用Python实现多核心并行计算
Posted Pentium.Labs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Python实现多核心并行计算相关的知识,希望对你有一定的参考价值。
平常写的程序,无论是单线程还是多线程,大多只有一个进程,而且只能在一个核心里工作。所以很多应用程序即使正在满载运行,在任务管理器中CPU使用量还是只有50%(双核CPU)或25%(四核CPU)
如果能让一个程序自己建立出多个进程,并且让它们并行运行,那么就可以在不同cpu核心上同时运行,进而实现并行计算啦。
Python的并行计算就是这么做的。
之前的理解错了......还是要学习一个
1、多线程与多进程
之前OS课学过.....
in general,线程是比进程低一级的调度单位。一个进程可以包含多个进程。
线程之间的切换相对于进程之间更为方便,代价也更低。所以讲道理多线程的效率比多进程是要高的。
Linux自从2.6内核开始,就会把不同的线程交给不同的核心去处理。Windows也从NT.4.0开始支持这一特性。
【ref:http://blog.csdn.net/delacroix_xu/article/details/5928121
2.多线程与Python
好多语言都可以很好的资词多线程。然而Python是个例外......
对于IO密集型的任务,使用多线程还是能提高一下CPU使用率。对于CPU密集型的任务,Python中的多线程其实是个鸡肋......没卵用......
在Python的解释器CPython中存在一个互斥锁。简单来讲就是同一时间只能有一个线程在执行,其它线程都处于block模式。
【ref:https://www.zhihu.com/question/22191088
3.多进程
要想在py中充分利用多核cpu,就只能用多进程了。
虽然代价高了些,但是比起并行计算带来的性能提升这些也微不足道了。最重要的是好!写!啊!
这里来看第一个sample:
1 #main.py 2 import multiprocessing 3 import time 4 import numpy as np 5 from func import writeln 6 from calc import calc 7 import scipy.io as sio 8 9 def func1(x): 10 calc() 11 c1=0 12 d1=np.zeros(233,int) 13 for i in xrange(5): 14 d1[c1]=writeln(1,i) 15 c1+=1 16 #time.sleep(1) 17 sio.savemat(\'11.mat\',{\'dd\':d1}) 18 19 def func2(x): 20 calc() 21 c2=0 22 d2=np.zeros(233,int) 23 for i in xrange(5): 24 d2[c2]=writeln(2,i) 25 c2+=1 26 #time.sleep(1) 27 sio.savemat(\'22.mat\',{\'dd\':d2}) 28 29 def func3(x): 30 calc() 31 c3=0 32 d3=np.zeros(233,int) 33 for i in xrange(5): 34 d3[c3]=writeln(3,i) 35 c3+=1 36 #time.sleep(1) 37 sio.savemat(\'33.mat\',{\'dd\':d3}) 38 39 def func4(x): 40 calc() 41 c4=0 42 d4=np.zeros(233,int) 43 for i in xrange(5): 44 d4[c4]=writeln(4,i) 45 c4+=1 46 #time.sleep(1) 47 sio.savemat(\'44.mat\',{\'dd\':d4}) 48 49 if __name__ == "__main__": 50 pool = multiprocessing.Pool(processes=4) 51 52 pool.apply_async(func1, (1, )) 53 pool.apply_async(func2, (2, )) 54 pool.apply_async(func3, (3, )) 55 pool.apply_async(func4, (4, )) 56 57 pool.close() 58 pool.join() 59 60 61 print "Sub-process(es) done."
1 #func.py 2 def writeln(x,y): 3 aa=x*10+y 4 print(aa) 5 return(aa)
1 #calc.py 2 def calc(): 3 x=233 4 for i in xrange(1000000000): 5 x=x+1 6 x=x-1
main.py
Line 49 新建一个进程池,并指定本机cpu核心数量为4
这样主程序运行时就会建立出4个额外的进程,每个进程可以运行在不同核心上,从而实现了多核并行
Line 51--54 将func1--func4这四个函数都加到进程池中。
注意,如果我们加入了超过4个func,那么同时只会有四个在运行。剩下的要排队等待
calc.py
这是一个死循环....是为了演示cpu使用量...
运行效果:
单个calc()运行时,CPU占用量是25%

启用multiprocessor之后,一共开启了5个python.exe进程(一个主+4个子进程),cpu占用100%。同时风扇也开始狂转......
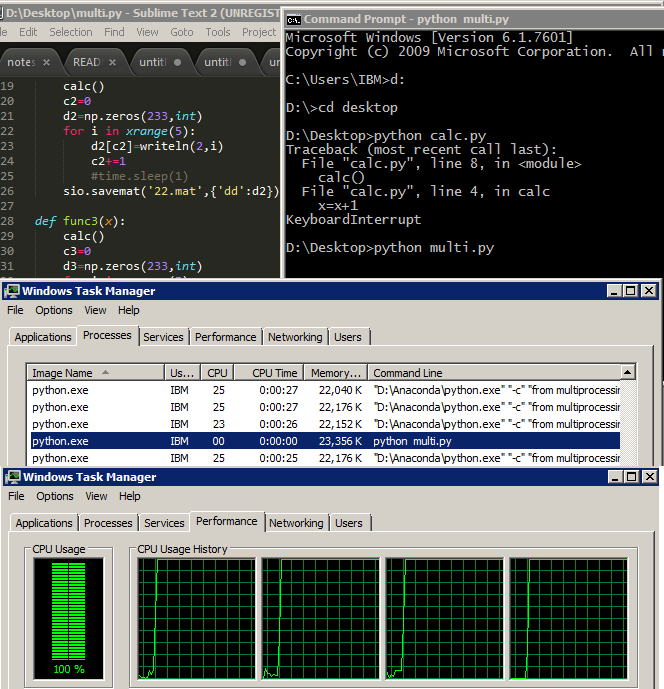
因为并行运行时具有顺序不确定性(参考OS课本上的多线程),用print输出结果可能会乱。这里我们都保存到mat文件里。

有了这种方法我就可以让我的训练数据集的程序也并行跑起来啦~特别爽
Reference:
http://www.coder4.com/archives/3352
http://www.cnblogs.com/kaituorensheng/p/4445418.html
http://rfyiamcool.blog.51cto.com/1030776/1357112
以上是关于用Python实现多核心并行计算的主要内容,如果未能解决你的问题,请参考以下文章
在 Python 多处理进程中运行较慢的 OpenCV 代码片段