13.solr学习速成之IK分词器
Posted itliucheng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了13.solr学习速成之IK分词器相关的知识,希望对你有一定的参考价值。
IKAnalyzer简介
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。
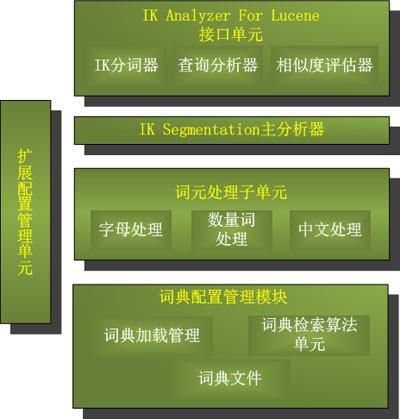
IKAnalyzer特性
a. 算法采用“正向迭代最细粒度切分算法”,支持细粒度和最大词长两种分词方式,速度最大支持80W字/秒(1600KB/秒)。
b. 支持多子处理器分析模式:中文、数字、字母,并兼容日文、韩文。
c. 较小的内存占用,优化词库占有空间,用户可自定义扩展词库。
d. 扩展lucene的扩展实现,采用歧义分析算法优化查询关键字的搜索排列组合,提高lucene检索命中率
IK分词算法理解
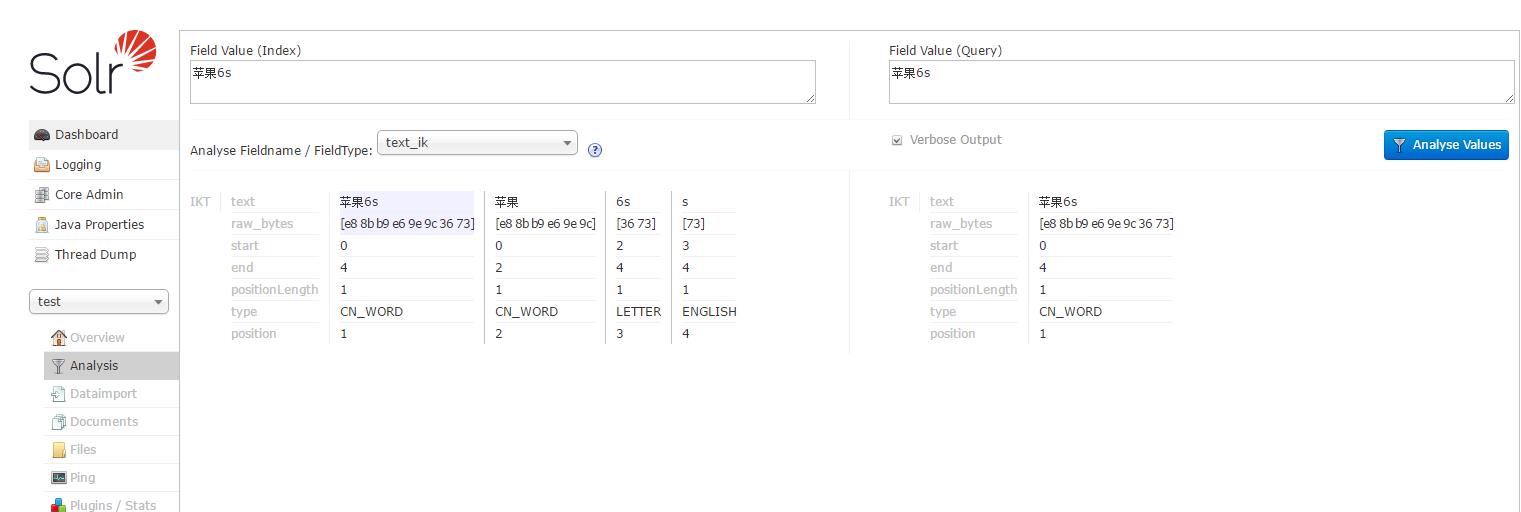
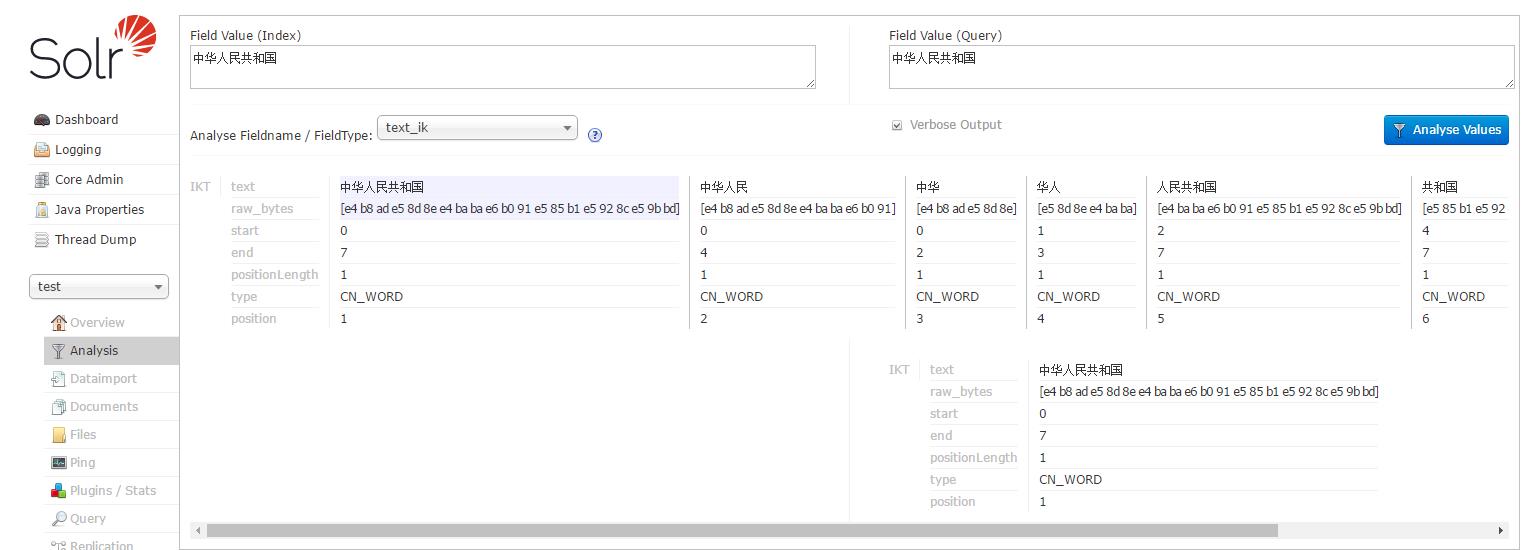
根据作者官方说法IK分词器采用“正向迭代最细粒度切分算法”,分析它的源代码,可以看到分词工具类IKQueryParser起至关重要的作用,它对搜索关键词采用从最大词到最小词层层迭代检索方式切分,比如搜索词:“中华人民共和国成立了”,首先到词库中检索该搜索词中最大分割词,即分割为:“中华人民共和国”和“成立了”,然后对“中华人民共和国”切分为“中华人民”和“人民共和国”,以此类推。最后,“中华人民共和国成立了”切分为:“中华人民 | 中华 | 华人 | 人民 | 人民共和国 | 共和国 | 共和 | 成立 | 立了”,当然,该切分方式为默认的细粒度切分,若按最大词长切分,结果为:“中华人民共和国 | 成立 | 立了”。
其它分词器
目前的分词器有:mmseg4j、paoding、ik-analyzer、imdict、Ansj;目前任在持续更新的有mmseg4j、ik-analyzer和Ansj,这三类分词器都有java的实现,ansj是一个ictclas的java实现,ictclas是中科院计算技术研究所的一个中文分词器,目前用的比较广泛的还是ik-analyzer分词器和mmseg4j 分词器,我们对比下:
mmseg4j :自带sogou词库,支持名为 wordsxxx.dic, utf8文本格式的用户自定义词库,一行一词。不支持自动检测。
ik :支持api级的用户词库加载,和配置级的词库文件指定,无 BOM 的 UTF-8 编码,rn 分割。不支持自动检测。
mmseg4j : 在complex基础上实现了最多分词(max-word),但是还不成熟,还有很多需要改进的地方。
ik :针对Lucene全文检索优化的查询分析器IKQueryParser
IK与solr的集成
1.添加jar
将ik-analyzer-solr5-5.x.jar 放到apache-tomcat-8.5.15/webapps/solr/WEB-INF/lib
2.配置test核下面的schema.xml
<fieldType name="text_ik" class="solr.TextField"> <analyzer type="index"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false"/> </analyzer> <analyzer type="query"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true"/> </analyzer> </fieldType>
有了这个fieldType,我们顺便改一个text_ik的field
<!-- <field name="title" type="text_general" indexed="true" stored="true" multiValued="true"/> --> <field name="title" type="text_ik" indexed="true" stored="true" multiValued="true"/>
3.添加扩展词库
在apache-tomcat-8.5.15/webapps/solr/WEB-INF下创建classes文件夹,添加ext.dic,IKAnalyzer.cfg.xml,stopword.dic文件
也可以添加多个词库文件.IKAnalyzer.cfg.xml的内容如下
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">ext.dic;</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords">stopword.dic;</entry> </properties>
重启tomcat
以上是关于13.solr学习速成之IK分词器的主要内容,如果未能解决你的问题,请参考以下文章