解决数据架构难点数据分布的六种策略
Posted 天之泉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解决数据架构难点数据分布的六种策略相关的知识,希望对你有一定的参考价值。
1.1. 解决数据架构难点数据分布的六种策略
from:PYY
数据分布的六种策略
1) 独立Schema(Separate-schema)
2) 集中(Centralized)
3) 分区(Partitioned)
4) 复制(Replicated)
5) 子集(Subset)
6) 重组(Recorganized)
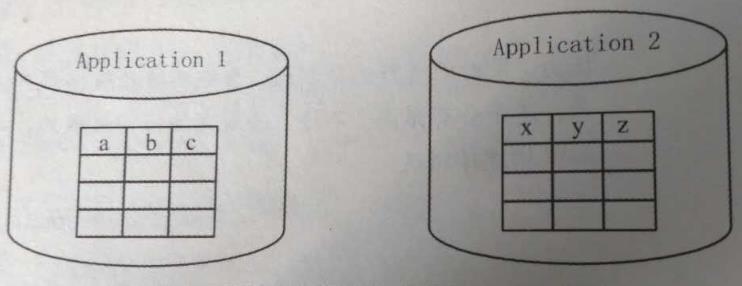
1.1.1. 独立Schema(Separate-schema)
当一个大系统由相关的多个小系统组成,且不同小系统有不相同的数据库Schema定义,这种情况称为“独立Schema”。
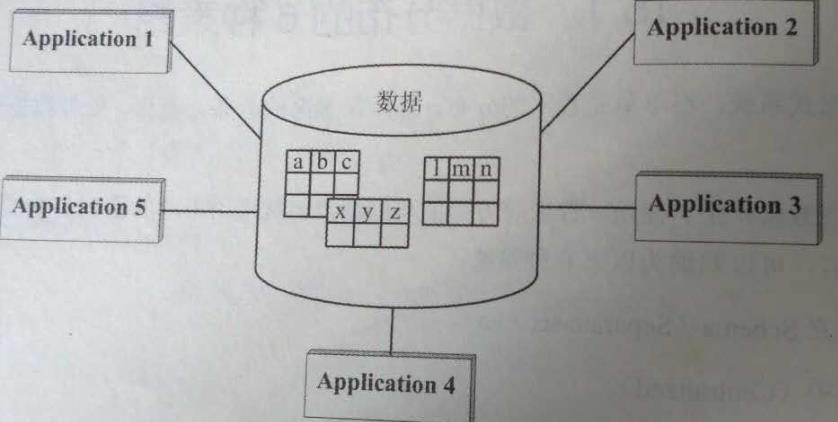
1.1.2. 集中(Centralized)
指一个大系统必须支持来自不同地点的访问,或者该系统由相关的多个小系统组成,而持久集中化数据进行集中化的、统一格式的存储。
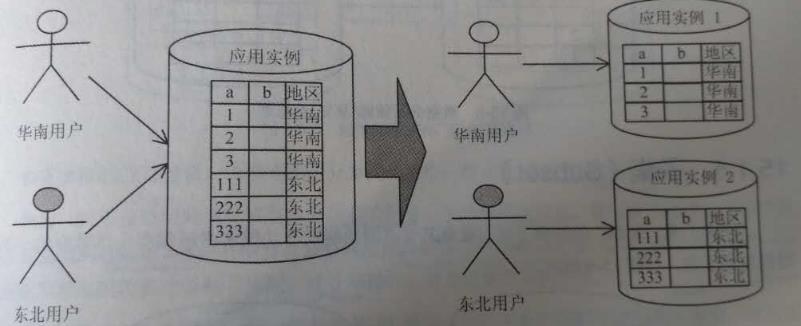
1.1.3. 分区(Partitioned)
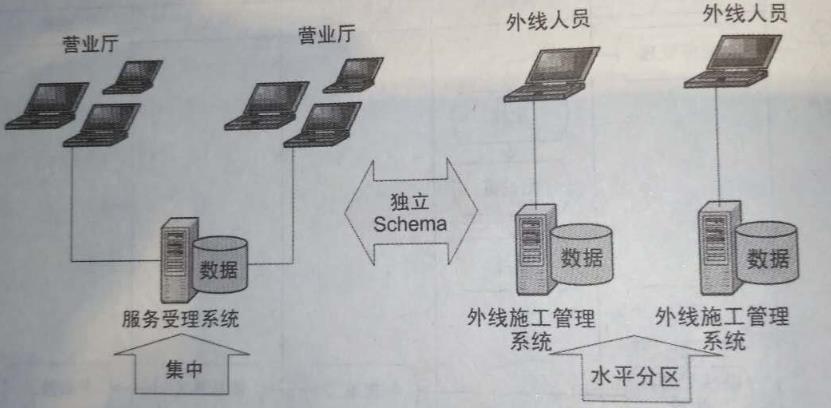
分区方式包括水平分区和垂直分区两种类型,跨“地域”提供“相同的服务”常常采用水平分区,选点“两个相同、两个不同”——相同的应用程序、不同的应用程序部署实例,相同的数据模板,不同的数据值。
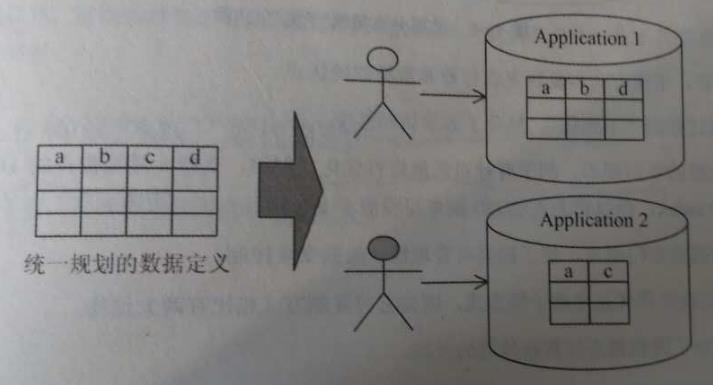
在实践中,水平分区的应用非常广泛,而垂直分区应用要小,特点:不同数据节点的Schema会有“部分字段(Field)”的差异,但可以从同一套总的数据Schema中抽取得到。
1.1.4. 复制(Replicated)两上两个
在整个分布式系统中,数据保存多个副本,并且以某种机制(实时或快照)保持多个数据副本之间的数据一致性。
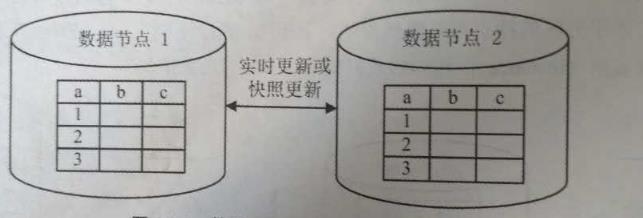
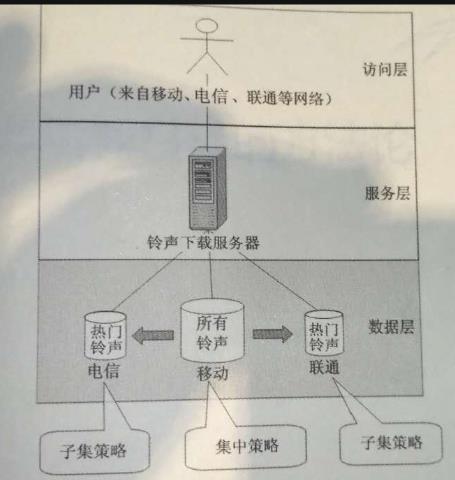
1.1.5. 子集(Subset)
“子集”是“复制”的特殊方式,就是某节点因功能或非功能考虑而保存全体数据的一个相对固定的子集。
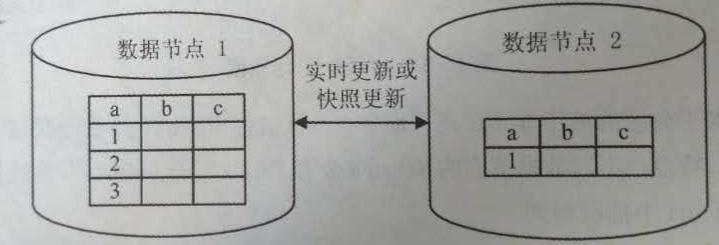
总体而言,子集方式和复制方式有关非常类似的优点:
通过数据“本地化”,提升了数据访问性能。
数据的专门副本,利于优化,便于提高可管理性、安全控制。
1.1.6. 重组(Recorganized)
业务决定功能,功能决定模型。当遇到数据模型不同时,一般都能够从功能差异的角度找到答案。
重组这种数据分布策略,就是不同数据节点因要运行的功能不同,而以不同的Schema保存数据——但本质上这些数据是同源的。于是,重组策略须要进行数据传递,但不是数据的“原样儿”复制,而是以“重新组织”的格式进行传递或保存。
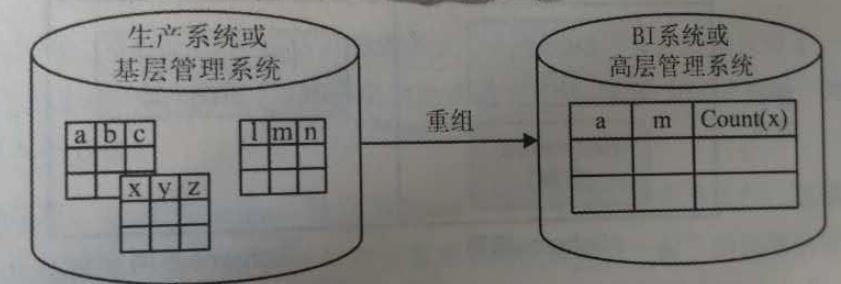
应用:
统计性性重组,例如,如果总公司只须要掌握各分公司的财务、生产等概况信息,那么就不须要把下面的数据原样复制到总公司节点,而是通过分公司应用对信息进行统计后上报。这叫“统计性重组”——数据的重新组织较多地借助了抽取、统计等操作,并形成新的数据格式。
“结构性重组”的例子,最典型的就是BI系统。生产系统的数据被进行整体重组,增加各种利于查询的维度信息,并以新的数据Schema保存供BI应用使用。
1.1.7. 应用的3条原则
1) 把握系统特点,确定分布策略(合适原则)
2) 不同分布策略,可以综合运用(综合原则)
3) 从“对吗”、“好吗”两方面进行评估优化(优化原则)
1.1.8. 示例
1.1.8.1医疗信息化中心
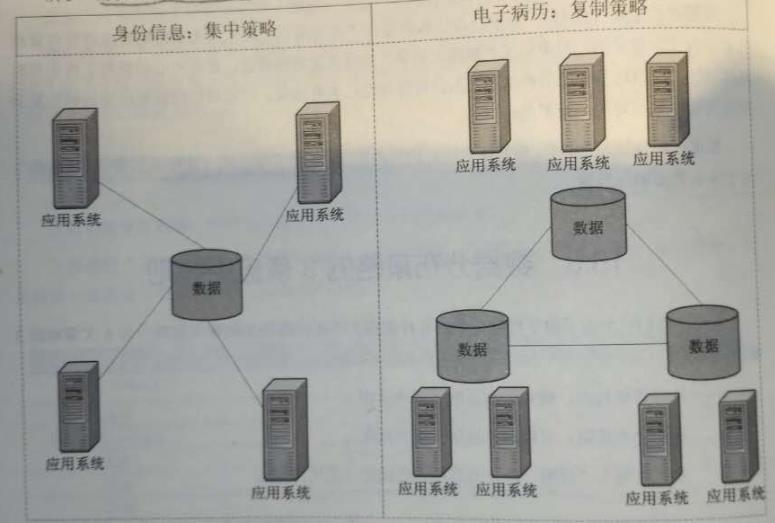
1.1.8.2电信系统
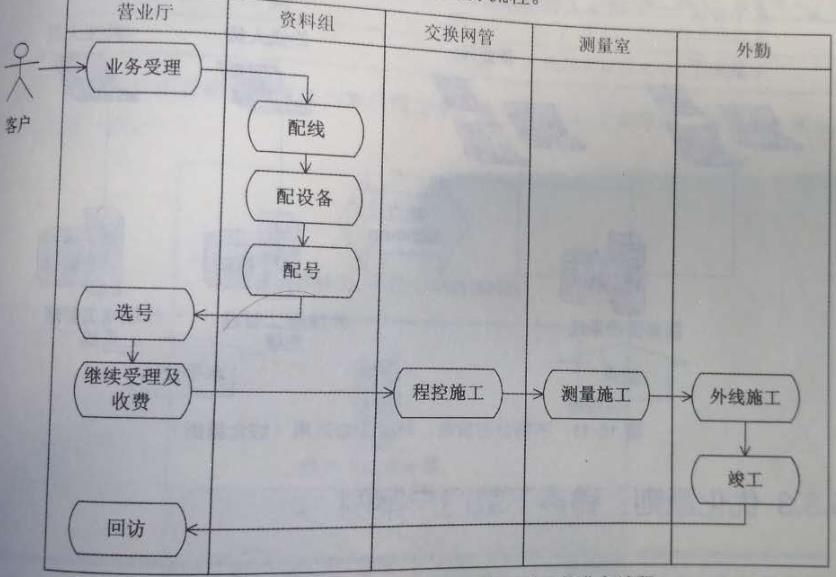
客户申请服务开通业务流程
数据分布策略
1.1.8.3铃声下载

以上是关于解决数据架构难点数据分布的六种策略的主要内容,如果未能解决你的问题,请参考以下文章