Boosting
Posted Vpegasus
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Boosting相关的知识,希望对你有一定的参考价值。
Boosting is a greedy alogrithm. The alogrithm works by applying the weak learner sequentially to weighted version of the data, where more weight is given to examples that were misclassified by earlier rounds. Breiman( 1998) showed that boosting can be interperted as a form of gradient descent in function space. This view was then extended in (Friedman et al. 2000), who showed how boosting could be extended to handle a variety of loss functions , including for regression, robust regression, Poission regression, etc.
1. Forward stagewise additive modeling:
The goal of boosting is to solve the following optimization problem:
\\(\\min_{f} \\sum_{i=1}^N L(y_i, f(x_i))\\)
and \\(L(y,\\hat{y})\\) is some loss function, and f is assumed to be an (adaptive basis function model) ABM.
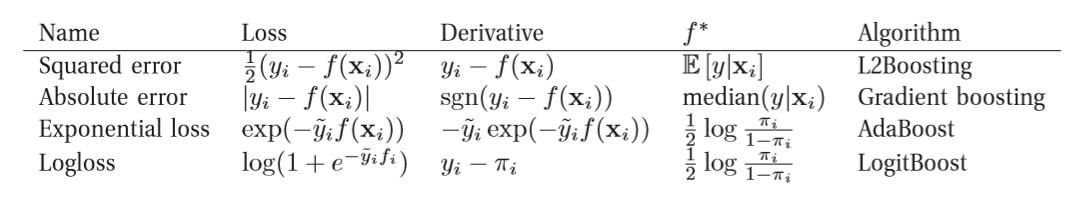
the picture above portries some possible loss function and their corresponding algrithm names.
2. The procedures of forward stagewise algorithm:
Input: training data: \\( T = \\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\\}\\); Loss function \\(L(y,f(x))\\); basis function set: \\(b\\{x;r\\}\\).
Output: addative model: f(x):
(1) Initialize \\(f_0(x)\\).
(2) for m in 1,2,...,M:
(a): minimize loss function:
\\((\\beta_m,r_m) = argmin_{\\beta,r} \\sum_{i = 1}^{N}L(y_i,f_{m-1}(x_i) + \\beta b(x_i;r))\\);
then we got the parameters: \\(\\beta_m,r_m\\).
(b): Update:
\\(f_m(x) = f_{m-1} (x) = \\beta_m b_(x;r_m)\\)
(3) additive model:
\\(f(x) = f_M(x) = \\sum_{m =1}^N \\beta_m b(x;r_m)\\)
Reference:
1. Machine learning a probabilistic perspective 553-563.
2. The elements of statistical learning
3. http://blog.csdn.net/dark_scope/article/details/24863289
以上是关于Boosting的主要内容,如果未能解决你的问题,请参考以下文章