数据挖掘概念与技术读书笔记认识数据
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘概念与技术读书笔记认识数据相关的知识,希望对你有一定的参考价值。
2.1 数据对象与属性类型
2.1.1 什么是属性
2.1.2 标称属性:其值是一些符号或事物的名称。每个值代表某种类别、编码或状态,因此标称属性又被看作是分类的。
标称属性不是定量的,找出它的均值或中位数没有意义,有意义的是找到众数,是一种中心趋势度量。
2.1.3 二元属性:是一种标称属性,只有两个类别或状态:0或1,也称布尔属性。
二元属性可以是对称的:关于哪个结果应该用0或1并无偏好。
二元属性可以是非对称的:其状态结果不是同样重要的,如阳性或阴性。为方便计,将用1对重要的结果编码,另一个用0编码。
2.1.4 序数属性:其可能的值之间具有有意义的序或秩评定,但是相继值之间的差是未知的。比如,大、中、小;优、良、中、及格;很不满意、不太满意、中性、满意、很满意。
序数属性的中心趋势可以用它的众数和中位数表示,但不能定义均值。
2.1.5 数值属性:可以是区间标度或比率标度
1.区间标度属性:用相等的单位尺度度量。区间属性的值有序,可以为正、0或负。可以计算中位数和众数,还可以计算均值。
2.比率标度属性:是具有固有零点的数值属性。可以计算差、均值、中位数和众数。
2.1.6 离散属性与连续属性
2.2 数据的基本统计描述
2.2.1 中心趋势度量:均值、中位数和众数
均值:对极端值过于敏感
加权算术均值或加权平均:
截尾均值:丢弃高低极端值后的均值。
中位数:有序数据值的中间值。
众数:
中列数:最大和最小值的平均值
正倾斜:众数出现在小于中位数的值上。
负倾斜:众数出现在大于中位数的值上。
2.2.2 度量数据散布:极差、四分位数、方差、标准差和四分位数极差
1.极差、四分位数和四分位数极差
极差:最大值与最小值之差
分位数:把数据划分成基本大小相等的连贯集合。
四分位数:分成4部分。
百分位数:分成100个大小相等的连贯集。
第一个四分位数:Q1,第25个百分位数
第三个四分位数:Q3,第75个百分位数
四分位数极差IQR:Q3-Q1
2.五数概括、盒图与离群点
识别可疑离群点的通常规则:挑选落在第3个四分位数之上或第1个四分位数之下1.5*IQR处的值。
五数概括:中位数,Q1,Q2,最小和最大值。
3.方差和标准差
低标准差意义数据观测趋向于非常靠近的均值,而高标准差表示数据散布在一个大的值域中。
标准差
方差
2.2.3 数据的基本统计描述的图形显示
1.分位数图
2.分位数-分位数图
3.直方图:
4.散点图:确定两个数值变量之间看上去是否存在联系、模式或趋势的最有效图形方法之一。
2.3 数据可视化
2.4 度量数据的相似性和相异性
2.4.1 数据矩阵与相异性矩阵
2.4.2 标称属性的邻近性度量
不匹配率:d(i,j)=(p-m)/p p是刻画对象的属性总数,m是匹配的数目
相似性:sim(i,j)=1-d(i,j)=m/p
2.4.3 二元属性的邻近性度量
r:i中取1,j中取0的属性数
s:i中取0,j中取1的属性数
q:i,j中都取1的属性数
t:i,j中都取0的属性数
对称的二元相异性:d(i,j)=(r+s)/(q+r+s+t)
非对称的二元相异性:d(i,j)=(r+s)/(q+r+s)
非对称的二元相似性:sim(i,j)=q/(q+r+s)=1-d(i,j),也称为Jaccard系数
2.4.4 数值属性的相异性:闵可夫斯基距离
欧几里得距离:
加权的欧几里得距离:
曼哈顿距离:
它们具有如下数学性质:
非负性:
同一性:对象到自身的距离是0
对称性:距离是一个对称函数
三角不等式:从对象i到对象j的直接距离不会大于途径任何其他对象k的距离。
闵可夫斯基距离:
2.4.5 序数属性的邻近性度量
2.4.6 混合类型属性的相异性
2.4.7 余弦相似性
上确界距离(切比雪夫距离)
习题:R语言版
2.2 假设所分析的数据包括属性age,它在数据元组中的值为13,15,16,16,19,20,20,21,22,22,25,25,25,25,30,33,33,35,35,35,35,36,40,45,46,52,70
a)均值?中位数?
b)众数?
c)中列数?
d)Q1,Q3?
e)五数?
f)盒图?
data<-c(13,15,16,16,19,20,20,21,22,22,25,25,25,25,30,33,33,35,35,35,35,36,40,45,46,52,70) mean(data) median(data) which.max(table(x)) (max(data)+min(data))/2 quantile(data,0.25) quantile(data,0.75) fivenum(data) barplot(table(data))
2.3
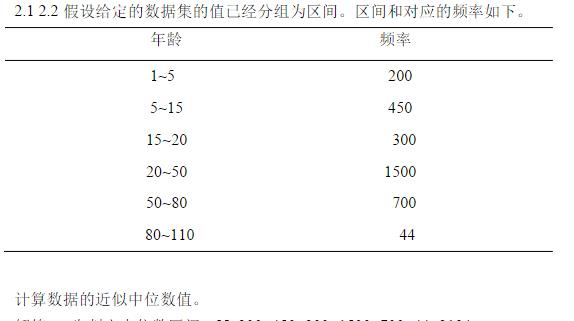
data<-c(200,450,300,1500,700,44) median<-sum(data)/2 sum=0 for(i in 1:length(data)) { sum=sum+data[i] if(sum<median&&sum+data[i+1]>median) break } #出循环后i+1为中位数区间所在下标,即20~50 20+((sum(data)/2+sum)/data[i+1])*30
2.4
age<-c(23,23,27,27,39,41,47,49,50,52,54,54,56,57,58,58,60,61) fat<-c(9.5,26.5,7.8,17.8,31.4,25.9,27.4,27.2,31.2,34.6,42.5,28.8,33.4,30.2,34.1,32.9,41.2,35.7) mean(age) median(age) sd(age) mean(fat) median(fat) sd(fat) barplot(table(age)) barplot(table(fat)) plot(age,fat) qqplot(age,fat)
2.6
v1<-c(22,1,42,10) v2<-c(20,0,36,8) sqrt(sum((v1-v2)^2)) #欧几里德 sum(abs(v1-v2)) #曼哈顿距离 (sum(abs(v1-v2)^3))^(1/3) #闵可夫斯基 max(abs(v1-v2)) #上确界距离
2.8
a)
A1<-c(1.5,2,1.6,1.2,1.5) A2<-c(1.7,1.9,1.8,1.5,1.0) data<-data.frame(A1,A2) x<-c(1.4,1.6) e<-c() m<-c() u<-c() co<-c() for(i in 1:nrow(data)) { e<-c(e,sqrt(sum((x-data[i,])^2))) m<-c(m,sum(abs(x-data[i,]))) u<-c(u,max(abs(x-data[i,]))) co<-c(co,sum(x*data[i,])/(sqrt(sum(x^2))*sqrt(sum(data[i,]^2)))) } rank(e) rank(m) rank(u) rank(co)
以上是关于数据挖掘概念与技术读书笔记认识数据的主要内容,如果未能解决你的问题,请参考以下文章