基于pycaffe的网络训练和结果分析(mnist数据集)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于pycaffe的网络训练和结果分析(mnist数据集)相关的知识,希望对你有一定的参考价值。
该工作的主要目的是为了练习运用pycaffe来进行神经网络一站式训练,并从多个角度来分析对应的结果。
目标:
- python的运用训练
- pycaffe的接口熟悉
- 卷积网络(CNN)和全连接网络(DNN)的效果差异性
- 学会从多个角度来分析分类结果
- 哪些图片被分类错误并进行可视化?
- 为什么被分错?
- 每一类是否同等机会被分错?
- 在迭代过程中,每一类的错误几率如何变化?
- 是否开始被正确识别后来又被错误识别了?
测试数据集:mnist
代码:https://github.com/TiBAiL/PycaffeTrain-LeNet
环境:Ubuntu 16.04LTS训练,Windows 7+VS2013分析
关于网络架构,在caffe的训练过程中,会涉及到三种不同类型的prototxt文件,分别用于train、test(validation)以及deploy。这三种文件需要保持网络架构上的统一,方可使得程序正常工作。为了达到这一目的,可以通过程序自动生成对应的文件。这三种文件的主要区别在于输入数据层以及loss/accuracy/prob层。
与此同时,针对solver.prototxt文件,我也采用了python程序的方式进行生成。在求解过程中,为了能够统计train loss/test loss以及accuracy信息以及保存任意时刻的model参数,可以采用pycaffe提供的api接口进行处理。
代码如下:
1 import numpy as np 2 import caffe 3 from caffe import layers as L, params as P, proto, to_proto 4 5 # file path 6 root = ‘/home/your-account/DL-Analysis/‘ 7 train_list = root + ‘mnist/mnist_train_lmdb‘ 8 test_list = root + ‘mnist/mnist_test_lmdb‘ 9 10 train_proto = root + ‘mnist/LeNet/train.prototxt‘ 11 test_proto = root + ‘mnist/LeNet/test.prototxt‘ 12 13 deploy_proto = root + ‘mnist/LeNet/deploy.prototxt‘ 14 15 solver_proto = root + ‘mnist/LeNet/solver.prototxt‘ 16 17 def LeNet(data_list, batch_size, IncludeAccuracy = False, deploy = False): 18 """ 19 LeNet define 20 """ 21 22 if not(deploy): 23 data, label = L.Data(source = data_list, 24 backend = P.Data.LMDB, 25 batch_size = batch_size, 26 ntop = 2, 27 transform_param = dict(scale = 0.00390625)) 28 else: 29 data = L.Input(input_param = {‘shape‘: {‘dim‘: [64, 1, 28, 28]}}) 30 31 conv1 = L.Convolution(data, 32 kernel_size = 5, 33 stride = 1, 34 num_output = 20, 35 pad = 0, 36 weight_filler = dict(type = ‘xavier‘)) 37 38 pool1 = L.Pooling(conv1, 39 pool = P.Pooling.MAX, 40 kernel_size = 2, 41 stride = 2) 42 43 conv2 = L.Convolution(pool1, 44 kernel_size = 5, 45 stride = 1, 46 num_output = 50, 47 pad = 0, 48 weight_filler = dict(type = ‘xavier‘)) 49 50 pool2 = L.Pooling(conv2, 51 pool = P.Pooling.MAX, 52 kernel_size = 2, 53 stride = 2) 54 55 ip1 = L.InnerProduct(pool2, 56 num_output = 500, 57 weight_filler = dict(type = ‘xavier‘)) 58 59 relu1 = L.ReLU(ip1, 60 in_place = True) 61 62 ip2 = L.InnerProduct(relu1, 63 num_output = 10, 64 weight_filler = dict(type = ‘xavier‘)) 65 66 #loss = L.SoftmaxWithLoss(ip2, label) 67 68 if ( not(IncludeAccuracy) and not(deploy) ): 69 # train net 70 loss = L.SoftmaxWithLoss(ip2, label) 71 return to_proto(loss) 72 73 elif ( IncludeAccuracy and not(deploy) ): 74 # test net 75 loss = L.SoftmaxWithLoss(ip2, label) 76 Accuracy = L.Accuracy(ip2, label) 77 return to_proto(loss, Accuracy) 78 79 else: 80 # deploy net 81 prob = L.Softmax(ip2) 82 return to_proto(prob) 83 84 def WriteNet(): 85 """ 86 write proto to file 87 """ 88 89 # train net 90 with open(train_proto, ‘w‘) as file: 91 file.write( str(LeNet(train_list, 64, IncludeAccuracy = False, deploy = False)) ) 92 93 # test net 94 with open(test_proto, ‘w‘) as file: 95 file.write( str(LeNet(test_list, 100, IncludeAccuracy = True, deploy = False)) ) 96 97 # deploy net 98 with open(deploy_proto, ‘w‘) as file: 99 file.write( str(LeNet(‘not need‘, 64, IncludeAccuracy = False, deploy = True)) ) 100 101 def GenerateSolver(solver_file, train_net, test_net): 102 """ 103 generate the solver file 104 """ 105 106 s = proto.caffe_pb2.SolverParameter() 107 s.train_net = train_net 108 s.test_net.append(test_net) 109 s.test_interval = 100 110 s.test_iter.append(100) 111 s.max_iter = 10000 112 s.base_lr = 0.01 113 s.momentum = 0.9 114 s.weight_decay = 5e-4 115 s.lr_policy = ‘step‘ 116 s.stepsize = 3000 117 s.gamma = 0.1 118 s.display = 100 119 s.snapshot = 0 120 s.snapshot_prefix = ‘./lenet‘ 121 s.type = ‘SGD‘ 122 s.solver_mode = proto.caffe_pb2.SolverParameter.GPU 123 124 with open(solver_file, ‘w‘) as file: 125 file.write( str(s) ) 126 127 def Training(solver_file): 128 """ 129 training 130 """ 131 132 caffe.set_device(0) 133 caffe.set_mode_gpu() 134 solver = caffe.get_solver(solver_file) 135 #solver.solve() # solve completely 136 137 number_iteration = 10000 138 139 # collect the information 140 display = 100 141 142 # test information 143 test_iteration = 100 144 test_interval = 100 145 146 # loss and accuracy information 147 train_loss = np.zeros( np.ceil(number_iteration * 1.0 / display) ) 148 test_loss = np.zeros( np.ceil(number_iteration * 1.0 / test_interval) ) 149 test_accuracy = np.zeros( np.ceil(number_iteration * 1.0 / test_interval) ) 150 151 # tmp variables 152 _train_loss = 0; _test_loss = 0; _test_accuracy = 0; 153 154 # main loop 155 for iter in range(number_iteration): 156 solver.step(1) 157 158 # save model during training 159 if iter in [10, 30, 60, 100, 300, 600, 1000, 3000, 6000, number_iteration - 1]: 160 string = ‘lenet_iter_%(iter)d.caffemodel‘%{‘iter‘: iter} 161 solver.net.save(string) 162 163 if 0 == iter % display: 164 train_loss[iter // display] = solver.net.blobs[‘SoftmaxWithLoss1‘].data 165 166 ‘‘‘ 167 # accumulate the train loss 168 _train_loss += solver.net.blobs[‘SoftmaxWithLoss1‘].data 169 if 0 == iter % display: 170 train_loss[iter // display] = _train_loss / display 171 _train_loss = 0 172 ‘‘‘ 173 174 if 0 == iter % test_interval: 175 for test_iter in range(test_iteration): 176 solver.test_nets[0].forward() 177 _test_loss += solver.test_nets[0].blobs[‘SoftmaxWithLoss1‘].data 178 _test_accuracy += solver.test_nets[0].blobs[‘Accuracy1‘].data 179 180 test_loss[iter / test_interval] = _test_loss / test_iteration 181 test_accuracy[iter / test_interval] = _test_accuracy / test_iteration 182 _test_loss = 0 183 _test_accuracy = 0 184 185 # save for analysis 186 np.save(‘./train_loss.npy‘, train_loss) 187 np.save(‘./test_loss.npy‘, test_loss) 188 np.save(‘./test_accuracy.npy‘, test_accuracy) 189 190 if __name__ == ‘__main__‘: 191 WriteNet() 192 GenerateSolver(solver_proto, train_proto, test_proto) 193 Training(solver_proto)
利用上述代码训练出来的model进行预测,并对结果进行分析(相关分析代码参见上述链接):
- 利用第10000步(最后一步)时的model进行预测,其分类错误率为0.91%。为了能够直观的观察哪些图片被分类错误,这里我们给出了所有分类错误的图片。在对应标题中,第一个数字为预测值,第二个数字为实际真实值。从中我们可以看到,如红框所示,有许多数字确实是鬼斧神工,人都几乎无法有效区分。

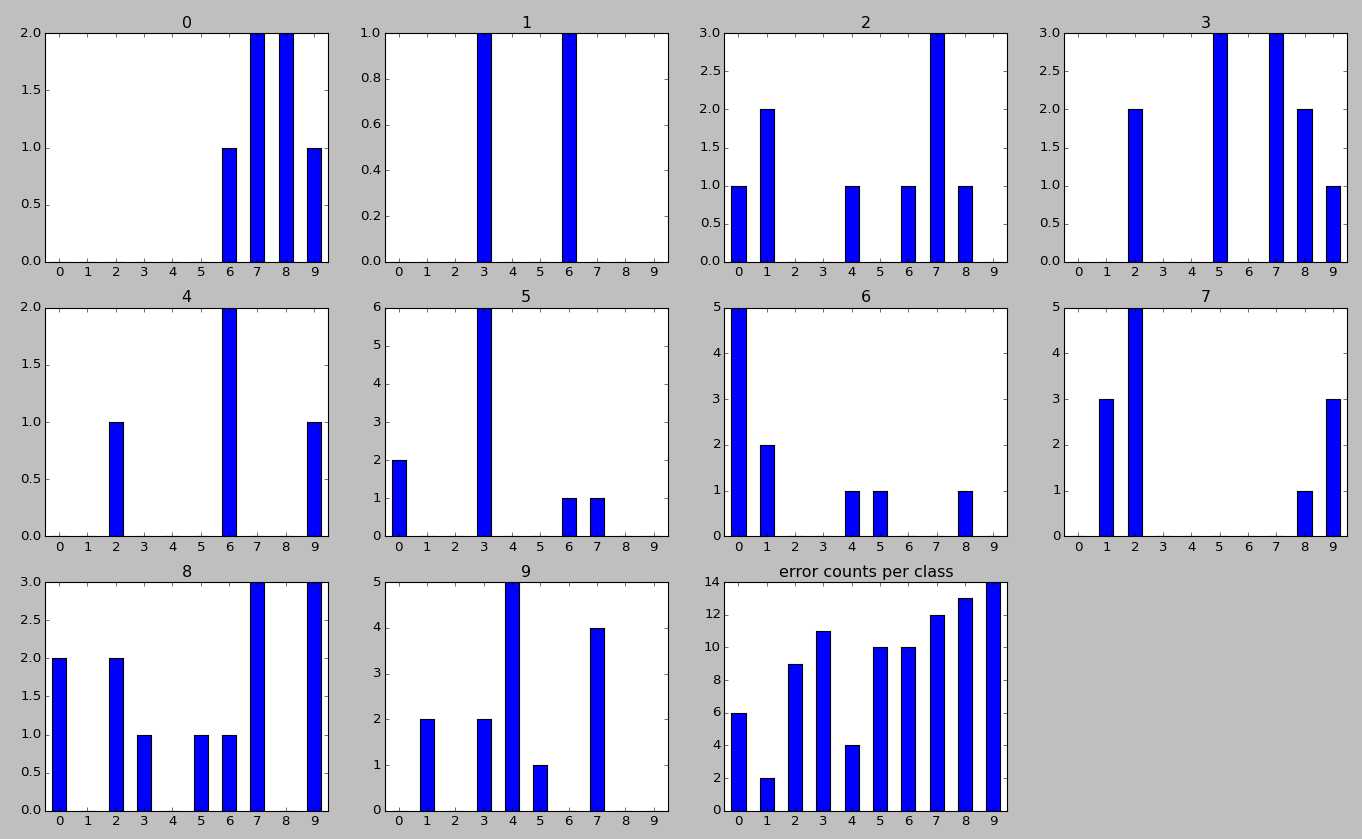
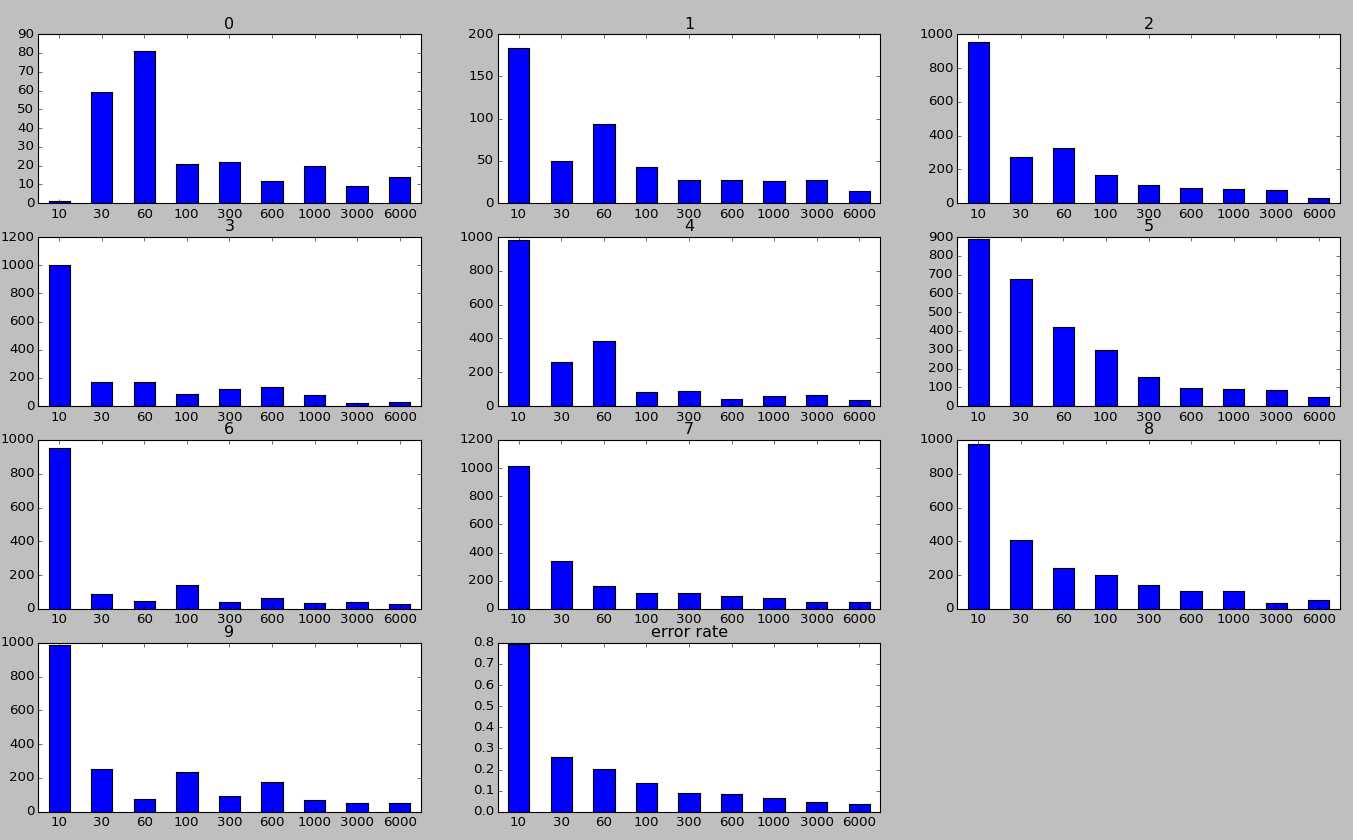
- 现在,我们来看一看,针对每一类,其究竟被分成了哪些数字?这个其实可以从上图看出,这里我给出他们的柱状图,其中子标题表示真实的label,横坐标表示被错误分类的label,纵坐标表示数量,最后一个子图表示在所有的错误分类中,每一类所占的比例。从中可以看出,3/5,4/6,7/2,9/4等较容易混淆,这个也可以非常容易理解。此外,我们也可以发现,数字1最容易分辨,这个可能是因为每个人写1都比较相似,变体较少导致的。
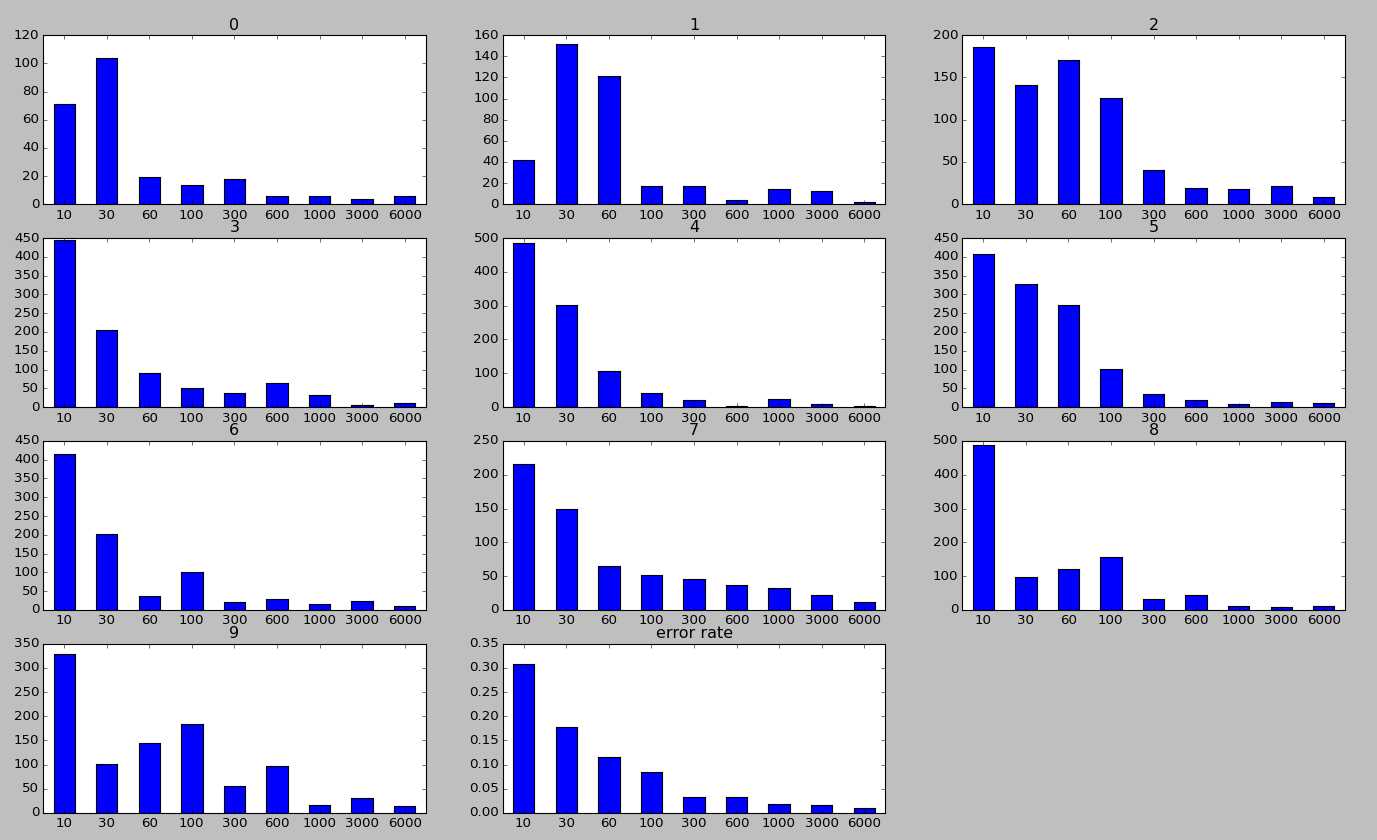
- 接着,让我们来考察一下,在迭代过程中,每个数字的分类准确度是如何变化的。其中,子标题表示真实的label,横坐标表示迭代步数,纵坐标表示分类错误的数量,最后一个子图表示迭代过程中,总的错误率的变化曲线。从该图中,我们可以看出,在迭代过程中,一个图片是有可能先被分类正确后来又被分类错误的(各子曲线并不呈现单调递减的关系),这点也可以从中间变量中进行定量分析看出(代码中有该变量)。
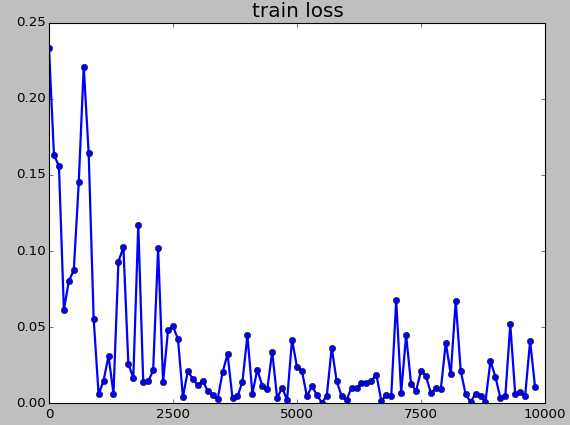
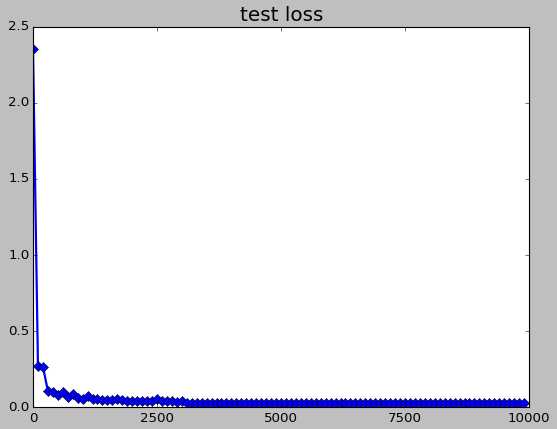
- 关于train loss、test loss以及accuracy的曲线。注意,这里的train loss是某一步的值(因此具有强随机性),而test loss以及accuracy则是100次的平均值(因此较为平滑)
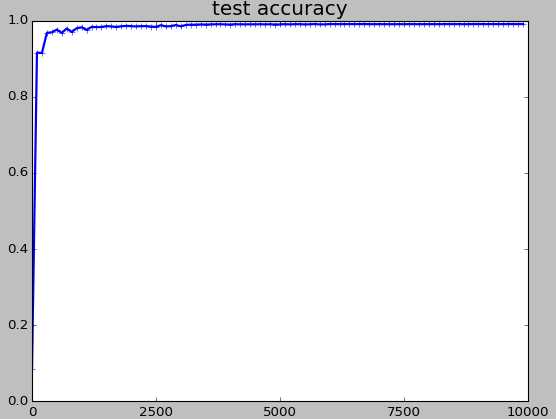
- 最后,让我们来分析一下全连接网络(DNN)的结果。所采用的网络架构为LeNet-300-100。其最终的分类错误率为3.6%。这里我仅给出按比例随机挑选的100张错误图片,以及在迭代过程中每个数字错误率的变换,如下所示。可以看到,DNN网络在第10步时其错误率高达80%左右,而CNN网络在该步时的错误率为30%左右,这其中是否有某种深刻内涵呢?
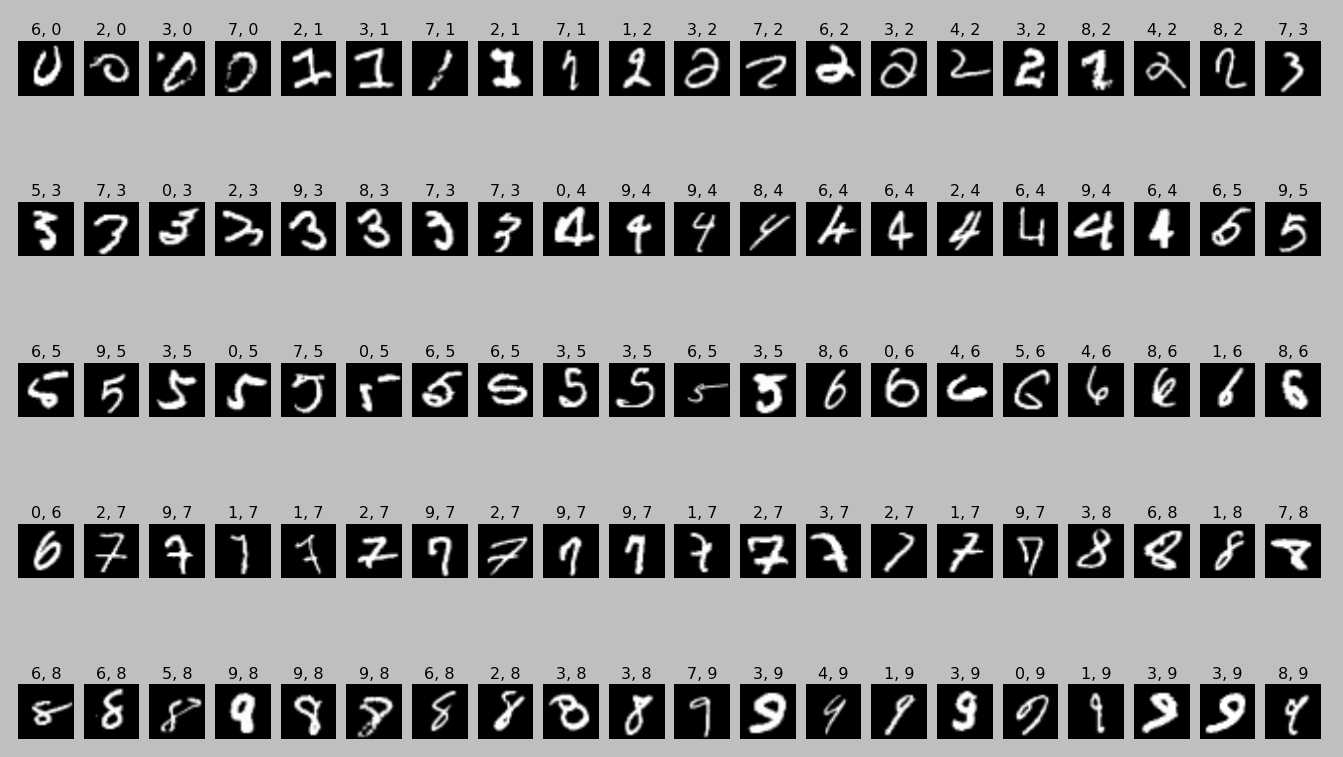
以上是关于基于pycaffe的网络训练和结果分析(mnist数据集)的主要内容,如果未能解决你的问题,请参考以下文章
神经网络听上去高大上?带你从零开始训练一个网络(基于MNIST)
基于pytorch量化感知训练(mnist分类)--浮点训练vs多bit后量化vs多bit量化感知训练效果对比
小白学习PyTorch教程十一基于MNIST数据集训练第一个生成性对抗网络