HDFS概述————Block块大小设置
Posted Mr.Ming2
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS概述————Block块大小设置相关的知识,希望对你有一定的参考价值。
以下内容转自:http://blog.csdn.net/samhacker/article/details/23089157?utm_source=tuicool&utm_medium=referral
http://snglw.blog.51cto.com/5832405/1643587
小文件BLOCK占用
【小于块大小的小文件不会占用整个HDFS块空间。也就是说,较多的小文件会占用更多的NAMENODE的内存(记录了文件的位置等信息);再者,在文件处理时,可能会有较大的网络开销。】
一个常被问到的一个问题是: 如果一个HDFS上的文件大小(file size) 小于块大小(block size) ,那么HDFS会实际占用Linux file system的多大空间?
答案是实际的文件大小,而非一个块的大小。
1、往hdfs里面添加新文件前,hadoop在linux上面所占的空间为 464 MB:

2、往hdfs里面添加大小为2673375 byte(大概2.5 MB)的文件:
2673375 derby.jar
3、此时,hadoop在linux上面所占的空间为 467 MB—— 增加了一个实际文件大小(2.5 MB)的空间,而非一个block size(128 MB) :

4、使用hadoop dfs -stat查看文件信息:

这里就很清楚地反映出: 文件的实际大小(file size)是2673375 byte, 但它的block size是128 MB。
5、通过NameNode的web console来查看文件信息:
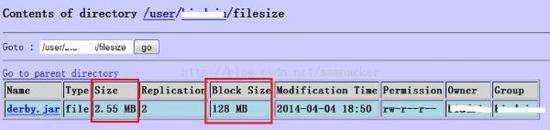
结果是一样的: 文件的实际大小(file size)是2673375 byte, 但它的block size是128 MB。
6、不过使用‘hadoop fsck’查看文件信息,看出了一些不一样的内容—— ‘1(avg.block size 2673375 B)’:
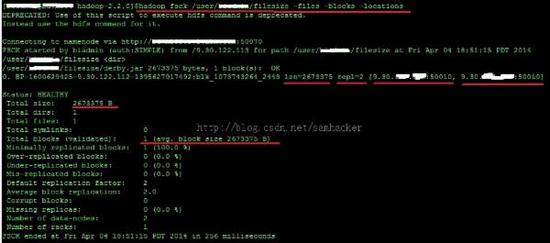
值得注意的是,结果中有一个 ‘1(avg.block size 2673375 B)’的字样。这里的 \'block size\' 并不是指平常说的文件块大小(Block Size)—— 后者是一个元数据的概念,相反它反映的是文件的实际大小(file size)。以下是Hadoop Community的专家给我的回复:
“The fsck is showing you an "average blocksize", not the block size metadata attribute of the file like stat shows. In this specific case, the average is just the length of your file, which is lesser than one whole block.”
最后一个问题是: 如果hdfs占用Linux file system的磁盘空间按实际文件大小算,那么这个”块大小“有必要存在吗?
其实块大小还是必要的,一个显而易见的作用就是当文件通过append操作不断增长的过程中,可以通过来block size决定何时split文件。以下是Hadoop Community的专家给我的回复:
“The block size is a meta attribute. If you append tothe file later, it still needs to know when to split further - so it keeps that value as a mere metadata it can use to advise itself on write boundaries.”
HDFS设置BLOCK的目的
在HDFS里面,data node上的块大小默认是64MB(或者是128MB或256MB)
为什么不能远少于64MB(或128MB或256MB) (普通文件系统的数据块大小一般为4KB)减少硬盘寻道时间(disk seek time)
HDFS设计前提是支持大容量的流式数据操作,所以即使是一般的数据读写操作,涉及到的数据量都是比较大的。假如数据块设置过少,那需要读取的数据块就比较多,
由于数据块在硬盘上非连续存储,普通硬盘因为需要移动磁头,所以随机寻址较慢,读越多的数据块就增大了总的硬盘寻道时间。当硬盘寻道时间比io时间还要长的多时,那么硬盘寻道时间就成了系统的一个瓶颈。合适的块大小有助于减少硬盘寻道时间,提高系统吞吐量。
2.减少Namenode内存消耗
对于HDFS,他只有一个Namenode节点,他的内存相对于Datanode来说,是极其有限的。然而,namenode需要在其内存FSImage文件中中记录在Datanode中的数据块信息,假如数据块大小设置过少,而需要维护的数据块信息就会过多,那Namenode的内存可能就会伤不起了。
为什么不能远大于64MB(或128MB或256MB)?
这里主要从上层的MapReduce框架来讨论
Map崩溃问题:系统需要重新启动,启动过程需要重新加载数据,数据块越大,数据加载时间越长,系统恢复过程越长
监管时间问题:主节点监管其他节点的情况,每个节点会周期性的把完成的工作和状态的更新报告回来。如果一个节点保持沉默超过一个预设的时间间隔,主节点记录下这个节点状态为死亡,并把分配给这个节点的数据发到别的节点。对于这个“预设的时间间隔”,这是从数据块的角度大概估算的。假如是对于64MB的数据块,我可以假设你10分钟之内无论如何也能解决了吧,超过10分钟也没反应,那就是死了。可对于640MB或是1G以上的数据,我应该要估算个多长的时间内?估算的时间短了,那就误判死亡了,分分钟更坏的情况是所有节点都会被判死亡。估算的时间长了,那等待的时间就过长了。所以对于过大的数据块,这个“预设的时间间隔”不好估算。
问题分解问题:数据量大小是问题解决的复杂度是成线性关系的。对于同个算法,处理的数据量越大,它的时间复杂度也就越大。
约束Map输出:在Map Reduce框架里,Map之后的数据是要经过排序才执行Reduce操作的。想想归并排序算法的思想,对小文件进行排序,然后将小文件归并成大文件的思想,然后就会懂这点了
hadoop在文件的split中使用到了一个 变量 是 blocksize,这个值 默认配置 是 64M ,1.0的代码 给的默认值是32M ,这个值我们先不要纠缠 他 到底是多少,因为这个值是可配置的,而且已经给了默认配置64M ,只有我们不配置的时候才会使用32M ,且在官方文档上2.0已经是64M。
那么为什么这个大小是64M ,记得在jvm的一片论文中提到这个大小是64M ,
我们在使用linux的时候,linux系统也有块的大小,我们一般是哟功能的4096 也就是4K ,

- [root@cluster-19 workspace]# du -sk
- 272032 .
- [root@cluster-19 workspace]# vi 1
- [root@cluster-19 workspace]# du -sk
- 272036 .
- [root@cluster-19 workspace]# ls -la 1
- -rw-r--r--. 1 root root 2 8月 27 14:56 1
以上代码可以看到,我们 使用du命令 时 看到 1 这个文件占用了一个 块 的空间,由于一个块的空间是 4096 (4K) 所有我们创建1这个文件之后 我们看到磁盘空间 增加了 4K , 但是我们在使用ls 查看 1 这个文件的时候,我么看到 这里 文件的大小是 2 个字节。
其实我们使用ls 看到的只是文件的meta信息。
那么在hdfs中呢,前边已经说过块的大小是64M ,
我们做个假设 如果 1T 的盘 ,我们上传 小文件到 hdfs ,那么我们是不是只能上传1632个小文件,这个和我们预期远远不相符,hadoop确实是处理大文件有优势,但是也有处理小文件的能力,那就是在shuffle阶段会有合并的,且map的个数和块的数量有关系,如果块很小,那其不是有很多块 也就是很多map了
所以 hdfs中的块,会被充分利用,如果一个文件的大小小于这个块的话那么这个文件 不会占据整个块空间:
hdfs 的块 如此之大 主要还是为 减小寻址开销的 :
一用hadoop权威指南一句话:
- HDFS的块比磁盘块大,其目的是为了最小化寻址开销。如果块设置得足够大,从磁盘传输数据的时间可以明显大于定位这个块开始位置所需的时间。这样,传输一个由多个块组成的文件的时间取决于磁盘传输速率。
- 我们来做一个速算,如果寻址时间为10ms左右,而传输速率为100MB/s,为了使寻址时间仅占传输时间的1%,我们需要设置块大小为100MB左右。而默认的块大小实际为64MB,但是很多情况下HDFS使用128MB的块设置。以后随着新一代磁盘驱动器传输速率的提升,块的大小将被设置得更大。
- 但是该参数也不会设置得过大。MapReduce中的map任务通常一次处理一个块中的数据,因此如果任务数太少(少于集群中的节点数量),作业的运行速度就会比较慢。
我们都知道 ,hdfs 的文件是不允许修改的,目前的hadoop2.0 持支 对一个文件做append操作,那么就遇到另一个问题,
假如现在有一个两个文件 放在同一个block中的话:

如上图,如果原始文件是这样字存在的话 ,那么我如果对File1 做 append操作的花,那么hdfs会怎么处理呢?
我们知道在文件的namenode信息中记录了文件的信息,我们对hadoop做了appdend之后,一个文件只会记录一个文件信息,不可能一个文件记录在多个文件块中,那么 hdfs是会将File1 原来的文件取出来,和我们将要appdend的内容放在一起重新存储文件呢?还是在文件的meta信息中维护了这个文件的两个地址呢?
以上是关于HDFS概述————Block块大小设置的主要内容,如果未能解决你的问题,请参考以下文章