数据结构与算法系列研究八——链地址法建哈希表
Posted 精心出精品
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法系列研究八——链地址法建哈希表相关的知识,希望对你有一定的参考价值。
链地址法建哈希表
一.实验内容
建立n元关键字哈希表,用链地址法解决冲突,输出建立的哈希表。(按链表的顺序),输入任意元素实现查找查找结果分成功和失败,要求查找时可以反复输入关键字查找,直至输入停止标识符时程序结束。
二.输入与输出
输入:可以用随机数法产生n元关键字,然后,产生哈希表,输入要查找的关键字判断是否存在。
输出:输出哈希表,输出查找的结果。
三.关键数据结构和核心算法
关键数据结构:
链式哈希表由一组数组作为“头指针”,每个数组之后都有一个链表,该链表中存着哈希表的插入元素。因此,可以得到数据结构为:


1 typedef struct LNode
2 {
3 ElemType data; //节点的数据域,存放要插入节点
4 struct LNode *next; //链接指针域
5 }*LNODE,LNode;//哈希表的表头后带链表结构
6 typedef struct HashNode
7 {
8 ElemType HashData;//头节点,存放该表头号
9 ElemType count; //存放该表头连接的节点数
10 LNode *first; //链接的第一个指针域
11 }*HN,HashNode;//哈希表的主体结构
核心算法:
1.因为哈希表和图的邻接表创建十分相似,故十分简单,只用把数组元素按插入顺序依次插入即可,只要注意关键字的插入只能才出现一次就可以了。具体程序如下:
1 void CreateHash(HashNode hash[],int a[],int n,int m)
2 {//a[]为要插入的节点组,m为哈希表长度,n为数组长度
3 int i,j;
4 LNode *p,*q;//链表指针
5 int flag=0;//标志是否是第一次出现该关键字
6 for(j=0;j<m;j++)
7 {
8 hash[j].HashData = j%m;//标记表头
9 hash[j].first = 0; //初始化为空
10 hash[j].count = 0; //计数器清零
11 }
12 for(i=0;i<n;i++)
13 {
14 int k;
15 k = a[i]%m; //对a[i]取模
16 flag=0;
17 for(j=0;j<m;j++)
18 {//若模满足待插入条件则插入
19 for(q=hash[j].first;q;q=q->next)
20 {
21 if(q->data==a[i])
22 {
23 flag=1; //若出现过则标记
24 }
25 }//end for
26 if(k==hash[j].HashData&&!flag)
27 {
28 p=(LNode *)malloc(sizeof(LNode));
29 p->data=a[i];
30 if(!hash[j].count)
31 {
32 hash[j].first=p;//头节点链接
33 }
34 else
35 {//找到表尾
36 for(q=hash[j].first;q->next;q=q->next)
37 ;
38 q->next=p;//链接
39 }
40 p->next=NULL;//置空
41 hash[j].count++;//计数器加一
42 }//end if
43 }//end for
44 }//end for
45 }
2.至于查找和输出哈希表就十分简单了,查找到了就输出成功,否则为失败。只要按照hash数组来遍历即可。具体代码如下:
1 //打印哈希表
2 void PrintHash(HashNode hash[],int m)
3 {
4 int i;
5 LNode *p;//操作指针
6 for(i=0;i<m;i++)
7 {
8 printf("链表%d有%d个元素,分别为:",i,hash[i].count);
9 for(p=hash[i].first;p;p=p->next)
10 {
11 printf(" %d ",p->data);//依次输出元素
12 }
13 printf("\\n");//输出下一行
14 }
15 }
16 //查找关键字
17 void SearchKey(HashNode hash[],int m,int key)
18 {
19 int i;
20 int count;
21 int flag=0;//成败标志
22 LNode *p;
23 for(i=0;i<m;i++)
24 {
25 count=0;
26 for(p=hash[i].first;p;p=p->next)
27 {
28 count++;
29 if(p->data==key)
30 {
31 flag=1;//成功置一
32 printf("\\n成功找到!\\n");
33 printf("位于hash[%d]的第%d个位置\\n",i,count);
34 }
35 }
36 }
37 if(!flag)
38 {
39 printf("\\n查找失败!\\n");
40 }
41 }
四.理论与测试
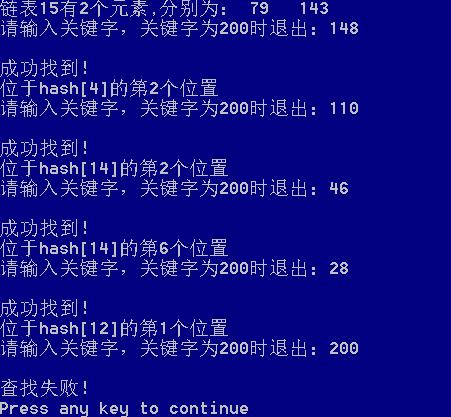
理论:根据哈希表的数据结构,可以构造哈希表,并且可以根据哈希表的结构输出哈希表。
测试:因为采取的是随机数,就省略了输入建表的过程,而查找哈希表的操作及终止条件都已明确。
截图如下:
五、附录(源代码)
1 #include "stdio.h"
2 #include "stdlib.h"
3 #include "time.h" //产生随机数
4 #define MAX_SIZE 100//哈希表表头的最大长度
5 typedef int ElemType;
6 typedef struct LNode
7 {
8 ElemType data; //节点的数据域,存放要插入节点
9 struct LNode *next; //链接指针域
10 }*LNODE,LNode;//哈希表的表头后带链表结构
11 typedef struct HashNode
12 {
13 ElemType HashData;//头节点,存放该表头号
14 ElemType count; //存放该表头连接的节点数
15 LNode *first; //链接的第一个指针域
16 }*HN,HashNode;//哈希表的主体结构
17
18 void CreateHash(HashNode hash[],int a[],int n,int m)
19 {//a[]为要插入的节点组,m为哈希表长度,n为数组长度
20 int i,j;
21 LNode *p,*q;//链表指针
22 int flag=0;//标志是否是第一次出现该关键字
23 for(j=0;j<m;j++)
24 {
25 hash[j].HashData = j%m;//标记表头
26 hash[j].first = 0; //初始化为空
27 hash[j].count = 0; //计数器清零
28 }
29 for(i=0;i<n;i++)
30 {
31 int k;
32 k = a[i]%m; //对a[i]取模
33 flag=0;
34 for(j=0;j<m;j++)
35 {//若模满足待插入条件则插入
36 for(q=hash[j].first;q;q=q->next)
37 {
38 if(q->data==a[i])
39 {
40 flag=1; //若出现过则标记
41 }
42 }//end for
43 if(k==hash[j].HashData&&!flag)
44 {
45 p=(LNode *)malloc(sizeof(LNode));
46 p->data=a[i];
47 if(!hash[j].count)
48 {
49 hash[j].first=p;//头节点链接
50 }
51 else
52 {//找到表尾
53 for(q=hash[j].first;q->next;q=q->next)
54 ;
55 q->next=p;//链接
56 }
57 p->next=NULL;//置空
58 hash[j].count++;//计数器加一
59 }//end if
60 }//end for
61 }//end for
62 }
63 //打印哈希表
64 void PrintHash(HashNode hash[],int m)
65 {
66 int i;
67 LNode *p;//操作指针
68 for(i=0;i<m;i++)
69 {
70 printf("链表%d有%d个元素,分别为:",i,hash[i].count);
71 for(p=hash[i].first;p;p=p->next)
72 {
73 printf(" %d ",p->data);//依次输出元素
74 }
75 printf("\\n");//输出下一行
76 }
77 }
78 //查找关键字
79 void SearchKey(HashNode hash[],int m,int key)
80 {
81 int i;
82 int count;
83 int flag=0;//成败标志
84 LNode *p;
85 for(i=0;i<m;i++)
86 {
87 count=0;
88 for(p=hash[i].first;p;p=p->next)
89 {
90 count++;
91 if(p->data==key)
92 {
93 flag=1;//成功置一
94 printf("\\n成功找到!\\n");
95 printf("位于hash[%d]的第%d个位置\\n",i,count);
96 }
97 }
98 }
99 if(!flag)
100 {
101 printf("\\n查找失败!\\n");
102 }
103 }
104
105 void MainMenu()
106 {
107 int m=16,n=40;
108 int key,i,j;
109 HashNode hash[MAX_SIZE];
110 srand(time(0));
111 int a[100];
112 //随机产生小于200的整数
113 for(i=0;i<n;i++)
114 {
115 a[i]=rand()%200;
116 }
117 //依次输出产生元素
118 printf("产生的关键字数组为:\\n");
119 for(i=0;i<n;i++)
120 {
121 printf("%d ",a[i]);
122 j++;
123 if(j%10==0)
124 {
125 printf("\\n");
126 }
127 }
128 //创建哈希表
129 CreateHash(hash,a,n,m);
130 printf("\\n模为%d的哈希表为:\\n",m);
131 PrintHash(hash,m);//打印哈希表
132 while(1)
133 {
134 printf("请输入关键字,关键字为200时退出:");
135 scanf("%d",&key);
136 SearchKey(hash,m,key);
137 if(key==200)//结束标志,因为200不存在
138 {
139 break;
140 }
141 }
142 }
143 int main()
144 {
145 MainMenu();
146 return 0;
147 }
六、总结
Hash函数是非常重要的一种工具,很多算法都需要用到它来解决一些问题,比如信息安全上的MD5算法,视频文件的字幕识别等等,因为Hash函数具有单向性,所以使用起来非常的方便,可以唯一标识一种东西,非常有用。
以上是关于数据结构与算法系列研究八——链地址法建哈希表的主要内容,如果未能解决你的问题,请参考以下文章