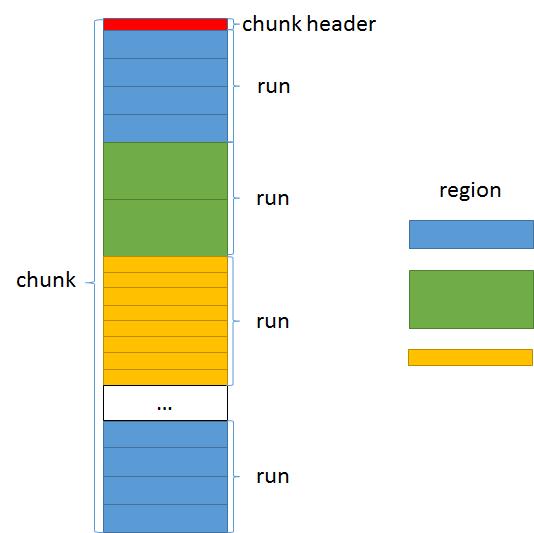
接下来看看chunk header的结构。
以0x7f86a43000这个地址为例,由于静态变量chunk_size的大小是2M:
(gdb) p /x je_chunksize $294 = 0x200000
因此chunk是2M字节对齐的,0x7f86a43000对应的chunk的地址为0x7f86a00000。
chunk数据结构的声明:

typedef struct arena_chunk_s arena_chunk_t;
struct arena_chunk_s {
extent_node_t node;
arena_chunk_map_bits_t map_bits[1]; /* Dynamically sized. */
};
typedef struct extent_node_s extent_node_t;
struct extent_node_s {
arena_t *en_arena;
void *en_addr;
size_t en_size;
bool en_zeroed;
bool en_committed;
bool en_achunk;
prof_tctx_t *en_prof_tctx;
arena_runs_dirty_link_t rd;
qr(extent_node_t) cc_link;
union {
rb_node(extent_node_t) szad_link;
ql_elm(extent_node_t) ql_link;
};
rb_node(extent_node_t) ad_link;
};
运行时0x7f86a00000对应的chunk,它的实际内容如下:
(gdb) p /x *(arena_chunk_t *)0x7f86a00000
$292 = {
node = {
en_arena = 0x7f93e02200,
en_addr = 0x7f86a00000,
en_size = 0x200000,
en_zeroed = 0x1,
en_committed = 0x1,
en_achunk = 0x1,
en_prof_tctx = 0x0,
rd = {
rd_link = {
qre_next = 0x0,
qre_prev = 0x0
}
},
cc_link = {
qre_next = 0x0,
qre_prev = 0x0
},
{
szad_link = {
rbn_left = 0x0,
rbn_right_red = 0x0
},
ql_link = {
qre_next = 0x0,
qre_prev = 0x0
}
},
ad_link = {
rbn_left = 0x0,
rbn_right_red = 0x0
}
},
map_bits = {{
bits = 0x23fe3
}}
}
一个chunk的大小是2M = 512*4K,也就是512个page。
其中,前12个page用于管理块Header,后500个page是实际可使用的内存。
这500个page又被划分为若干个run,每个run又由若干的page组成。
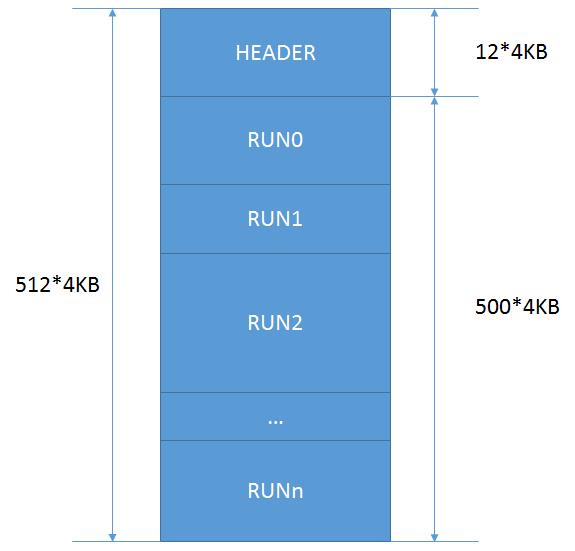
Header的结构如下:
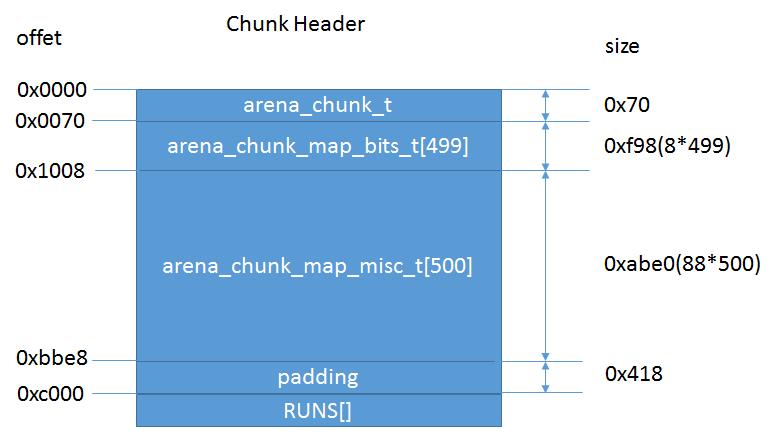
其中arena_chunk_t就是前面介绍过的,描述这个chunk的结构体。
它的最后一个成员map_bits和之后的499个arena_chunk_map_bits_t一起构成一个数组,描述该chunk所包含的500个page。
之后的arena_chunk_map_misc_t同样描述这500个page所属的run。
通过ptr找到所属chunk:
chunk = (arena_chunk_t *)CHUNK_ADDR2BASE(ptr);
其中
#define CHUNK_ADDR2BASE(a) ((void *)((uintptr_t)(a) & ~chunksize_mask))
(gdb) p /x je_chunksize_mask $315 = 0x1fffff
因此0x7f86a43000对应的chunk地址为0x7f86a00000。
我们可以用pageind表示0x7f86a43000这个地址在chunk中的页偏移
pageind = ((uintptr_t)ptr - (uintptr_t)chunk) >> LG_PAGE;
得出pageind = 67:
(gdb) p (0x7f86a43000 - 0x7f86a00000)/0x1000 $318 = 67
因此,这个页对应的mapbits为:
mapbits = chunk->map_bits[pageind-map_bias]);
其中map_bias = 12,因为chunk的前12个page是属于chunk header,真正可用的是第13个page开始的。
(gdb) p /x ((arena_chunk_t *)0x7f86a00000)->map_bits[67-12]->bits
$320 = 0x141
chunk的mapbits的各个位的含义如下:
#define CHUNK_MAP_ALLOCATED ((size_t)0x01U) #define CHUNK_MAP_LARGE ((size_t)0x02U) #define CHUNK_MAP_STATE_MASK ((size_t)0x3U) #define CHUNK_MAP_DECOMMITTED ((size_t)0x04U) #define CHUNK_MAP_UNZEROED ((size_t)0x08U) #define CHUNK_MAP_DIRTY ((size_t)0x10U) #define CHUNK_MAP_FLAGS_MASK ((size_t)0x1cU) #define CHUNK_MAP_BININD_SHIFT 5 #define BININD_INVALID ((size_t)0xffU) #define CHUNK_MAP_BININD_MASK (BININD_INVALID << CHUNK_MAP_BININD_SHIFT) #define CHUNK_MAP_BININD_INVALID CHUNK_MAP_BININD_MASK #define CHUNK_MAP_RUNIND_SHIFT (CHUNK_MAP_BININD_SHIFT + 8) #define CHUNK_MAP_SIZE_SHIFT (CHUNK_MAP_RUNIND_SHIFT - LG_PAGE) #define CHUNK_MAP_SIZE_MASK (~(CHUNK_MAP_BININD_MASK | CHUNK_MAP_FLAGS_MASK | CHUNK_MAP_STATE_MASK))
对应0x141:
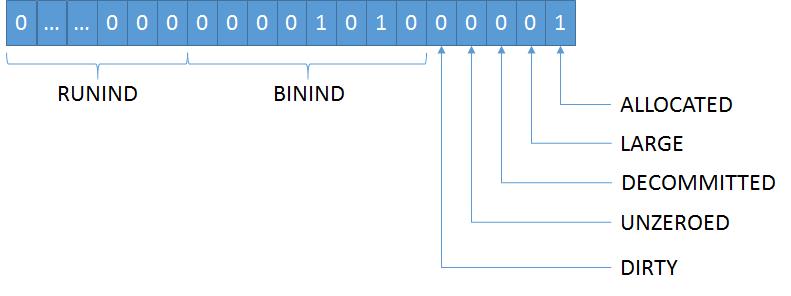
runind = 0b0000 = 0
binind = 0b1010 = 0xa = 10
前面讲过run是由多个page组成,这里的runind就是当前page在其所属run中的索引。
runind = 0表示当前page是其所属run中的第一个page。
(gdb) p /x ((arena_chunk_t *)0x7f86a00000)->map_bits[67-12]->bits $337 = 0x141 (gdb) p /x ((arena_chunk_t *)0x7f86a00000)->map_bits[68-12]->bits $338 = 0x2141 (gdb) p /x ((arena_chunk_t *)0x7f86a00000)->map_bits[69-12]->bits $339 = 0x4141 (gdb) p /x ((arena_chunk_t *)0x7f86a00000)->map_bits[70-12]->bits $340 = 0x381
可以看到68、69号page,他们的runind分别为1和2,因此可知67、68、69是同属于一个run的。
misc = (arena_chunk_map_misc_t *)((uintptr_t)chunk + (uintptr_t)map_misc_offset) + (pageind - runind)- map_bias)
misc的数据结构声明:
typedef struct arena_chunk_map_misc_s arena_chunk_map_misc_t;
struct arena_chunk_map_misc_s { /* * Linkage for run trees. There are two disjoint uses: * * 1) arena_t\'s runs_avail tree. * 2) arena_run_t conceptually uses this linkage for in-use non-full * runs, rather than directly embedding linkage. */ rb_node(arena_chunk_map_misc_t) rb_link; union { /* Linkage for list of dirty runs. */ arena_runs_dirty_link_t rd; /* Profile counters, used for large object runs. */ union { void *prof_tctx_pun; prof_tctx_t *prof_tctx; }; /* Small region run metadata. */ arena_run_t run; }; };
在small region的情况下,misc是由用于连接arena中的rb树的rb_link和arena_run_t结构的run组成。
arena的bins中runcur就是指向某个chunk中的某个arena_chunk_map_misc_t[]中的某个run。
运行时的数据如下:
(gdb) p /x *((arena_chunk_map_misc_t *)0x7f86a01008 + 67 - 12)
$344 = {
rb_link = {
rbn_left = 0x0,
rbn_right_red = 0x1
},
{
...
run = {
binind = 0xa,
nfree = 0x0,
bitmap = {0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}
}
}
}
从run信息可以看到,这个run对应的binind为10,空闲region数为0。
因此,arena_chunk_map_bits_t[500]是描述chunk内的500个page的,而arena_chunk_map_misc_t[500]是描述run的,
一般多个page组成一个run,也就是说一个chunk中run的个数远远小于500个,所以arena_chunk_map_misc_t[500]中很多数据都是空的。
以上是关于jemalloc存储块(regionrunchunk)的主要内容,如果未能解决你的问题,请参考以下文章